 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Wise Activation Steering for Honest Language Models
Dec 08, 2025Large language models sometimes assert falsehoods despite internally representing the correct answer, failures of honesty rather than accuracy, which undermines auditability and safety. Existing approaches largely optimize factual correctness or depend on retraining and brittle single-layer edits, offering limited leverage over truthful reporting. We present a training-free activation steering method that weights steering strength across network depth using a Gaussian schedule. On the MASK benchmark, which separates honesty from knowledge, we evaluate seven models spanning the LLaMA, Qwen, and Mistral families and find that Gaussian scheduling improves honesty over no-steering and single-layer baselines in six of seven models. Equal-budget ablations on LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct show the Gaussian schedule outperforms random, uniform, and box-filter depth allocations, indicating that how intervention is distributed across depth materially affects outcomes beyond total strength. The method is simple, model-agnostic, requires no finetuning, and provides a low-cost control knob for eliciting truthful reporting from models' existing capabilities.
Measuring Chain-of-Thought Monitorability Through Faithfulness and Verbosity
Oct 31, 2025Chain-of-thought (CoT) outputs let us read a model's step-by-step reasoning. Since any long, serial reasoning process must pass through this textual trace, the quality of the CoT is a direct window into what the model is thinking. This visibility could help us spot unsafe or misaligned behavior (monitorability), but only if the CoT is transparent about its internal reasoning (faithfulness). Fully measuring faithfulness is difficult, so researchers often focus on examining the CoT in cases where the model changes its answer after adding a cue to the input. This proxy finds some instances of unfaithfulness but loses information when the model maintains its answer, and does not investigate aspects of reasoning not tied to the cue. We extend these results to a more holistic sense of monitorability by introducing verbosity: whether the CoT lists every factor needed to solve the task. We combine faithfulness and verbosity into a single monitorability score that shows how well the CoT serves as the model's external `working memory', a property that many safety schemes based on CoT monitoring depend on. We evaluate instruction-tuned and reasoning models on BBH, GPQA, and MMLU. Our results show that models can appear faithful yet remain hard to monitor when they leave out key factors, and that monitorability differs sharply across model families. We release our evaluation code using the Inspect library to support reproducible future work.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
Jul 31, 2024As artificial intelligence systems grow more powerful, there has been increasing interest in "AI safety" research to address emerging and future risks. However, the field of AI safety remains poorly defined and inconsistently measured, leading to confusion about how researchers can contribute. This lack of clarity is compounded by the unclear relationship between AI safety benchmarks and upstream general capabilities (e.g., general knowledge and reasoning). To address these issues, we conduct a comprehensive meta-analysis of AI safety benchmarks, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety. Our findings reveal that many safety benchmarks highly correlate with upstream model capabilities, potentially enabling "safetywashing" -- where capability improvements are misrepresented as safety advancements. Based on these findings, we propose an empirical foundation for developing more meaningful safety metrics and define AI safety in a machine learning research context as a set of clearly delineated research goals that are empirically separable from generic capabilities advancements. In doing so, we aim to provide a more rigorous framework for AI safety research, advancing the science of safety evaluations and clarifying the path towards measurable progress.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Feb 06, 2024Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess new methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify several desirable properties previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of 18 red teaming methods and 33 target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses. We open source HarmBench at https://github.com/centerforaisafety/HarmBench.
Representation Engineering: A Top-Down Approach to AI Transparency
Oct 10, 2023



In this paper, we identify and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including honesty, harmlessness, power-seeking, and more, demonstrating the promise of top-down transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems.
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Apr 06, 2023



Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities.
How Would The Viewer Feel? Estimating Wellbeing From Video Scenarios
Oct 18, 2022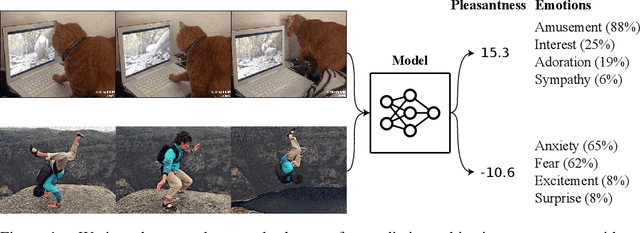


In recent years, deep neural networks have demonstrated increasingly strong abilities to recognize objects and activities in videos. However, as video understanding becomes widely used in real-world applications, a key consideration is developing human-centric systems that understand not only the content of the video but also how it would affect the wellbeing and emotional state of viewers. To facilitate research in this setting, we introduce two large-scale datasets with over 60,000 videos manually annotated for emotional response and subjective wellbeing. The Video Cognitive Empathy (VCE) dataset contains annotations for distributions of fine-grained emotional responses, allowing models to gain a detailed understanding of affective states. The Video to Valence (V2V) dataset contains annotations of relative pleasantness between videos, which enables predicting a continuous spectrum of wellbeing. In experiments, we show how video models that are primarily trained to recognize actions and find contours of objects can be repurposed to understand human preferences and the emotional content of videos. Although there is room for improvement, predicting wellbeing and emotional response is on the horizon for state-of-the-art models. We hope our datasets can help foster further advances at the intersection of commonsense video understanding and human preference learning.
Towards Robustness of Neural Networks
Dec 30, 2021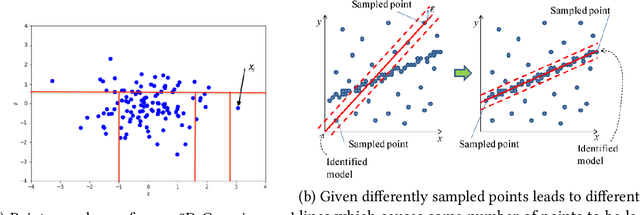
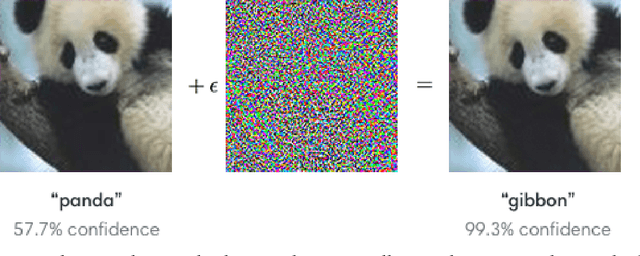


We introduce several new datasets namely ImageNet-A/O and ImageNet-R as well as a synthetic environment and testing suite we called CAOS. ImageNet-A/O allow researchers to focus in on the blind spots remaining in ImageNet. ImageNet-R was specifically created with the intention of tracking robust representation as the representations are no longer simply natural but include artistic, and other renditions. The CAOS suite is built off of CARLA simulator which allows for the inclusion of anomalous objects and can create reproducible synthetic environment and scenes for testing robustness. All of the datasets were created for testing robustness and measuring progress in robustness. The datasets have been used in various other works to measure their own progress in robustness and allowing for tangential progress that does not focus exclusively on natural accuracy. Given these datasets, we created several novel methods that aim to advance robustness research. We build off of simple baselines in the form of Maximum Logit, and Typicality Score as well as create a novel data augmentation method in the form of DeepAugment that improves on the aforementioned benchmarks. Maximum Logit considers the logit values instead of the values after the softmax operation, while a small change produces noticeable improvements. The Typicality Score compares the output distribution to a posterior distribution over classes. We show that this improves performance over the baseline in all but the segmentation task. Speculating that perhaps at the pixel level the semantic information of a pixel is less meaningful than that of class level information. Finally the new augmentation technique of DeepAugment utilizes neural networks to create augmentations on images that are radically different than the traditional geometric and camera based transformations used previously.