 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Reinforcement Learning for Optimizing Mobile Networks
Sep 30, 2021
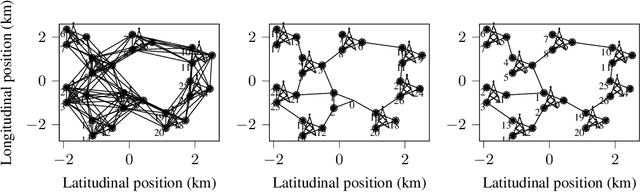
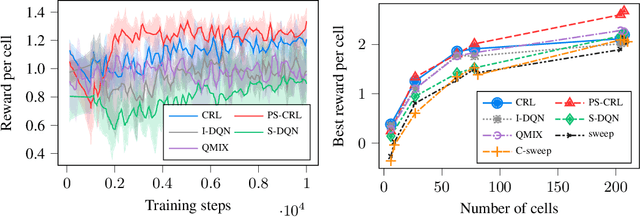
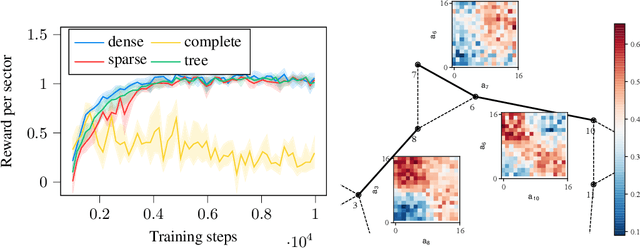
Mobile networks are composed of many base stations and for each of them many parameters must be optimized to provide good services. Automatically and dynamically optimizing all these entities is challenging as they are sensitive to variations in the environment and can affect each other through interferences. Reinforcement learning (RL) algorithms are good candidates to automatically learn base station configuration strategies from incoming data but they are often hard to scale to many agents. In this work, we demonstrate how to use coordination graphs and reinforcement learning in a complex application involving hundreds of cooperating agents. We show how mobile networks can be modeled using coordination graphs and how network optimization problems can be solved efficiently using multi- agent reinforcement learning. The graph structure occurs naturally from expert knowledge about the network and allows to explicitly learn coordinating behaviors between the antennas through edge value functions represented by neural networks. We show empirically that coordinated reinforcement learning outperforms other methods. The use of local RL updates and parameter sharing can handle a large number of agents without sacrificing coordination which makes it well suited to optimize the ever denser networks brought by 5G and beyond.
SimPose: Effectively Learning DensePose and Surface Normals of People from Simulated Data
Jul 30, 2020
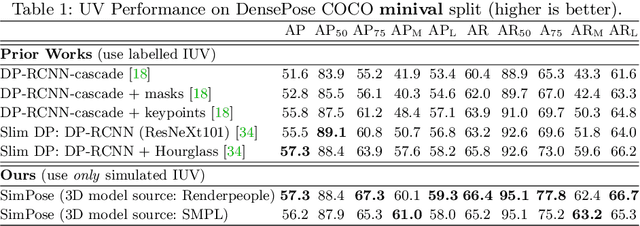
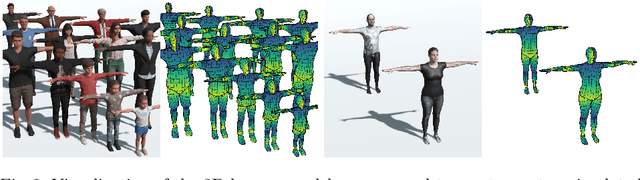
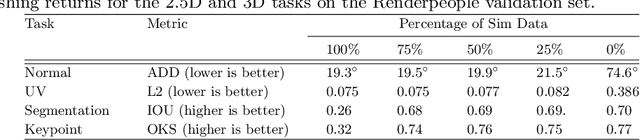
With a proliferation of generic domain-adaptation approaches, we report a simple yet effective technique for learning difficult per-pixel 2.5D and 3D regression representations of articulated people. We obtained strong sim-to-real domain generalization for the 2.5D DensePose estimation task and the 3D human surface normal estimation task. On the multi-person DensePose MSCOCO benchmark, our approach outperforms the state-of-the-art methods which are trained on real images that are densely labelled. This is an important result since obtaining human manifold's intrinsic uv coordinates on real images is time consuming and prone to labeling noise. Additionally, we present our model's 3D surface normal predictions on the MSCOCO dataset that lacks any real 3D surface normal labels. The key to our approach is to mitigate the "Inter-domain Covariate Shift" with a carefully selected training batch from a mixture of domain samples, a deep batch-normalized residual network, and a modified multi-task learning objective. Our approach is complementary to existing domain-adaptation techniques and can be applied to other dense per-pixel pose estimation problems.
Stochastic Prediction of Multi-Agent Interactions from Partial Observations
Feb 25, 2019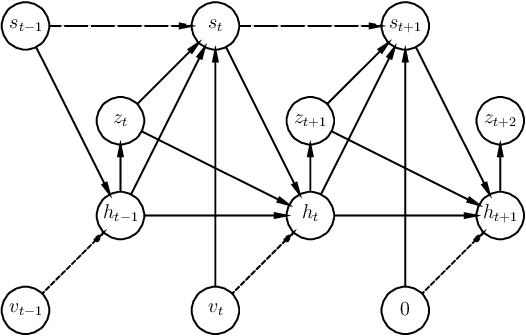
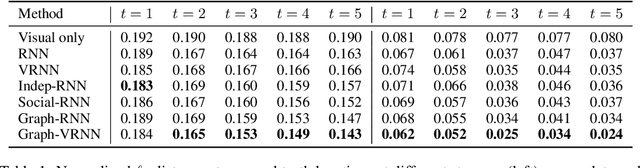
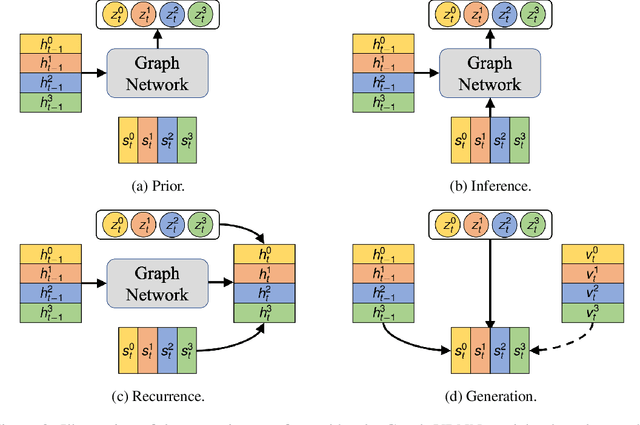
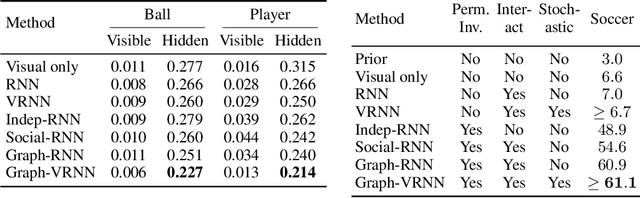
We present a method that learns to integrate temporal information, from a learned dynamics model, with ambiguous visual information, from a learned vision model, in the context of interacting agents. Our method is based on a graph-structured variational recurrent neural network (Graph-VRNN), which is trained end-to-end to infer the current state of the (partially observed) world, as well as to forecast future states. We show that our method outperforms various baselines on two sports datasets, one based on real basketball trajectories, and one generated by a soccer game engine.