 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Adaptive Intra-Network Modulation for Balanced Multimodal Learning
Aug 27, 2025Multimodal learning has significantly enhanced machine learning performance but still faces numerous challenges and limitations. Imbalanced multimodal learning is one of the problems extensively studied in recent works and is typically mitigated by modulating the learning of each modality. However, we find that these methods typically hinder the dominant modality's learning to promote weaker modalities, which affects overall multimodal performance. We analyze the cause of this issue and highlight a commonly overlooked problem: optimization bias within networks. To address this, we propose Adaptive Intra-Network Modulation (AIM) to improve balanced modality learning. AIM accounts for differences in optimization state across parameters and depths within the network during modulation, achieving balanced multimodal learning without hindering either dominant or weak modalities for the first time. Specifically, AIM decouples the dominant modality's under-optimized parameters into Auxiliary Blocks and encourages reliance on these performance-degraded blocks for joint training with weaker modalities. This approach effectively prevents suppression of weaker modalities while enabling targeted optimization of under-optimized parameters to improve the dominant modality. Additionally, AIM assesses modality imbalance level across network depths and adaptively adjusts modulation strength at each depth. Experimental results demonstrate that AIM outperforms state-of-the-art imbalanced modality learning methods across multiple benchmarks and exhibits strong generalizability across different backbones, fusion strategies, and optimizers.
StepWiser: Stepwise Generative Judges for Wiser Reasoning
Aug 27, 2025



As models increasingly leverage multi-step reasoning strategies to solve complex problems, supervising the logical validity of these intermediate steps has become a critical research challenge. Process reward models address this by providing step-by-step feedback, but current approaches have two major drawbacks: they typically function as classifiers without providing explanations, and their reliance on supervised fine-tuning with static datasets limits generalization. Inspired by recent advances, we reframe stepwise reward modeling from a classification task to a reasoning task itself. We thus propose a generative judge that reasons about the policy model's reasoning steps (i.e., meta-reasons), outputting thinking tokens before delivering a final verdict. Our model, StepWiser, is trained by reinforcement learning using relative outcomes of rollouts. We show it provides (i) better judgment accuracy on intermediate steps than existing methods; (ii) can be used to improve the policy model at training time; and (iii) improves inference-time search.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
Q-CLIP: Unleashing the Power of Vision-Language Models for Video Quality Assessment through Unified Cross-Modal Adaptation
Aug 08, 2025Accurate and efficient Video Quality Assessment (VQA) has long been a key research challenge. Current mainstream VQA methods typically improve performance by pretraining on large-scale classification datasets (e.g., ImageNet, Kinetics-400), followed by fine-tuning on VQA datasets. However, this strategy presents two significant challenges: (1) merely transferring semantic knowledge learned from pretraining is insufficient for VQA, as video quality depends on multiple factors (e.g., semantics, distortion, motion, aesthetics); (2) pretraining on large-scale datasets demands enormous computational resources, often dozens or even hundreds of times greater than training directly on VQA datasets. Recently, Vision-Language Models (VLMs) have shown remarkable generalization capabilities across a wide range of visual tasks, and have begun to demonstrate promising potential in quality assessment. In this work, we propose Q-CLIP, the first fully VLMs-based framework for VQA. Q-CLIP enhances both visual and textual representations through a Shared Cross-Modal Adapter (SCMA), which contains only a minimal number of trainable parameters and is the only component that requires training. This design significantly reduces computational cost. In addition, we introduce a set of five learnable quality-level prompts to guide the VLMs in perceiving subtle quality variations, thereby further enhancing the model's sensitivity to video quality. Furthermore, we investigate the impact of different frame sampling strategies on VQA performance, and find that frame-difference-based sampling leads to better generalization performance across datasets. Extensive experiments demonstrate that Q-CLIP exhibits excellent performance on several VQA datasets.
Listwise Preference Alignment Optimization for Tail Item Recommendation
Jul 03, 2025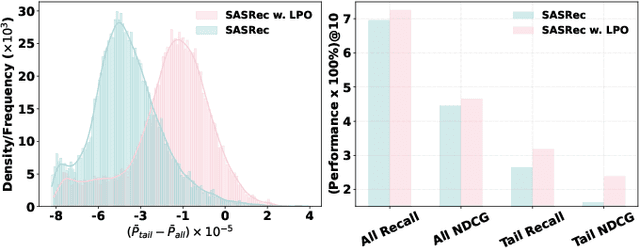
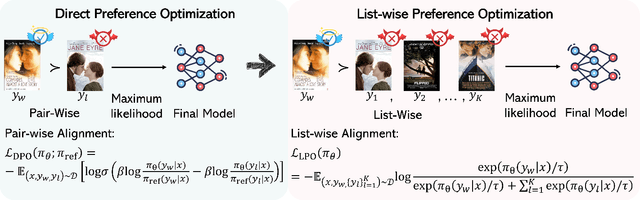
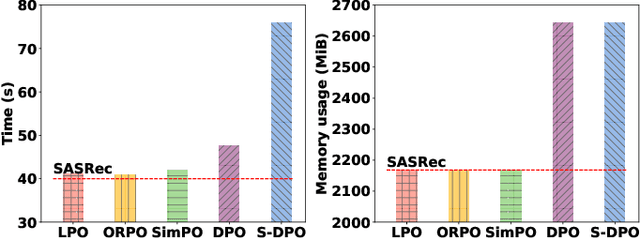
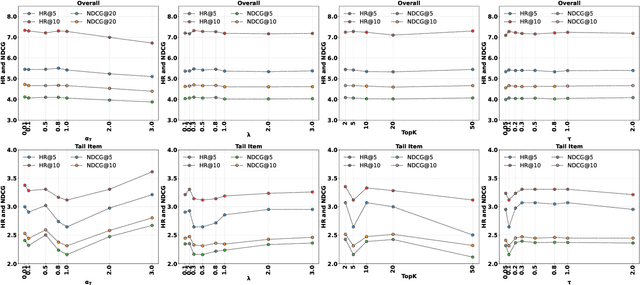
Preference alignment has achieved greater success on Large Language Models (LLMs) and drawn broad interest in recommendation research. Existing preference alignment methods for recommendation either require explicit reward modeling or only support pairwise preference comparison. The former directly increases substantial computational costs, while the latter hinders training efficiency on negative samples. Moreover, no existing effort has explored preference alignment solutions for tail-item recommendation. To bridge the above gaps, we propose LPO4Rec, which extends the Bradley-Terry model from pairwise comparison to listwise comparison, to improve the efficiency of model training. Specifically, we derive a closed form optimal policy to enable more efficient and effective training without explicit reward modeling. We also present an adaptive negative sampling and reweighting strategy to prioritize tail items during optimization and enhance performance in tail-item recommendations. Besides, we theoretically prove that optimizing the listwise preference optimization (LPO) loss is equivalent to maximizing the upper bound of the optimal reward. Our experiments on three public datasets show that our method outperforms 10 baselines by a large margin, achieving up to 50% performance improvement while reducing 17.9% GPU memory usage when compared with direct preference optimization (DPO) in tail-item recommendation. Our code is available at https://github.com/Yuhanleeee/LPO4Rec.
LLM Agent for Hyper-Parameter Optimization
Jun 18, 2025Hyper-parameters are essential and critical for the performance of communication algorithms. However, current hyper-parameters tuning methods for warm-start particles swarm optimization with cross and mutation (WS-PSO-CM) algortihm for radio map-enabled unmanned aerial vehicle (UAV) trajectory and communication are primarily heuristic-based, exhibiting low levels of automation and unsatisfactory performance. In this paper, we design an large language model (LLM) agent for automatic hyper-parameters-tuning, where an iterative framework and model context protocol (MCP) are applied. In particular, the LLM agent is first setup via a profile, which specifies the mission, background, and output format. Then, the LLM agent is driven by the prompt requirement, and iteratively invokes WS-PSO-CM algorithm for exploration. Finally, the LLM agent autonomously terminates the loop and returns a set of hyper-parameters. Our experiment results show that the minimal sum-rate achieved by hyper-parameters generated via our LLM agent is significantly higher than those by both human heuristics and random generation methods. This indicates that an LLM agent with PSO knowledge and WS-PSO-CM algorithm background is useful in finding high-performance hyper-parameters.
Canonical Latent Representations in Conditional Diffusion Models
Jun 11, 2025



