 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Visual Awareness in Multimodal Neural Machine Translation from an Information Theoretic Perspective
Oct 16, 2022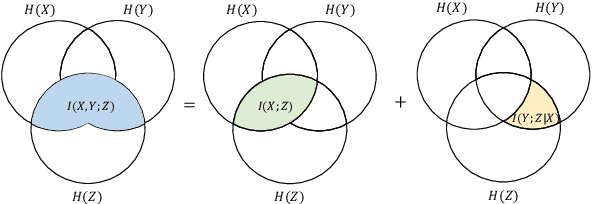
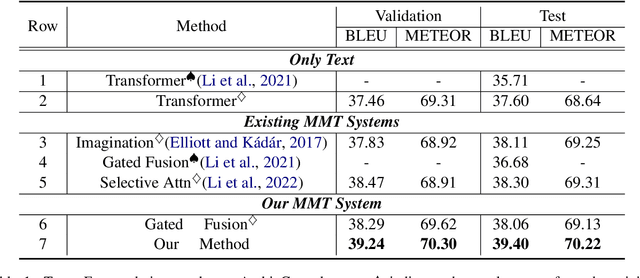
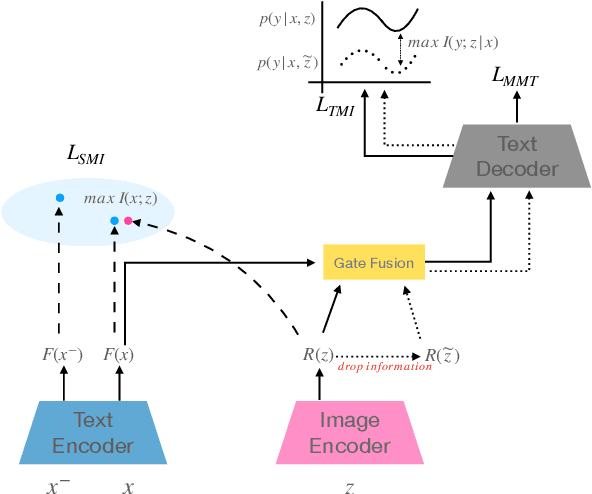
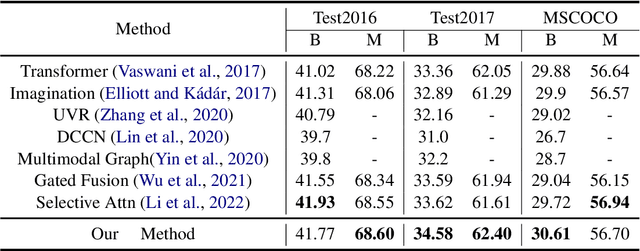
Multimodal machine translation (MMT) aims to improve translation quality by equipping the source sentence with its corresponding image. Despite the promising performance, MMT models still suffer the problem of input degradation: models focus more on textual information while visual information is generally overlooked. In this paper, we endeavor to improve MMT performance by increasing visual awareness from an information theoretic perspective. In detail, we decompose the informative visual signals into two parts: source-specific information and target-specific information. We use mutual information to quantify them and propose two methods for objective optimization to better leverage visual signals. Experiments on two datasets demonstrate that our approach can effectively enhance the visual awareness of MMT model and achieve superior results against strong baselines.
