 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
In-Hand 3D Object Scanning from an RGB Sequence
Nov 28, 2022
We propose a method for in-hand 3D scanning of an unknown object from a sequence of color images. We cast the problem as reconstructing the object surface from un-posed multi-view images and rely on a neural implicit surface representation that captures both the geometry and the appearance of the object. By contrast with most NeRF-based methods, we do not assume that the camera-object relative poses are known and instead simultaneously optimize both the object shape and the pose trajectory. As global optimization over all the shape and pose parameters is prone to fail without coarse-level initialization of the poses, we propose an incremental approach which starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed. We incrementally reconstruct the object shape and track the object poses independently within each segment, and later merge all the segments by aligning poses estimated at the overlapping frames. Finally, we perform a global optimization over all the aligned segments to achieve full reconstruction. We experimentally show that the proposed method is able to reconstruct the shape and color of both textured and challenging texture-less objects, outperforms classical methods that rely only on appearance features, and its performance is close to recent methods that assume known camera poses.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022



Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
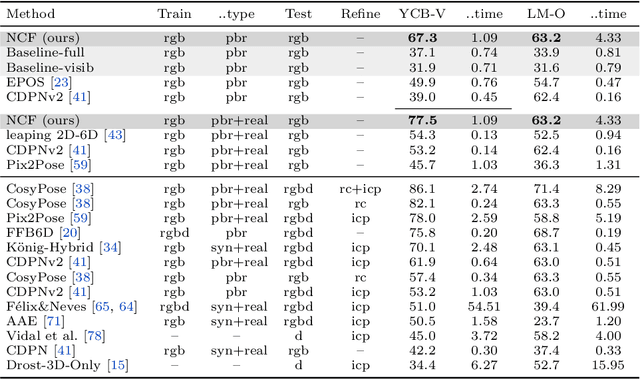
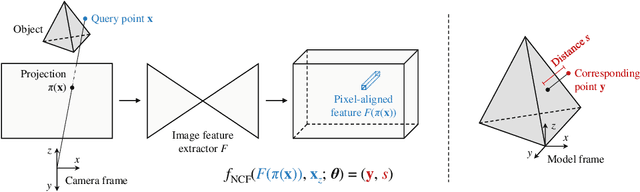
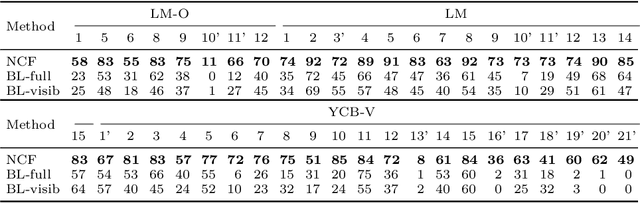
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
LISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022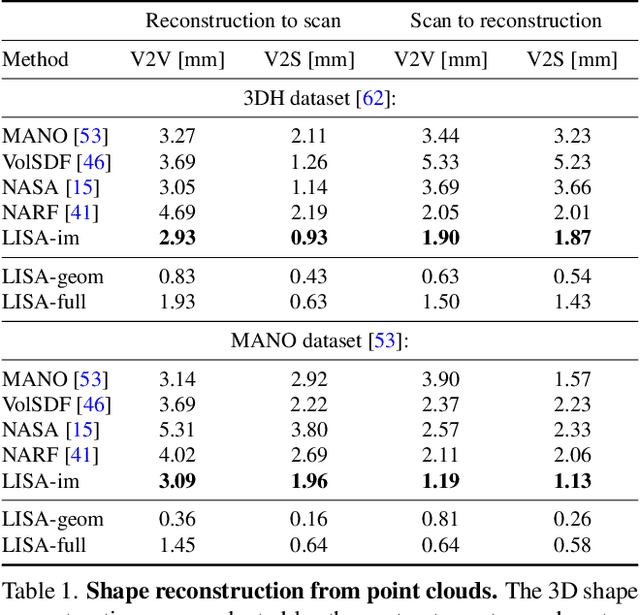
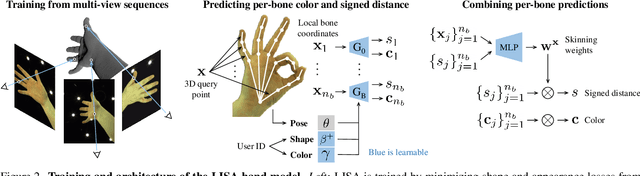
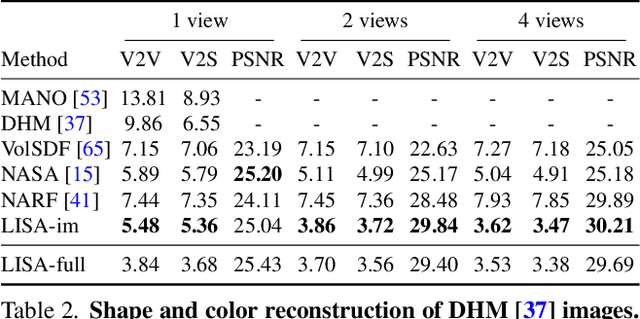
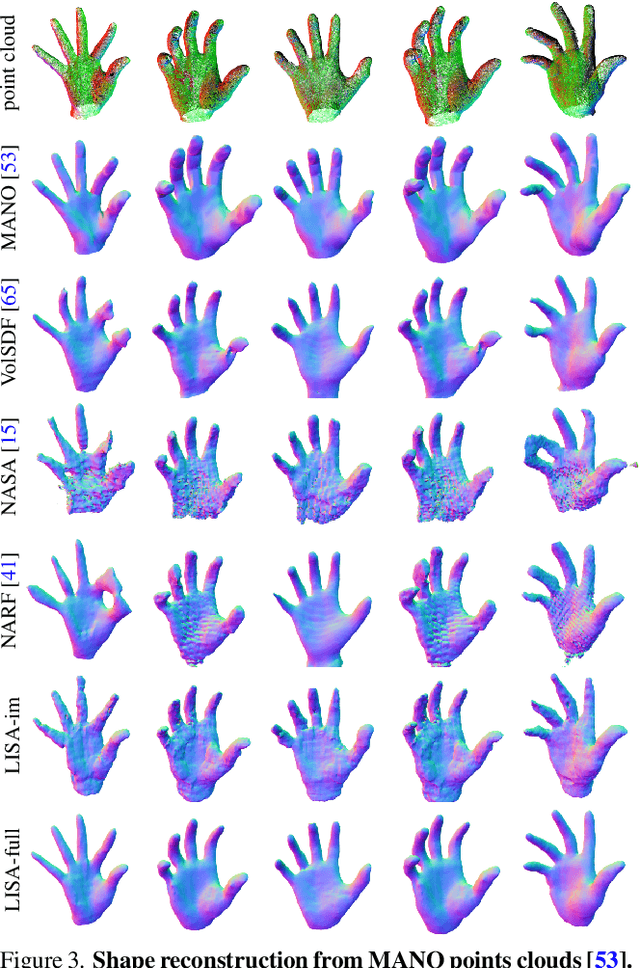
This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.
