 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemTREE: Multi-Level Text-Guided Representation End-to-End Learning for Whole Slide Image Analysis
May 28, 2024Multi-modal learning adeptly integrates visual and textual data, but its application to histopathology image and text analysis remains challenging, particularly with large, high-resolution images like gigapixel Whole Slide Images (WSIs). Current methods typically rely on manual region labeling or multi-stage learning to assemble local representations (e.g., patch-level) into global features (e.g., slide-level). However, there is no effective way to integrate multi-scale image representations with text data in a seamless end-to-end process. In this study, we introduce Multi-Level Text-Guided Representation End-to-End Learning (mTREE). This novel text-guided approach effectively captures multi-scale WSI representations by utilizing information from accompanying textual pathology information. mTREE innovatively combines - the localization of key areas (global-to-local) and the development of a WSI-level image-text representation (local-to-global) - into a unified, end-to-end learning framework. In this model, textual information serves a dual purpose: firstly, functioning as an attention map to accurately identify key areas, and secondly, acting as a conduit for integrating textual features into the comprehensive representation of the image. Our study demonstrates the effectiveness of mTREE through quantitative analyses in two image-related tasks: classification and survival prediction, showcasing its remarkable superiority over baselines.
Disruptive Autoencoders: Leveraging Low-level features for 3D Medical Image Pre-training
Jul 31, 2023Harnessing the power of pre-training on large-scale datasets like ImageNet forms a fundamental building block for the progress of representation learning-driven solutions in computer vision. Medical images are inherently different from natural images as they are acquired in the form of many modalities (CT, MR, PET, Ultrasound etc.) and contain granulated information like tissue, lesion, organs etc. These characteristics of medical images require special attention towards learning features representative of local context. In this work, we focus on designing an effective pre-training framework for 3D radiology images. First, we propose a new masking strategy called local masking where the masking is performed across channel embeddings instead of tokens to improve the learning of local feature representations. We combine this with classical low-level perturbations like adding noise and downsampling to further enable low-level representation learning. To this end, we introduce Disruptive Autoencoders, a pre-training framework that attempts to reconstruct the original image from disruptions created by a combination of local masking and low-level perturbations. Additionally, we also devise a cross-modal contrastive loss (CMCL) to accommodate the pre-training of multiple modalities in a single framework. We curate a large-scale dataset to enable pre-training of 3D medical radiology images (MRI and CT). The proposed pre-training framework is tested across multiple downstream tasks and achieves state-of-the-art performance. Notably, our proposed method tops the public test leaderboard of BTCV multi-organ segmentation challenge.
COLosSAL: A Benchmark for Cold-start Active Learning for 3D Medical Image Segmentation
Jul 22, 2023Medical image segmentation is a critical task in medical image analysis. In recent years, deep learning based approaches have shown exceptional performance when trained on a fully-annotated dataset. However, data annotation is often a significant bottleneck, especially for 3D medical images. Active learning (AL) is a promising solution for efficient annotation but requires an initial set of labeled samples to start active selection. When the entire data pool is unlabeled, how do we select the samples to annotate as our initial set? This is also known as the cold-start AL, which permits only one chance to request annotations from experts without access to previously annotated data. Cold-start AL is highly relevant in many practical scenarios but has been under-explored, especially for 3D medical segmentation tasks requiring substantial annotation effort. In this paper, we present a benchmark named COLosSAL by evaluating six cold-start AL strategies on five 3D medical image segmentation tasks from the public Medical Segmentation Decathlon collection. We perform a thorough performance analysis and explore important open questions for cold-start AL, such as the impact of budget on different strategies. Our results show that cold-start AL is still an unsolved problem for 3D segmentation tasks but some important trends have been observed. The code repository, data partitions, and baseline results for the complete benchmark are publicly available at https://github.com/MedICL-VU/COLosSAL.
DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images
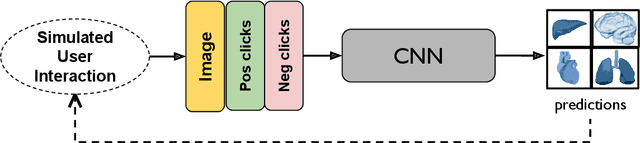
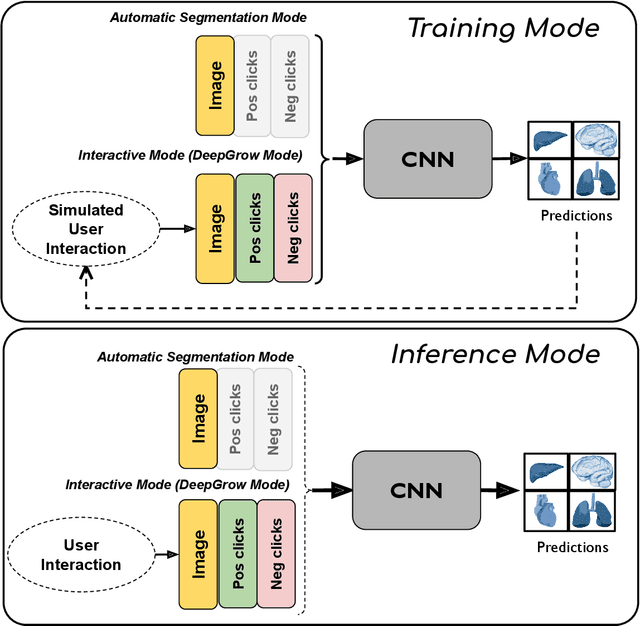
May 18, 2023Automatic segmentation of medical images is a key step for diagnostic and interventional tasks. However, achieving this requires large amounts of annotated volumes, which can be tedious and time-consuming task for expert annotators. In this paper, we introduce DeepEdit, a deep learning-based method for volumetric medical image annotation, that allows automatic and semi-automatic segmentation, and click-based refinement. DeepEdit combines the power of two methods: a non-interactive (i.e. automatic segmentation using nnU-Net, UNET or UNETR) and an interactive segmentation method (i.e. DeepGrow), into a single deep learning model. It allows easy integration of uncertainty-based ranking strategies (i.e. aleatoric and epistemic uncertainty computation) and active learning. We propose and implement a method for training DeepEdit by using standard training combined with user interaction simulation. Once trained, DeepEdit allows clinicians to quickly segment their datasets by using the algorithm in auto segmentation mode or by providing clicks via a user interface (i.e. 3D Slicer, OHIF). We show the value of DeepEdit through evaluation on the PROSTATEx dataset for prostate/prostatic lesions and the Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset for abdominal CT segmentation, using state-of-the-art network architectures as baseline for comparison. DeepEdit could reduce the time and effort annotating 3D medical images compared to DeepGrow alone. Source code is available at https://github.com/Project-MONAI/MONAILabel
Communication-Efficient Vertical Federated Learning with Limited Overlapping Samples
Mar 30, 2023



Federated learning is a popular collaborative learning approach that enables clients to train a global model without sharing their local data. Vertical federated learning (VFL) deals with scenarios in which the data on clients have different feature spaces but share some overlapping samples. Existing VFL approaches suffer from high communication costs and cannot deal efficiently with limited overlapping samples commonly seen in the real world. We propose a practical vertical federated learning (VFL) framework called \textbf{one-shot VFL} that can solve the communication bottleneck and the problem of limited overlapping samples simultaneously based on semi-supervised learning. We also propose \textbf{few-shot VFL} to improve the accuracy further with just one more communication round between the server and the clients. In our proposed framework, the clients only need to communicate with the server once or only a few times. We evaluate the proposed VFL framework on both image and tabular datasets. Our methods can improve the accuracy by more than 46.5\% and reduce the communication cost by more than 330$\times$ compared with state-of-the-art VFL methods when evaluated on CIFAR-10. Our code will be made publicly available at \url{https://nvidia.github.io/NVFlare/research/one-shot-vfl}.