MICO: A Multi-alternative Contrastive Learning Framework for Commonsense Knowledge Representation
Oct 14, 2022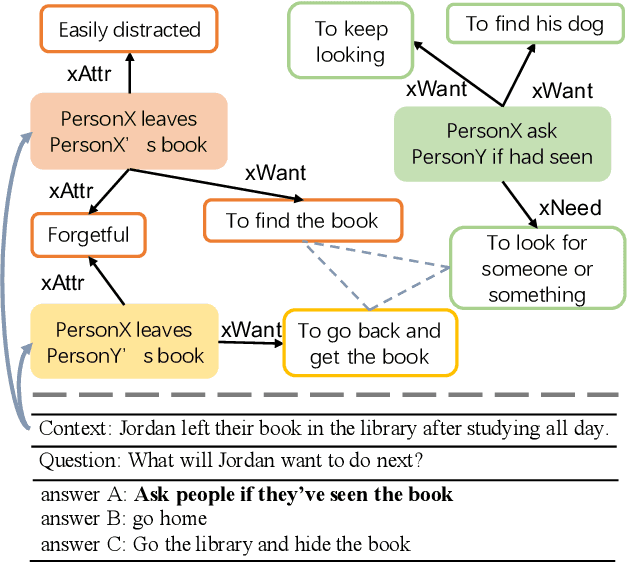

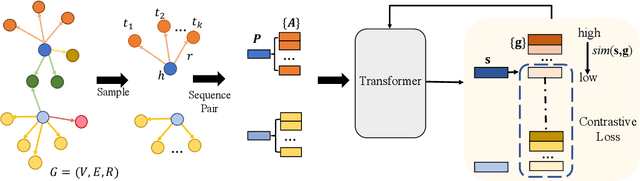
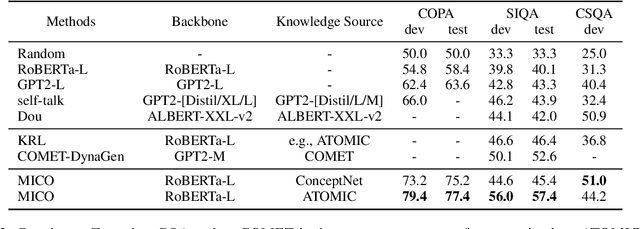
Commonsense reasoning tasks such as commonsense knowledge graph completion and commonsense question answering require powerful representation learning. In this paper, we propose to learn commonsense knowledge representation by MICO, a Multi-alternative contrastve learning framework on COmmonsense knowledge graphs (MICO). MICO generates the commonsense knowledge representation by contextual interaction between entity nodes and relations with multi-alternative contrastive learning. In MICO, the head and tail entities in an $(h,r,t)$ knowledge triple are converted to two relation-aware sequence pairs (a premise and an alternative) in the form of natural language. Semantic representations generated by MICO can benefit the following two tasks by simply comparing the distance score between the representations: 1) zero-shot commonsense question answering task; 2) inductive commonsense knowledge graph completion task. Extensive experiments show the effectiveness of our method.
* 9 pages, 2 figures
Multilingual Word Sense Disambiguation with Unified Sense Representation
Oct 14, 2022
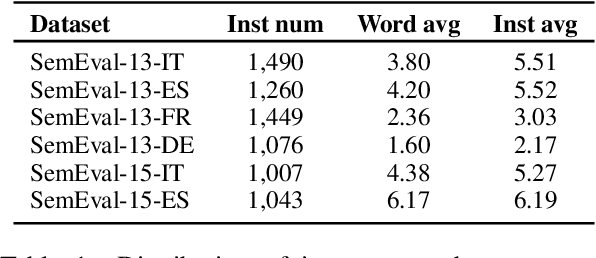
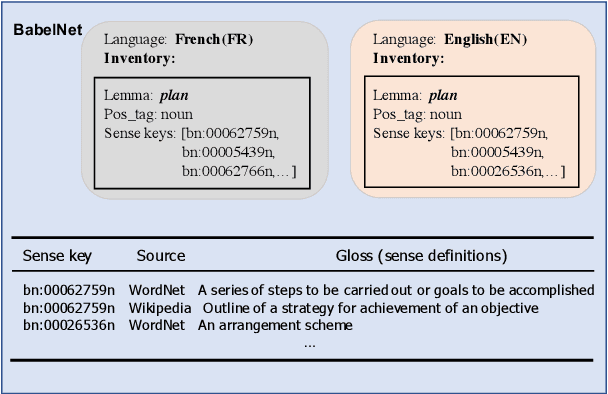
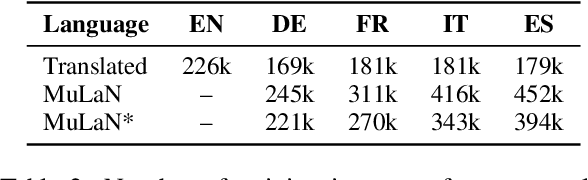
As a key natural language processing (NLP) task, word sense disambiguation (WSD) evaluates how well NLP models can understand the lexical semantics of words under specific contexts. Benefited from the large-scale annotation, current WSD systems have achieved impressive performances in English by combining supervised learning with lexical knowledge. However, such success is hard to be replicated in other languages, where we only have limited annotations.In this paper, based on the multilingual lexicon BabelNet describing the same set of concepts across languages, we propose building knowledge and supervised-based Multilingual Word Sense Disambiguation (MWSD) systems. We build unified sense representations for multiple languages and address the annotation scarcity problem for MWSD by transferring annotations from rich-sourced languages to poorer ones. With the unified sense representations, annotations from multiple languages can be jointly trained to benefit the MWSD tasks. Evaluations of SemEval-13 and SemEval-15 datasets demonstrate the effectiveness of our methodology.
