 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: View-Consistent Self-Verified Training for GUI Grounding
Jun 12, 2026When applying Group Relative Policy Optimization (GRPO) for GUI Grounding, rollouts are sampled from a single screenshot view; groups often become either all failures on difficult instances or all successes on easy ones, yielding no useful relative advantage. We propose VISTA (View-Consistent Self-Verified Training), a GRPO-based training framework that constructs each comparison group from multiple target-preserving views of the same GUI instance.Each view is generated by a crop that keeps the target element visible and remaps its box exactly, so model rollouts are compared across semantically equivalent but geometrically different inputs. To stabilize short coordinate generation without turning reinforcement learning into unconditional imitation, VISTA further adds a self-verified cross-view anchor: an oracle answer optimized with an advantage-weighted loss, excluded from the group baseline and activated only when the model has produced a maximum-reward rollout. Across five GUI-grounding benchmarks and multiple Qwen backbones, VISTA consistently improves grounding accuracy.On ScreenSpot-Pro, it raises Qwen3-VL 4B/8B/30B-A3B from 55.5/52.7/53.7 to 63.4/65.8/67.0. Robustness analyses further show higher worst-view accuracy and lower prediction flip rates.
Unified Generation and Self-Verification for Vision-Language Models via Advantage Decoupled Preference Optimization
Jan 04, 2026Parallel test-time scaling typically trains separate generation and verification models, incurring high training and inference costs. We propose Advantage Decoupled Preference Optimization (ADPO), a unified reinforcement learning framework that jointly learns answer generation and self-verification within a single policy. ADPO introduces two innovations: a preference verification reward improving verification capability and a decoupled optimization mechanism enabling synergistic optimization of generation and verification. Specifically, the preference verification reward computes mean verification scores from positive and negative samples as decision thresholds, providing positive feedback when prediction correctness aligns with answer correctness. Meanwhile, the advantage decoupled optimization computes