 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Resolving Domain Bias in GUI Agents through Real-Time Web Video Retrieval and Plug-and-Play Annotation
Mar 27, 2026Large vision-language models have endowed GUI agents with strong general capabilities for interface understanding and interaction. However, due to insufficient exposure to domain-specific software operation data during training, these agents exhibit significant domain bias - they lack familiarity with the specific operation workflows (planning) and UI element layouts (grounding) of particular applications, limiting their real-world task performance. In this paper, we present GUIDE (GUI Unbiasing via Instructional-Video Driven Expertise), a training-free, plug-and-play framework that resolves GUI agent domain bias by autonomously acquiring domain-specific expertise from web tutorial videos through a retrieval-augmented automated annotation pipeline. GUIDE introduces two key innovations. First, a subtitle-driven Video-RAG pipeline unlocks video semantics through subtitle analysis, performing progressive three-stage retrieval - domain classification, topic extraction, and relevance matching - to identify task-relevant tutorial videos. Second, a fully automated annotation pipeline built on an inverse dynamics paradigm feeds consecutive keyframes enhanced with UI element detection into VLMs, inferring the required planning and grounding knowledge that are injected into the agent's corresponding modules to address both manifestations of domain bias. Extensive experiments on OSWorld demonstrate GUIDE's generality as a plug-and-play component for both multi-agent systems and single-model agents. It consistently yields over 5% improvements and reduces execution steps - without modifying any model parameters or architecture - validating GUIDE as an architecture-agnostic enhancement to bridge GUI agent domain bias.
LLM-powered Query Expansion for Enhancing Boundary Prediction in Language-driven Action Localization
May 30, 2025Language-driven action localization in videos requires not only semantic alignment between language query and video segment, but also prediction of action boundaries. However, the language query primarily describes the main content of an action and usually lacks specific details of action start and end boundaries, which increases the subjectivity of manual boundary annotation and leads to boundary uncertainty in training data. In this paper, on one hand, we propose to expand the original query by generating textual descriptions of the action start and end boundaries through LLMs, which can provide more detailed boundary cues for localization and thus reduce the impact of boundary uncertainty. On the other hand, to enhance the tolerance to boundary uncertainty during training, we propose to model probability scores of action boundaries by calculating the semantic similarities between frames and the expanded query as well as the temporal distances between frames and the annotated boundary frames. They can provide more consistent boundary supervision, thus improving the stability of training. Our method is model-agnostic and can be seamlessly and easily integrated into any existing models of language-driven action localization in an off-the-shelf manner. Experimental results on several datasets demonstrate the effectiveness of our method.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
Video Summarization using Denoising Diffusion Probabilistic Model
Dec 12, 2024



Video summarization aims to eliminate visual redundancy while retaining key parts of video to construct concise and comprehensive synopses. Most existing methods use discriminative models to predict the importance scores of video frames. However, these methods are susceptible to annotation inconsistency caused by the inherent subjectivity of different annotators when annotating the same video. In this paper, we introduce a generative framework for video summarization that learns how to generate summaries from a probability distribution perspective, effectively reducing the interference of subjective annotation noise. Specifically, we propose a novel diffusion summarization method based on the Denoising Diffusion Probabilistic Model (DDPM), which learns the probability distribution of training data through noise prediction, and generates summaries by iterative denoising. Our method is more resistant to subjective annotation noise, and is less prone to overfitting the training data than discriminative methods, with strong generalization ability. Moreover, to facilitate training DDPM with limited data, we employ an unsupervised video summarization model to implement the earlier denoising process. Extensive experiments on various datasets (TVSum, SumMe, and FPVSum) demonstrate the effectiveness of our method.