* 8 pages, 5 figures
A Self-Play Posterior Sampling Algorithm for Zero-Sum Markov Games
Oct 04, 2022Existing studies on provably efficient algorithms for Markov games (MGs) almost exclusively build on the "optimism in the face of uncertainty" (OFU) principle. This work focuses on a different approach of posterior sampling, which is celebrated in many bandits and reinforcement learning settings but remains under-explored for MGs. Specifically, for episodic two-player zero-sum MGs, a novel posterior sampling algorithm is developed with general function approximation. Theoretical analysis demonstrates that the posterior sampling algorithm admits a $\sqrt{T}$-regret bound for problems with a low multi-agent decoupling coefficient, which is a new complexity measure for MGs, where $T$ denotes the number of episodes. When specialized to linear MGs, the obtained regret bound matches the state-of-the-art results. To the best of our knowledge, this is the first provably efficient posterior sampling algorithm for MGs with frequentist regret guarantees, which enriches the toolbox for MGs and promotes the broad applicability of posterior sampling.
Optimality of the Proper Gaussian Signal in Complex MIMO Wiretap Channels
Sep 28, 2022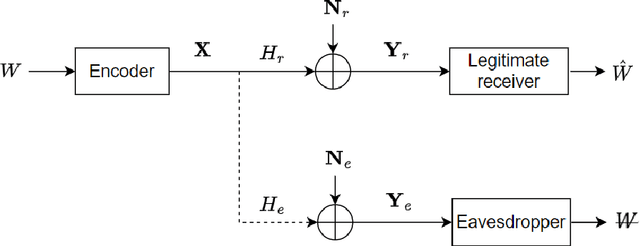
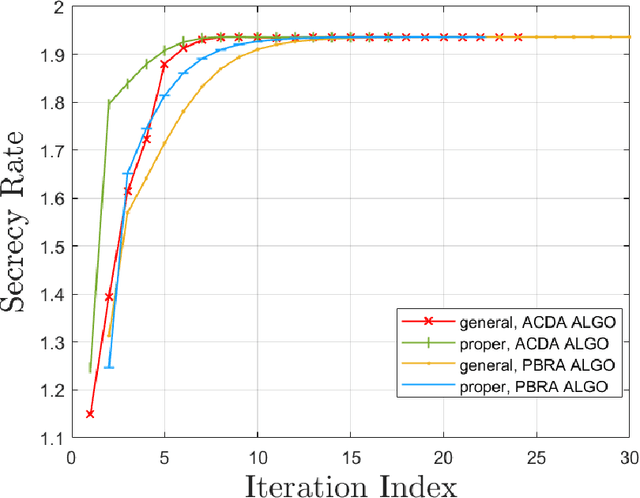
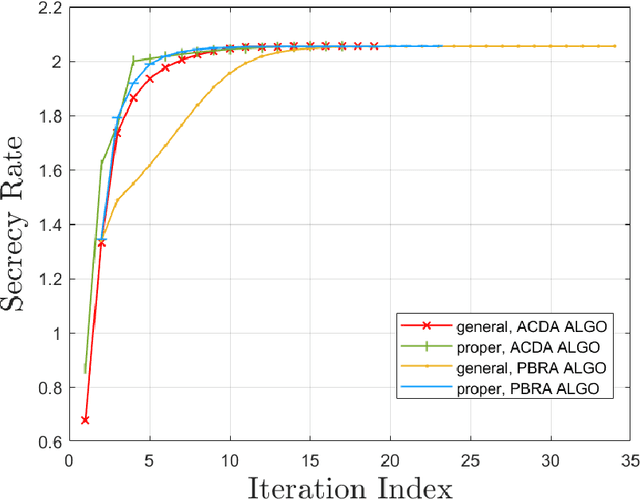
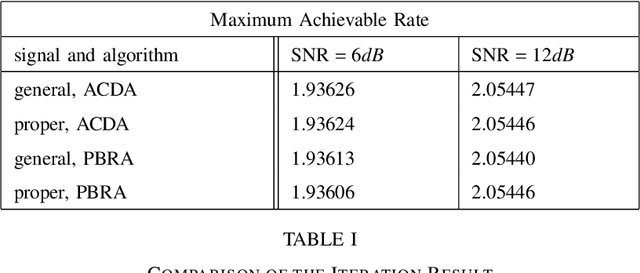
The multiple-input multiple-output (MIMO) wiretap channel (WTC), which has a transmitter, a legitimate user and an eavesdropper, is a classic model for studying information theoretic secrecy. In this paper, the fundamental problem for the complex WTC is whether the proper signal is optimal has yet to be given explicit proof, though previous work implicitly assumed the complex signal was proper. Thus, a determinant inequality is proposed to prove that the secrecy rate of a complex Gaussian signal with a fixed covariance matrix in a degraded complex WTC is maximized if and only if the signal is