Pose Estimation of Specific Rigid Objects
Dec 30, 2021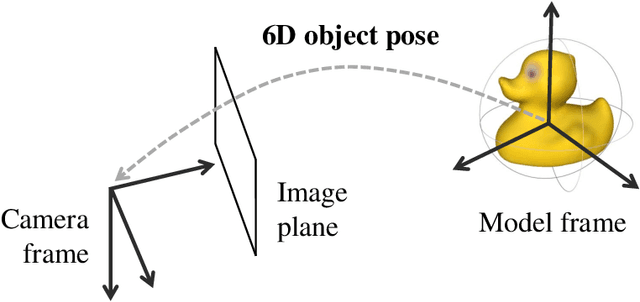
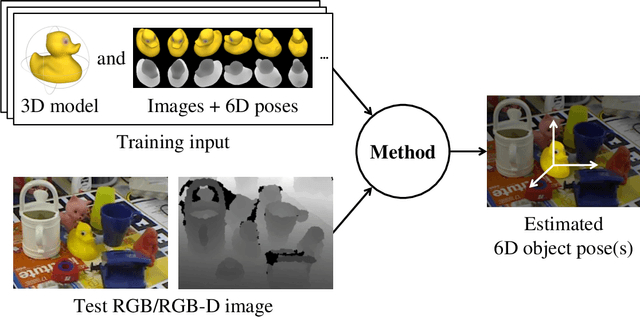
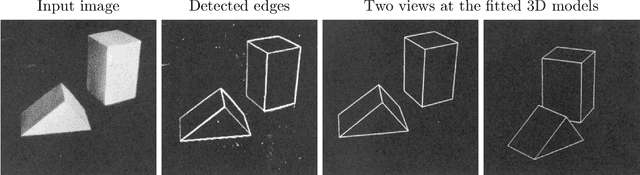
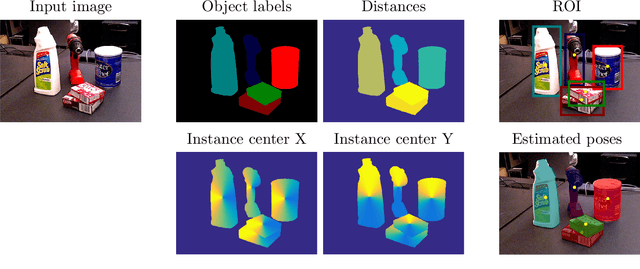
In this thesis, we address the problem of estimating the 6D pose of rigid objects from a single RGB or RGB-D input image, assuming that 3D models of the objects are available. This problem is of great importance to many application fields such as robotic manipulation, augmented reality, and autonomous driving. First, we propose EPOS, a method for 6D object pose estimation from an RGB image. The key idea is to represent an object by compact surface fragments and predict the probability distribution of corresponding fragments at each pixel of the input image by a neural network. Each pixel is linked with a data-dependent number of fragments, which allows systematic handling of symmetries, and the 6D poses are estimated from the links by a RANSAC-based fitting method. EPOS outperformed all RGB and most RGB-D and D methods on several standard datasets. Second, we present HashMatch, an RGB-D method that slides a window over the input image and searches for a match against templates, which are pre-generated by rendering 3D object models in different orientations. The method applies a cascade of evaluation stages to each window location, which avoids exhaustive matching against all templates. Third, we propose ObjectSynth, an approach to synthesize photorealistic images of 3D object models for training methods based on neural networks. The images yield substantial improvements compared to commonly used images of objects rendered on top of random photographs. Fourth, we introduce T-LESS, the first dataset for 6D object pose estimation that includes 3D models and RGB-D images of industry-relevant objects. Fifth, we define BOP, a benchmark that captures the status quo in the field. BOP comprises eleven datasets in a unified format, an evaluation methodology, an online evaluation system, and public challenges held at international workshops organized at the ICCV and ECCV conferences.