Data-free Multi-label Image Recognition via LLM-powered Prompt Tuning
Mar 02, 2024This paper proposes a novel framework for multi-label image recognition without any training data, called data-free framework, which uses knowledge of pre-trained Large Language Model (LLM) to learn prompts to adapt pretrained Vision-Language Model (VLM) like CLIP to multilabel classification. Through asking LLM by well-designed questions, we acquire comprehensive knowledge about characteristics and contexts of objects, which provides valuable text descriptions for learning prompts. Then we propose a hierarchical prompt learning method by taking the multi-label dependency into consideration, wherein a subset of category-specific prompt tokens are shared when the corresponding objects exhibit similar attributes or are more likely to co-occur. Benefiting from the remarkable alignment between visual and linguistic semantics of CLIP, the hierarchical prompts learned from text descriptions are applied to perform classification of images during inference. Our framework presents a new way to explore the synergies between multiple pre-trained models for novel category recognition. Extensive experiments on three public datasets (MS-COCO, VOC2007, and NUS-WIDE) demonstrate that our method achieves better results than the state-of-the-art methods, especially outperforming the zero-shot multi-label recognition methods by 4.7% in mAP on MS-COCO.
Bootstrap Generalization Ability from Loss Landscape Perspective
Sep 18, 2022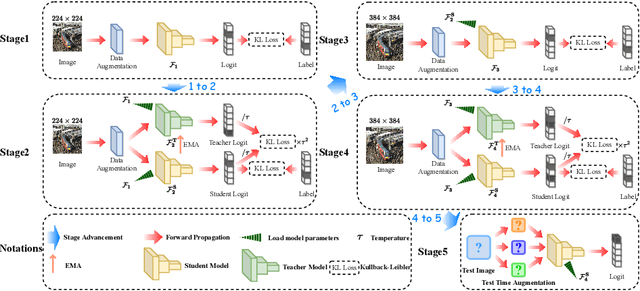

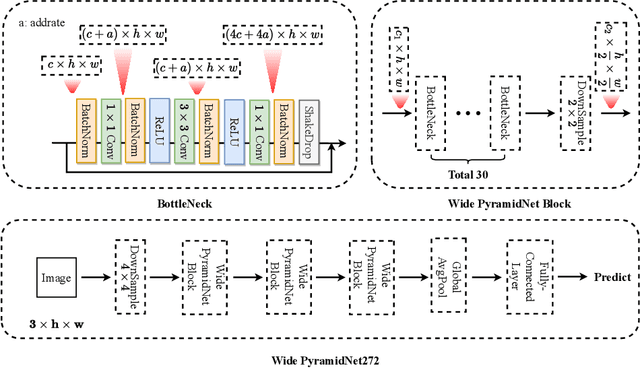
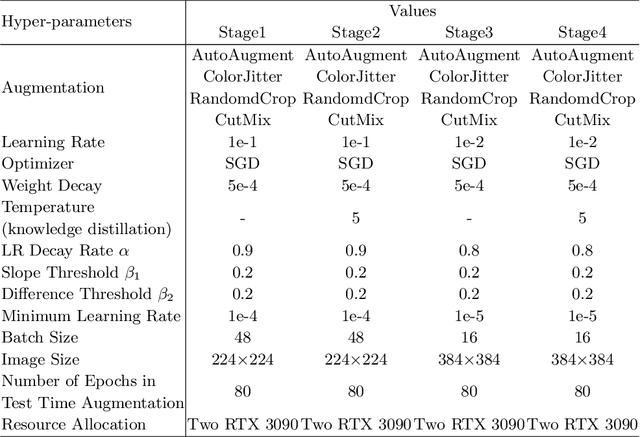
Domain generalization aims to learn a model that can generalize well on the unseen test dataset, i.e., out-of-distribution data, which has different distribution from the training dataset. To address domain generalization in computer vision, we introduce the loss landscape theory into this field. Specifically, we bootstrap the generalization ability of the deep learning model from the loss landscape perspective in four aspects, including backbone, regularization, training paradigm, and learning rate. We verify the proposed theory on the NICO++, PACS, and VLCS datasets by doing extensive ablation studies as well as visualizations. In addition, we apply this theory in the ECCV 2022 NICO Challenge1 and achieve the 3rd place without using any domain invariant methods.