 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhaseCoder: Microphone Geometry-Agnostic Spatial Audio Understanding for Multimodal LLMs
Jan 28, 2026Current multimodal LLMs process audio as a mono stream, ignoring the rich spatial information essential for embodied AI. Existing spatial audio models, conversely, are constrained to fixed microphone geometries, preventing deployment across diverse devices. We present PhaseCoder, a transformer-only spatial audio encoder that is agnostic to microphone geometry. PhaseCoder takes raw multichannel audio and microphone coordinates as inputs to perform localization and produces robust spatial embeddings. We demonstrate that Gemma 3n LLM can be fine-tuned to reason over "Spatial Audio Tokens" produced by PhaseCoder. We show our encoder achieves state-of-the-art results on microphone-invariant localization benchmarks and, for the first time, enables an LLM to perform complex spatial reasoning and targeted transcription tasks from an arbitrary microphone array.
Resonance: Drawing from Memories to Imagine Positive Futures through AI-Augmented Journaling
Mar 31, 2025



People inherently use experiences of their past while imagining their future, a capability that plays a crucial role in mental health. Resonance is an AI-powered journaling tool designed to augment this ability by offering AI-generated, action-oriented suggestions for future activities based on the user's own past memories. Suggestions are offered when a new memory is logged and are followed by a prompt for the user to imagine carrying out the suggestion. In a two-week randomized controlled study (N=55), we found that using Resonance significantly improved mental health outcomes, reducing the users' PHQ8 scores, a measure of current depression, and increasing their daily positive affect, particularly when they would likely act on the suggestion. Notably, the effectiveness of the suggestions was higher when they were personal, novel, and referenced the user's logged memories. Finally, through open-ended feedback, we discuss the factors that encouraged or hindered the use of the tool.
* 17 pages, 13 figures
Conversational AI Powered by Large Language Models Amplifies False Memories in Witness Interviews
Aug 08, 2024This study examines the impact of AI on human false memories -- recollections of events that did not occur or deviate from actual occurrences. It explores false memory induction through suggestive questioning in Human-AI interactions, simulating crime witness interviews. Four conditions were tested: control, survey-based, pre-scripted chatbot, and generative chatbot using a large language model (LLM). Participants (N=200) watched a crime video, then interacted with their assigned AI interviewer or survey, answering questions including five misleading ones. False memories were assessed immediately and after one week. Results show the generative chatbot condition significantly increased false memory formation, inducing over 3 times more immediate false memories than the control and 1.7 times more than the survey method. 36.4% of users' responses to the generative chatbot were misled through the interaction. After one week, the number of false memories induced by generative chatbots remained constant. However, confidence in these false memories remained higher than the control after one week. Moderating factors were explored: users who were less familiar with chatbots but more familiar with AI technology, and more interested in crime investigations, were more susceptible to false memories. These findings highlight the potential risks of using advanced AI in sensitive contexts, like police interviews, emphasizing the need for ethical considerations.
EmpathicStories++: A Multimodal Dataset for Empathy towards Personal Experiences
May 24, 2024



Modeling empathy is a complex endeavor that is rooted in interpersonal and experiential dimensions of human interaction, and remains an open problem within AI. Existing empathy datasets fall short in capturing the richness of empathy responses, often being confined to in-lab or acted scenarios, lacking longitudinal data, and missing self-reported labels. We introduce a new multimodal dataset for empathy during personal experience sharing: the EmpathicStories++ dataset (https://mitmedialab.github.io/empathic-stories-multimodal/) containing 53 hours of video, audio, and text data of 41 participants sharing vulnerable experiences and reading empathically resonant stories with an AI agent. EmpathicStories++ is the first longitudinal dataset on empathy, collected over a month-long deployment of social robots in participants' homes, as participants engage in natural, empathic storytelling interactions with AI agents. We then introduce a novel task of predicting individuals' empathy toward others' stories based on their personal experiences, evaluated in two contexts: participants' own personal shared story context and their reflections on stories they read. We benchmark this task using state-of-the-art models to pave the way for future improvements in contextualized and longitudinal empathy modeling. Our work provides a valuable resource for further research in developing empathetic AI systems and understanding the intricacies of human empathy within genuine, real-world settings.