proper, i.e., the pseudo-covariance matrix is a zero matrix. Moreover, based on the result of the degraded complex WTC and the min-max reformulation of the secrecy capacity, the optimality of the proper signal in the general complex WTC is also revealed. The results of this research complement the current research on complex WTC. To be more specific, we have shown it is sufficient to focus on the proper signal when studying the secrecy capacity of the complex WTC.
Asymptotic Statistical Analysis of $f$-divergence GAN
Sep 14, 2022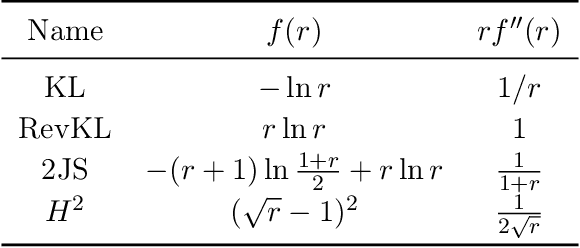
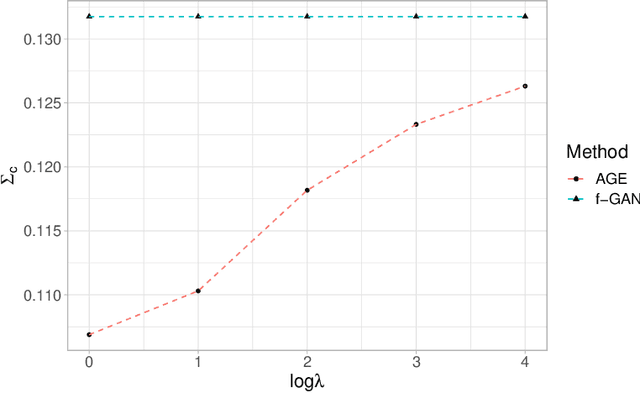
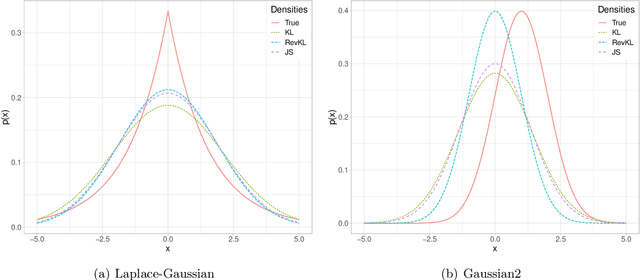
Generative Adversarial Networks (GANs) have achieved great success in data generation. However, its statistical properties are not fully understood. In this paper, we consider the statistical behavior of the general $f$-divergence formulation of GAN, which includes the Kullback--Leibler divergence that is closely related to the maximum likelihood principle. We show that for parametric generative models that are correctly specified, all $f$-divergence GANs with the same discriminator classes are asymptotically equivalent under suitable regularity conditions. Moreover, with an appropriately chosen local discriminator, they become equivalent to the maximum likelihood estimate asymptotically. For generative models that are misspecified, GANs with different $f$-divergences {converge to different estimators}, and thus cannot be directly compared. However, it is shown that for some commonly used $f$-divergences, the original $f$-GAN is not optimal in that one can achieve a smaller asymptotic variance when the discriminator training in the original $f$-GAN formulation is replaced by logistic regression. The resulting estimation method is referred to as Adversarial Gradient Estimation (AGE). Empirical studies are provided to support the theory and to demonstrate the advantage of AGE over the original $f$-GANs under model misspecification.