separate advantages for generation and verification, applies token masks to isolate gradients, and combines masked GRPO objectives, preserving generation quality while calibrating verification scores. ADPO achieves up to +34.1% higher verification AUC and -53.5% lower inference time, with significant gains of +2.8%/+1.4% accuracy on MathVista/MMMU, +1.9 cIoU on ReasonSeg, and +1.7%/+1.0% step success rate on AndroidControl/GUI Odyssey.
Multi-Modal Representation Learning with Self-Adaptive Thresholds for Commodity Verification
Aug 24, 2022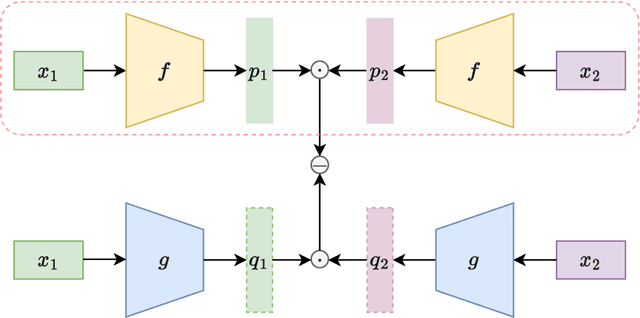
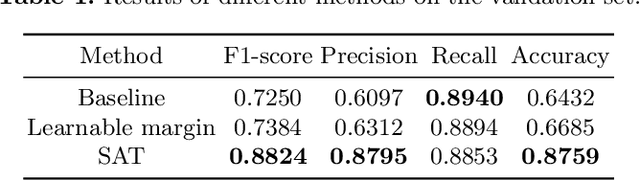
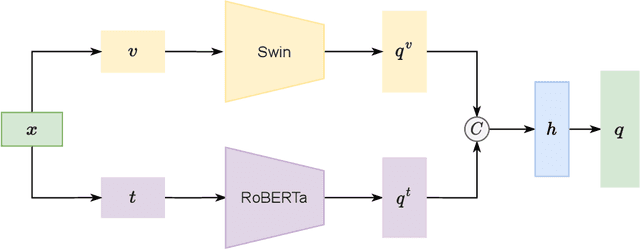
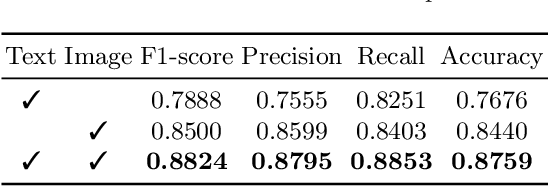
In this paper, we propose a method to identify identical commodities. In e-commerce scenarios, commodities are usually described by both images and text. By definition, identical commodities are those that have identical key attributes and are cognitively identical to consumers. There are two main challenges: 1) The extraction and fusion of multi-modal representation. 2) The ability to verify whether two commodities are identical by comparing the distance between representations with a threshold. To address the above problems, we propose an end-to-end identical commodity verification method based on self-adaptive thresholds. We use a dual-stream network to extract commodity embeddings and threshold embeddings separately and then concatenate them to obtain commodity representation. Our method is able to obtain different thresholds according to different commodities while maintaining the indexability of the entire commodity representation. We experimentally validate the effectiveness of our multimodal feature fusion and the advantages of self-adaptive thresholds. Besides, our method achieves an F1 score of 0.8936 and takes the 3rd place on the leaderboard for the second task of the CCKS-2022 Knowledge Graph Evaluation for Digital Commerce Competition. Code and pretrained models are available at https://github.com/hanchenchen/CCKS2022-track2-solution.
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022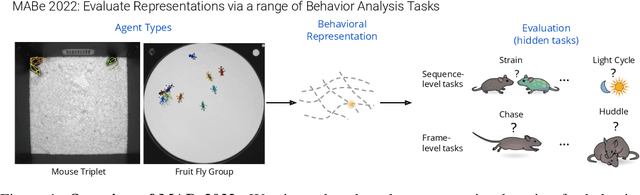
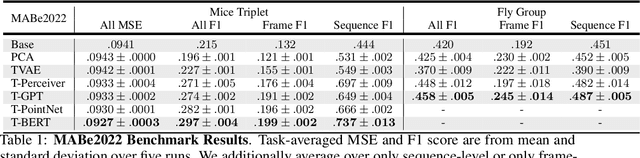
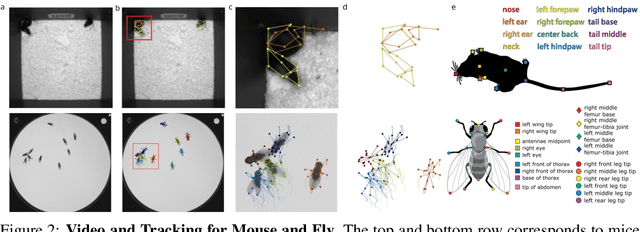
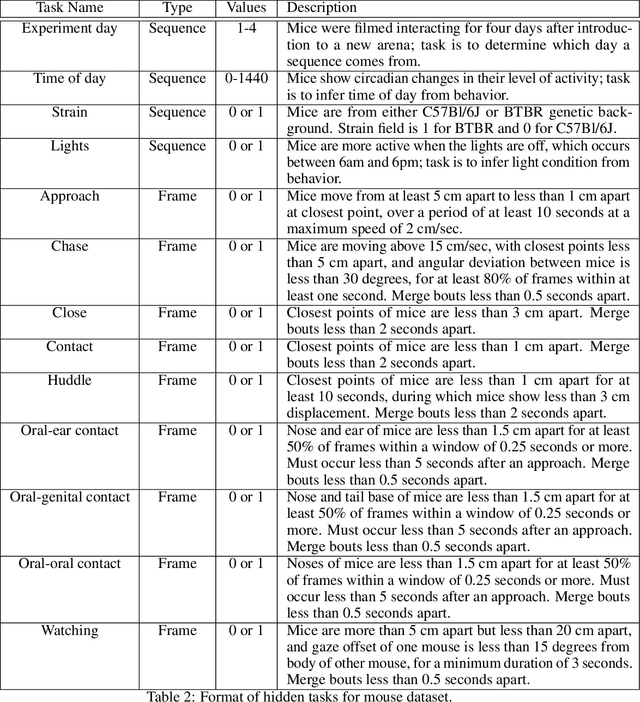
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.