Uncertainty-Aware Boosted Ensembling in Multi-Modal Settings
Apr 21, 2021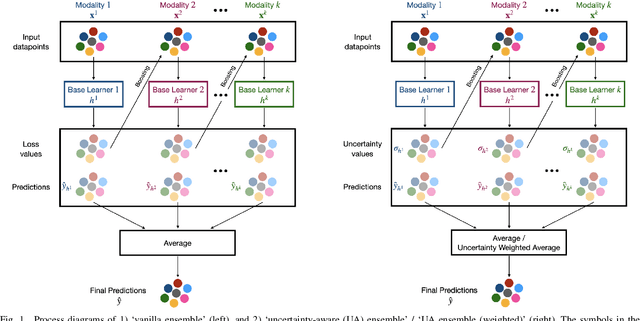
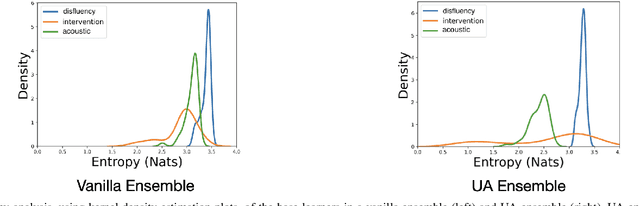
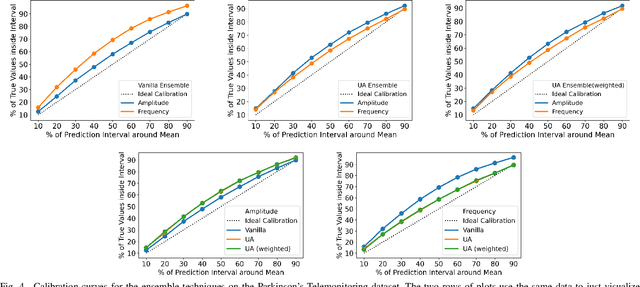

Reliability of machine learning (ML) systems is crucial in safety-critical applications such as healthcare, and uncertainty estimation is a widely researched method to highlight the confidence of ML systems in deployment. Sequential and parallel ensemble techniques have shown improved performance of ML systems in multi-modal settings by leveraging the feature sets together. We propose an uncertainty-aware boosting technique for multi-modal ensembling in order to focus on the data points with higher associated uncertainty estimates, rather than the ones with higher loss values. We evaluate this method on healthcare tasks related to Dementia and Parkinson's disease which involve real-world multi-modal speech and text data, wherein our method shows an improved performance. Additional analysis suggests that introducing uncertainty-awareness into the boosted ensembles decreases the overall entropy of the system, making it more robust to heteroscedasticity in the data, as well as better calibrating each of the modalities along with high quality prediction intervals. We open-source our entire codebase at https://github.com/usarawgi911/Uncertainty-aware-boosting
Robustness to Missing Features using Hierarchical Clustering with Split Neural Networks
Nov 19, 2020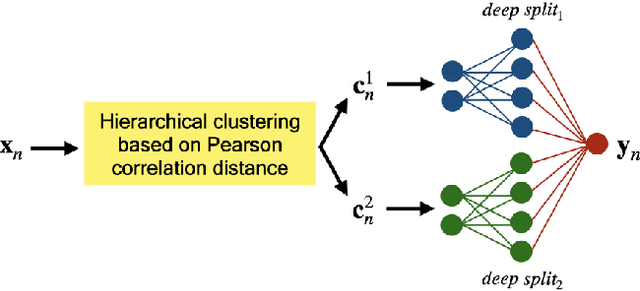
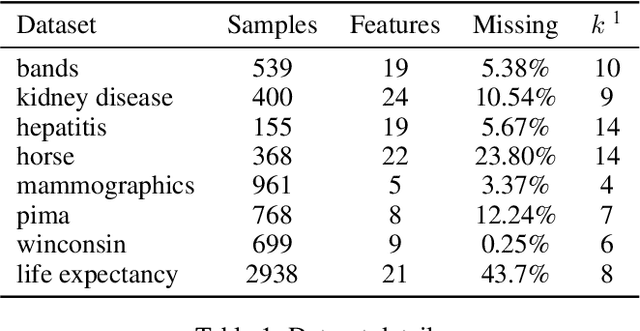
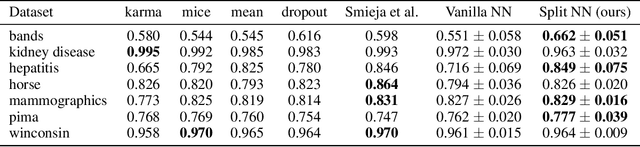
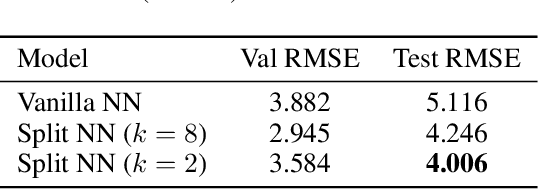
The problem of missing data has been persistent for a long time and poses a major obstacle in machine learning and statistical data analysis. Past works in this field have tried using various data imputation techniques to fill in the missing data, or training neural networks (NNs) with the missing