Exploiting Hybrid Semantics of Relation Paths for Multi-hop Question Answering Over Knowledge Graphs
Sep 02, 2022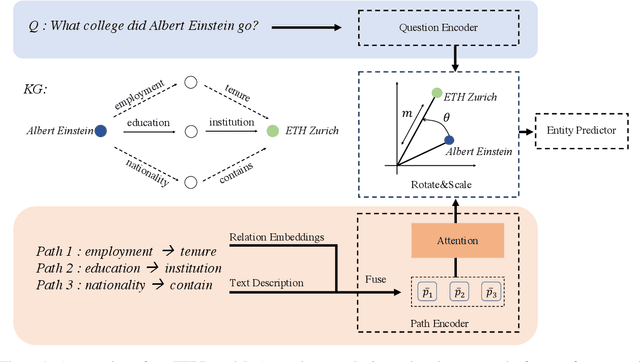
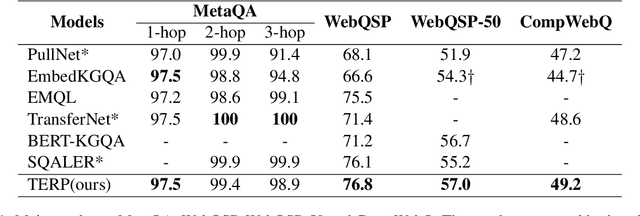
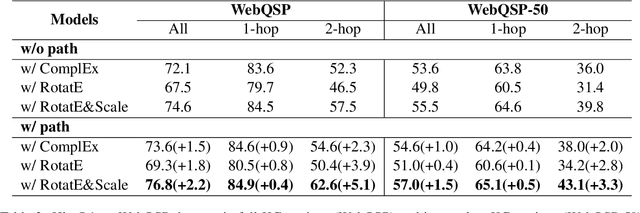
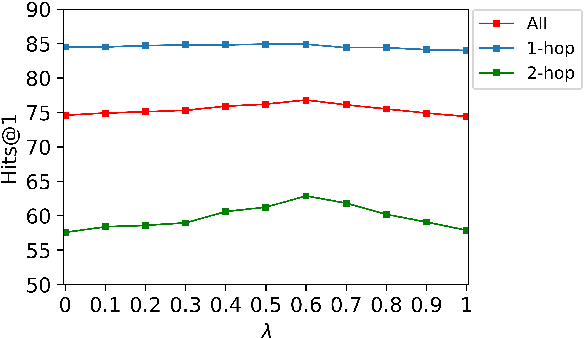
Answering natural language questions on knowledge graphs (KGQA) remains a great challenge in terms of understanding complex questions via multi-hop reasoning. Previous efforts usually exploit large-scale entity-related text corpora or knowledge graph (KG) embeddings as auxiliary information to facilitate answer selection. However, the rich semantics implied in off-the-shelf relation paths between entities is far from well explored. This paper proposes improving multi-hop KGQA by exploiting relation paths' hybrid semantics. Specifically, we integrate explicit textual information and implicit KG structural features of relation paths based on a novel rotate-and-scale entity link prediction framework. Extensive experiments on three existing KGQA datasets demonstrate the superiority of our method, especially in multi-hop scenarios. Further investigation confirms our method's systematical coordination between questions and relation paths to identify answer entities.