Conditional diffusion models (CDMs) have shown impressive performance across a range of generative tasks. Their ability to model the full data distribution has opened new avenues for analysis-by-synthesis in downstream discriminative learning. However, this same modeling capacity causes CDMs to entangle the class-defining features with irrelevant context, posing challenges to extracting robust and interpretable representations. To this end, we identify Canonical LAtent Representations (CLAReps), latent codes whose internal CDM features preserve essential categorical information while discarding non-discriminative signals. When decoded, CLAReps produce representative samples for each class, offering an interpretable and compact summary of the core class semantics with minimal irrelevant details. Exploiting CLAReps, we develop a novel diffusion-based feature-distillation paradigm, CaDistill. While the student has full access to the training set, the CDM as teacher transfers core class knowledge only via CLAReps, which amounts to merely 10 % of the training data in size. After training, the student achieves strong adversarial robustness and generalization ability, focusing more on the class signals instead of spurious background cues. Our findings suggest that CDMs can serve not just as image generators but also as compact, interpretable teachers that can drive robust representation learning.
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025



The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
Towards Better Generalization via Distributional Input Projection Network
Jun 05, 2025As overparameterized models become increasingly prevalent, training loss alone offers limited insight into generalization performance. While smoothness has been linked to improved generalization across various settings, directly enforcing smoothness in neural networks remains challenging. To address this, we introduce Distributional Input Projection Networks (DIPNet), a novel framework that projects inputs into learnable distributions at each layer. This distributional representation induces a smoother loss landscape with respect to the input, promoting better generalization. We provide theoretical analysis showing that DIPNet reduces both local smoothness measures and the Lipschitz constant of the network, contributing to improved generalization performance. Empirically, we validate DIPNet across a wide range of architectures and tasks, including Vision Transformers (ViTs), Large Language Models (LLMs), ResNet and MLPs. Our method consistently enhances test performance under standard settings, adversarial attacks, out-of-distribution inputs, and reasoning benchmarks. We demonstrate that the proposed input projection strategy can be seamlessly integrated into existing models, providing a general and effective approach for boosting generalization performance in modern deep learning.
MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
May 30, 2025Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.