Fair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Warm Start Active Learning with Proxy Labels \& Selection via Semi-Supervised Fine-Tuning
Sep 13, 2022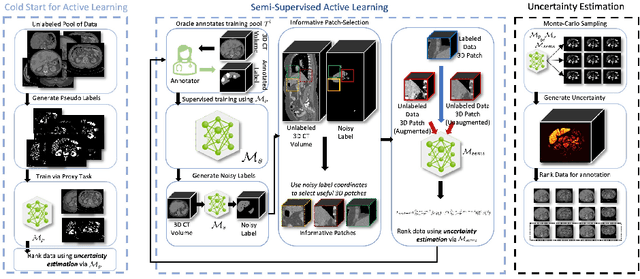
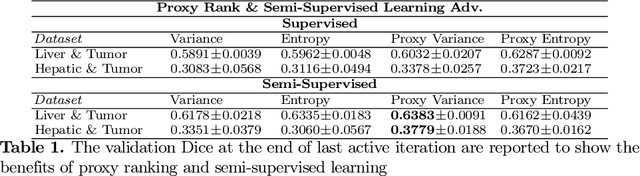
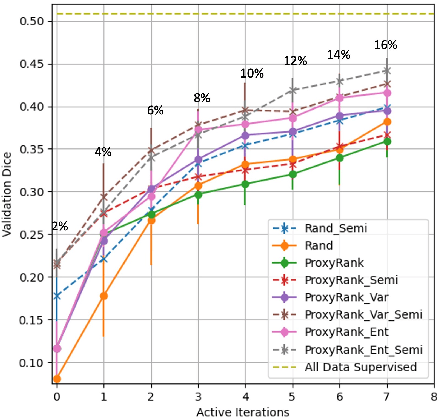
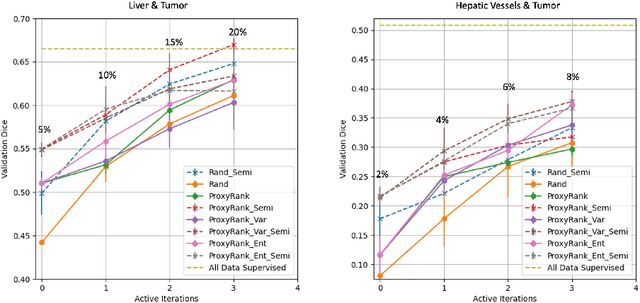
Which volume to annotate next is a challenging problem in building medical imaging datasets for deep learning. One of the promising methods to approach this question is active learning (AL). However, AL has been a hard nut to crack in terms of which AL algorithm and acquisition functions are most useful for which datasets. Also, the problem is exacerbated with which volumes to label first when there is zero labeled data to start with. This is known as the cold start problem in AL. We propose two novel strategies for AL specifically for 3D image segmentation. First, we tackle the cold start problem by proposing a proxy task and then utilizing uncertainty generated from the proxy task to rank the unlabeled data to be annotated. Second, we craft a two-stage learning framework for each active iteration where the unlabeled data is also used in the second stage as a semi-supervised fine-tuning strategy. We show the promise of our approach on two well-known large public datasets from medical segmentation decathlon. The results indicate that the initial selection of data and semi-supervised framework both showed significant improvement for several AL strategies.
MONAI Label: A framework for AI-assisted Interactive Labeling of 3D Medical Images
Mar 23, 2022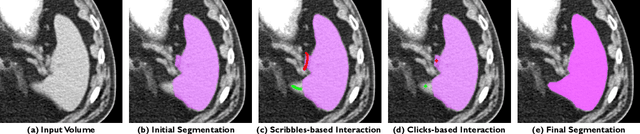
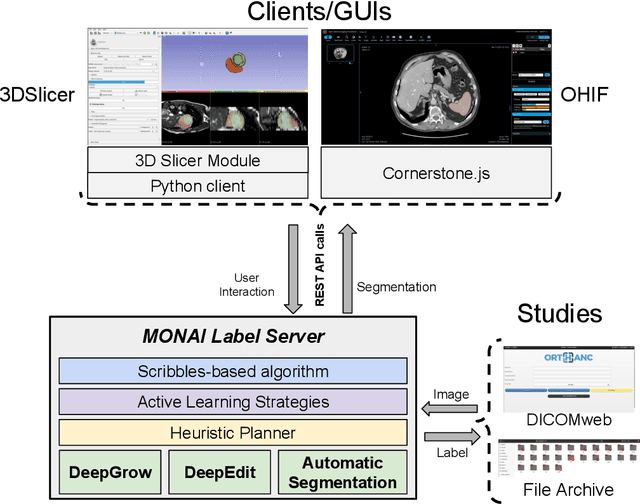
The lack of annotated datasets is a major challenge in training new task-specific supervised AI algorithms as manual annotation is expensive and time-consuming. To address this problem, we present MONAI Label, a free and open-source platform that facilitates the development of AI-based applications that aim at reducing the time required to annotate 3D medical image datasets. Through MONAI Label researchers can develop annotation applications focusing on their domain of expertise. It allows researchers to readily deploy their apps as services, which can be made available to clinicians via their preferred user-interface. Currently, MONAI Label readily supports locally installed (3DSlicer) and web-based (OHIF) frontends, and offers two Active learning strategies to facilitate and speed up the training of segmentation algorithms. MONAI Label allows researchers to make incremental improvements to their labeling apps by making them available to other researchers and clinicians alike. Lastly, MONAI Label provides sample labeling apps, namely DeepEdit and DeepGrow, demonstrating dramatically reduced annotation times.
Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
Jan 04, 2022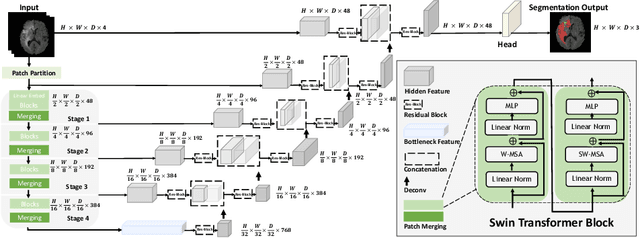

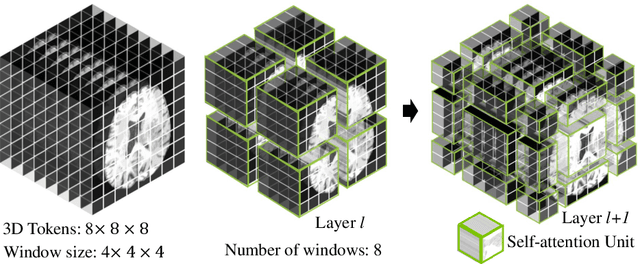
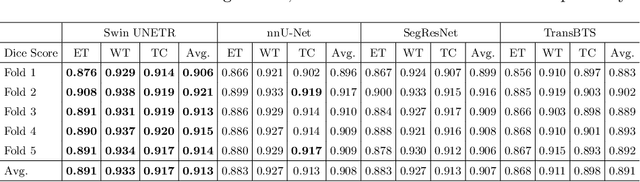
Semantic segmentation of brain tumors is a fundamental medical image analysis task involving multiple MRI imaging modalities that can assist clinicians in diagnosing the patient and successively studying the progression of the malignant entity. In recent years, Fully Convolutional Neural Networks (FCNNs) approaches have become the de facto standard for 3D medical image segmentation. The popular "U-shaped" network architecture has achieved state-of-the-art performance benchmarks on different 2D and 3D semantic segmentation tasks and across various imaging modalities. However, due to the limited kernel size of convolution layers in FCNNs, their performance of modeling long-range information is sub-optimal, and this can lead to deficiencies in the segmentation of tumors with variable sizes. On the other hand, transformer models have demonstrated excellent capabilities in capturing such long-range information in multiple domains, including natural language processing and computer vision. Inspired by the success of vision transformers and their variants, we propose a novel segmentation model termed Swin UNEt TRansformers (Swin UNETR). Specifically, the task of 3D brain tumor semantic segmentation is reformulated as a sequence to sequence prediction problem wherein multi-modal input data is projected into a 1D sequence of embedding and used as an input to a hierarchical Swin transformer as the encoder. The swin transformer encoder extracts features at five different resolutions by utilizing shifted windows for computing self-attention and is connected to an FCNN-based decoder at each resolution via skip connections. We have participated in BraTS 2021 segmentation challenge, and our proposed model ranks among the top-performing approaches in the validation phase. Code: https://monai.io/research/swin-unetr