A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning
Aug 23, 2022Thompson Sampling is one of the most effective methods for contextual bandits and has been generalized to posterior sampling for certain MDP settings. However, existing posterior sampling methods for reinforcement learning are limited by being model-based or lack worst-case theoretical guarantees beyond linear MDPs. This paper proposes a new model-free formulation of posterior sampling that applies to more general episodic reinforcement learning problems with theoretical guarantees. We introduce novel proof techniques to show that under suitable conditions, the worst-case regret of our posterior sampling method matches the best known results of optimization based methods. In the linear MDP setting with dimension, the regret of our algorithm scales linearly with the dimension as compared to a quadratic dependence of the existing posterior sampling-based exploration algorithms.
Two-person Graph Convolutional Network for Skeleton-based Human Interaction Recognition
Aug 12, 2022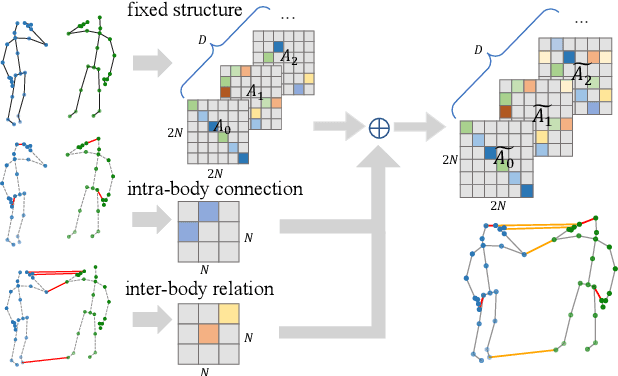
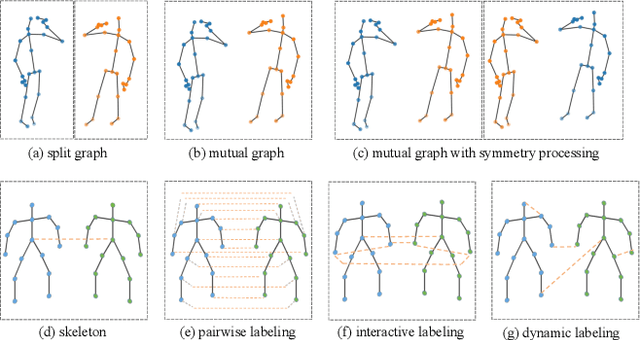
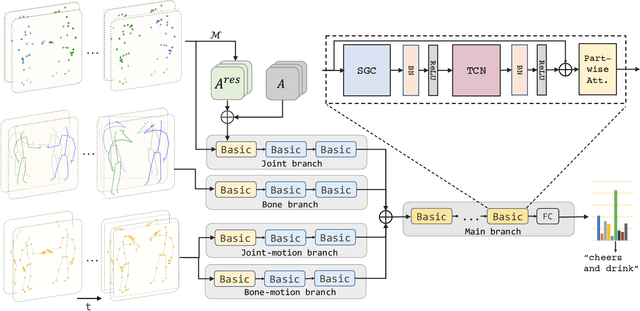
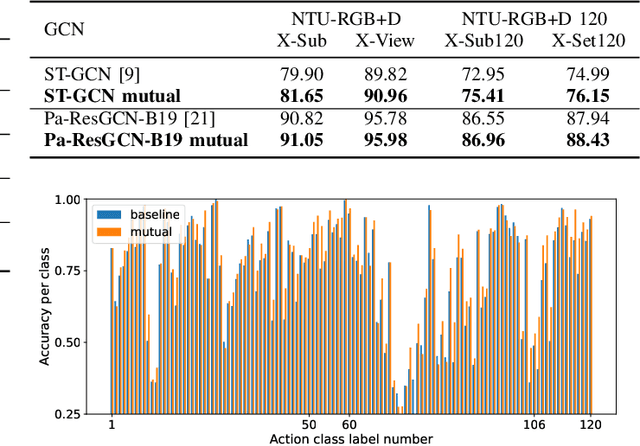
Graph Convolutional Network (GCN) outperforms previous methods in the skeleton-based human action recognition area, including human-human interaction recognition task. However, when dealing with interaction sequences, current GCN-based methods simply split the two-person skeleton into two discrete sequences and perform graph convolution separately in the manner of single-person action classification. Such operation ignores rich interactive information and hinders effective spatial relationship modeling for semantic pattern learning. To overcome the above shortcoming, we introduce a novel unified two-person graph representing spatial interaction correlations between joints. Also, a properly designed graph labeling strategy is proposed to let our GCN model learn discriminant spatial-temporal interactive features. Experiments show accuracy improvements in both interactions and individual actions when utilizing the proposed two-person graph topology. Finally, we propose a Two-person Graph Convolutional Network (2P-GCN). The proposed 2P-GCN achieves state-of-the-art results on four benchmarks of three interaction datasets, SBU, NTU-RGB+D, and NTU-RGB+D 120.