data. In this work, we propose a simple yet effective approach that clusters similar input features together using hierarchical clustering and then trains proportionately split neural networks with a joint loss. We evaluate this approach on a series of benchmark datasets and show promising improvements even with simple imputation techniques. We attribute this to learning through clusters of similar features in our model architecture. The source code is available at https://github.com/usarawgi911/Robustness-to-Missing-Features
Uncertainty-Aware Multi-Modal Ensembling for Severity Prediction of Alzheimer's Dementia
Oct 03, 2020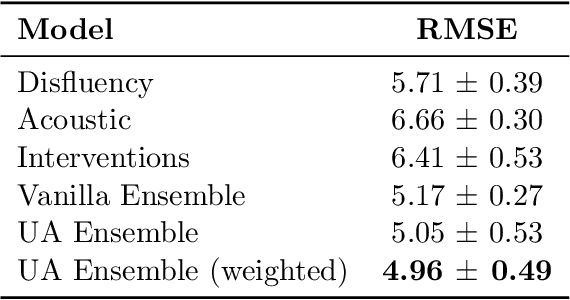
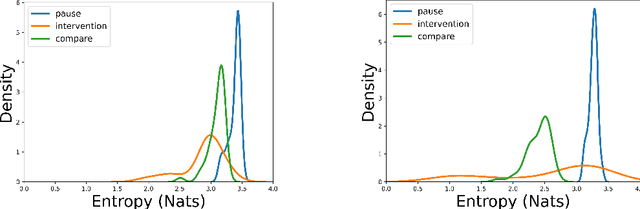
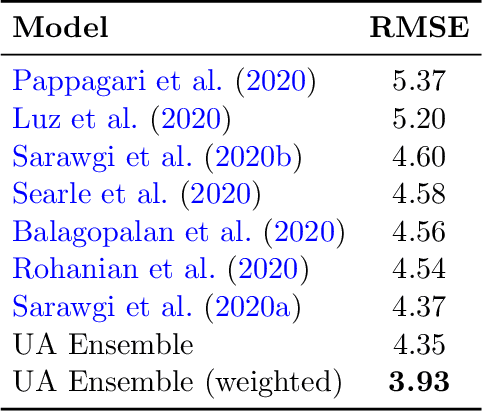
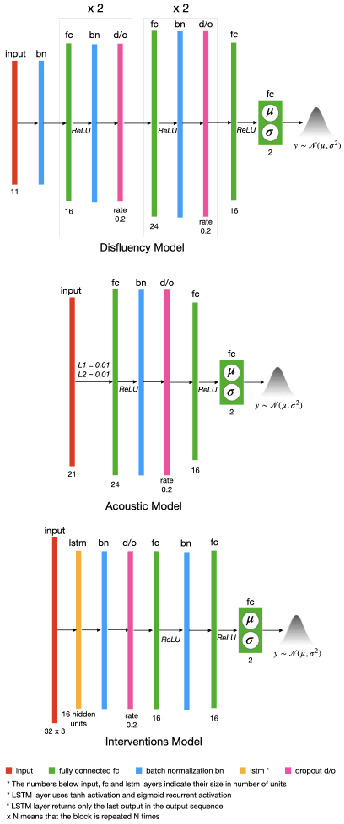
Reliability in Neural Networks (NNs) is crucial in safety-critical applications like healthcare, and uncertainty estimation is a widely researched method to highlight the confidence of NNs in deployment. In this work, we propose an uncertainty-aware boosting technique for multi-modal ensembling to predict Alzheimer's Dementia Severity. The propagation of uncertainty across acoustic, cognitive, and linguistic features produces an ensemble system robust to heteroscedasticity in the data. Weighing the different modalities based on the uncertainty estimates, we experiment on the benchmark ADReSS dataset, a subject-independent and balanced dataset, to show that our method outperforms the state-of-the-art methods while also reducing the overall entropy of the system. This work aims to encourage fair and aware models. The source code is available at https://github.com/wazeerzulfikar/alzheimers-dementia
Why have a Unified Predictive Uncertainty? Disentangling it using Deep Split Ensembles
Sep 25, 2020
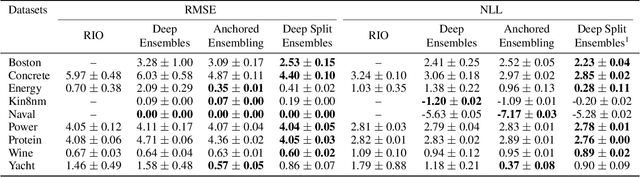
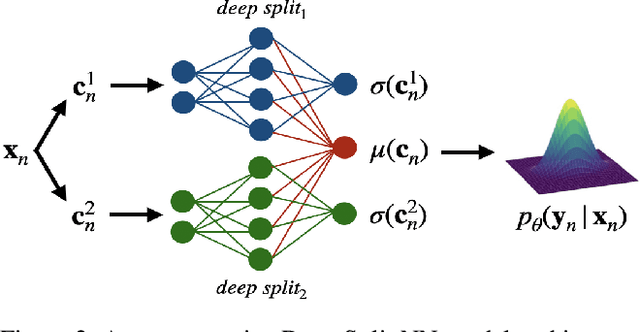
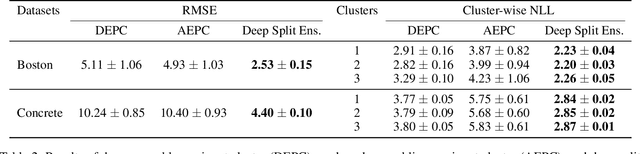