OpenMedIA: Open-Source Medical Image Analysis Toolbox and Benchmark under Heterogeneous AI Computing Platforms
Aug 11, 2022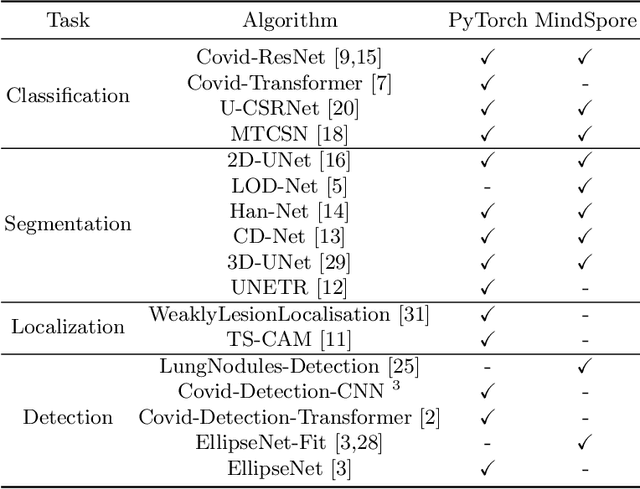
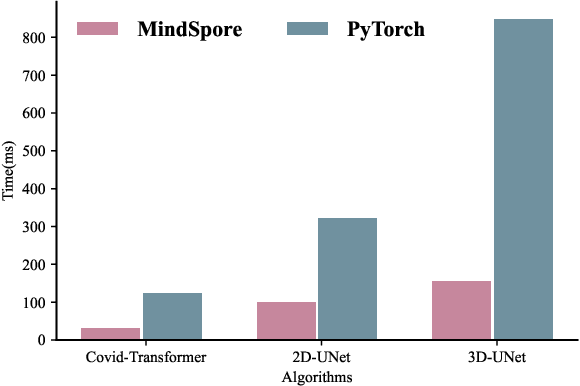
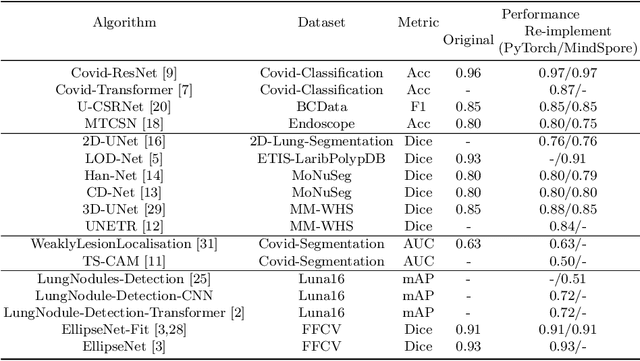
In this paper, we present OpenMedIA, an open-source toolbox library containing a rich set of deep learning methods for medical image analysis under heterogeneous Artificial Intelligence (AI) computing platforms. Various medical image analysis methods, including 2D$/$3D medical image classification, segmentation, localisation, and detection, have been included in the toolbox with PyTorch and$/$or MindSpore implementations under heterogeneous NVIDIA and Huawei Ascend computing systems. To our best knowledge, OpenMedIA is the first open-source algorithm library providing compared PyTorch and MindSp