Understanding and quantifying uncertainty in black box Neural Networks (NNs) is critical when deployed in real-world settings such as healthcare. Recent works using Bayesian and non-Bayesian methods have shown how a unified predictive uncertainty can be modelled for NNs. Decomposing this uncertainty to disentangle the granular sources of heteroscedasticity in data provides rich information about its underlying causes. We propose a conceptually simple non-Bayesian approach, deep split ensemble, to disentangle the predictive uncertainties using a multivariate Gaussian mixture model. The NNs are trained with clusters of input features, for uncertainty estimates per cluster. We evaluate our approach on a series of benchmark regression datasets, while also comparing with unified uncertainty methods. Extensive analyses using dataset shits and empirical rule highlight our inherently well-calibrated models. Our work further demonstrates its applicability in a multi-modal setting using a benchmark Alzheimer's dataset and also shows how deep split ensembles can highlight hidden modality-specific biases. The minimal changes required to NNs and the training procedure, and the high flexibility to group features into clusters makes it readily deployable and useful. The source code is available at https://github.com/wazeerzulfikar/deep-split-ensembles
Multimodal Inductive Transfer Learning for Detection of Alzheimer's Dementia and its Severity
Aug 30, 2020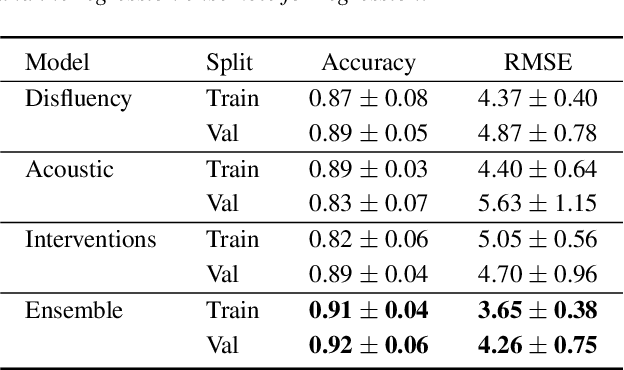
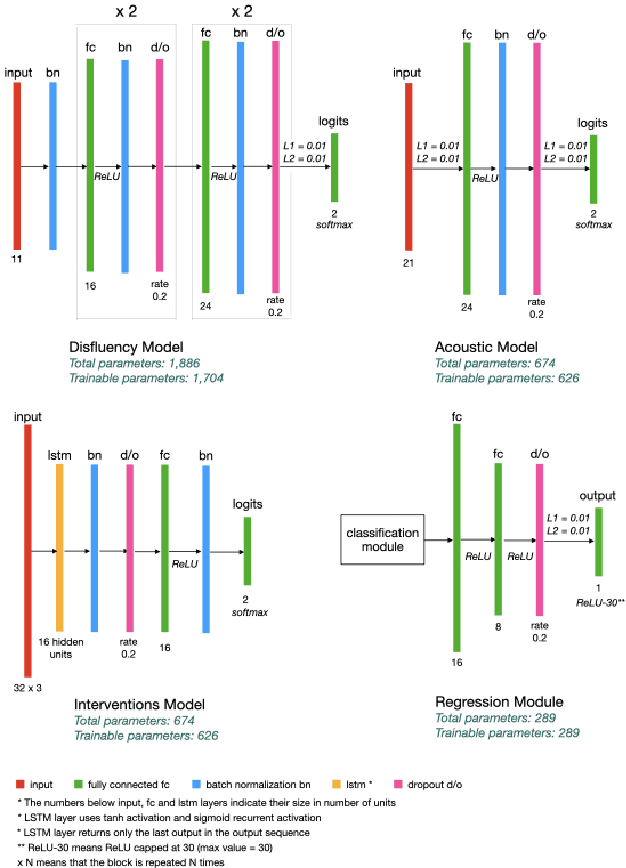
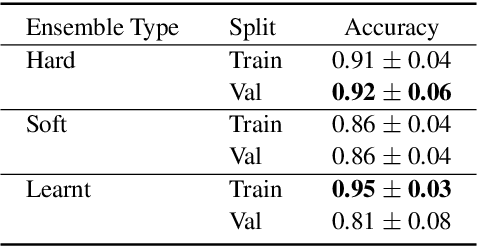
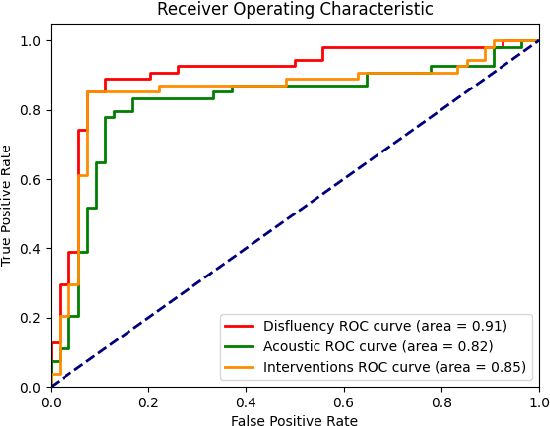
Alzheimer's disease is estimated to affect around 50 million people worldwide and is rising rapidly, with a global economic burden of nearly a trillion dollars. This calls for scalable, cost-effective, and robust methods for detection of Alzheimer's dementia (AD). We present a novel architecture that leverages acoustic, cognitive, and linguistic features to form a multimodal ensemble system. It uses specialized artificial neural networks with temporal characteristics to detect AD and its severity, which is reflected through Mini-Mental State Exam (MMSE) scores. We first evaluate it on the ADReSS challenge dataset, which is a subject-independent and balanced dataset matched for age and gender to mitigate biases, and is available through DementiaBank. Our system achieves state-of-the-art test accuracy, precision, recall, and F1-score of 83.3% each for AD classification, and state-of-the-art test root mean squared error (RMSE) of 4.60 for MMSE score regression. To the best of our knowledge, the system further achieves state-of-the-art AD classification accuracy of 88.0% when evaluated on the full benchmark DementiaBank Pitt database. Our work highlights the applicability and transferability of spontaneous speech to produce a robust inductive transfer learning model, and demonstrates generalizability through a task-agnostic feature-space. The source code is available at https://github.com/wazeerzulfikar/alzheimers-dementia
Towards Task Understanding in Visual Settings
Nov 28, 2018
We consider the problem of understanding real world tasks depicted in visual images. While most existing image captioning methods excel in producing natural language descriptions of visual scenes involving human tasks, there is often the need for an understanding of the exact task being undertaken rather than a literal description of the scene. We leverage insights from real world task understanding systems, and propose a framework composed of convolutional neural networks, and an external hierarchical task ontology to produce task descriptions from input images. Detailed experiments highlight the efficacy of the extracted descriptions, which could potentially find their way in many applications, including image alt text generation.