BOP Challenge 2020 on 6D Object Localization
Oct 13, 2020
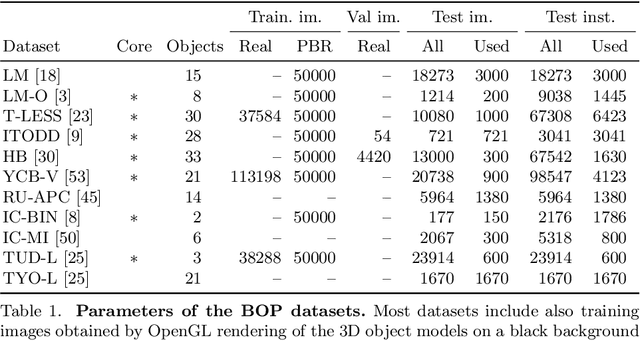

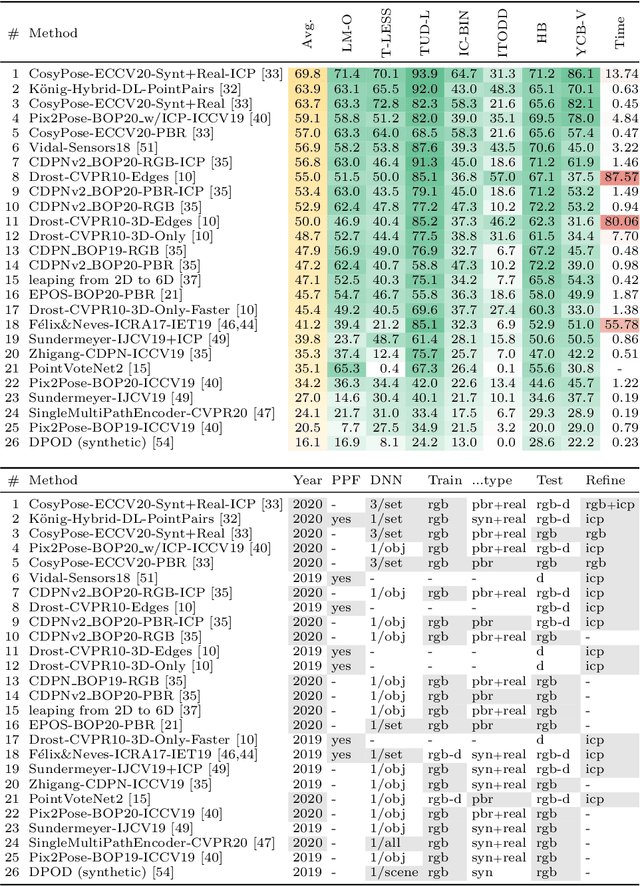
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic training images generated by BlenderProc4BOP, a new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time - out of the 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth on RGB channels of PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available on the project website: bop.felk.cvut.cz.
Learning Surrogates via Deep Embedding
Jul 17, 2020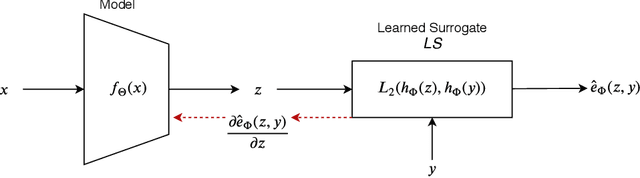
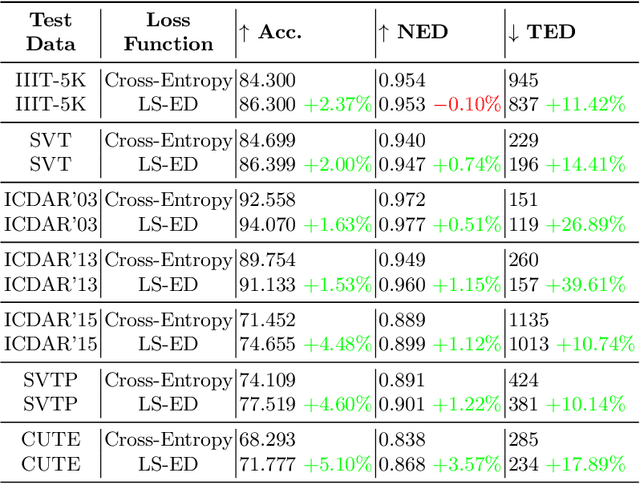
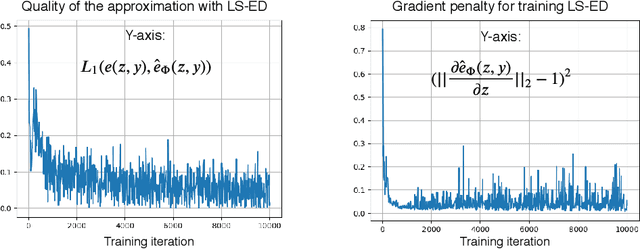
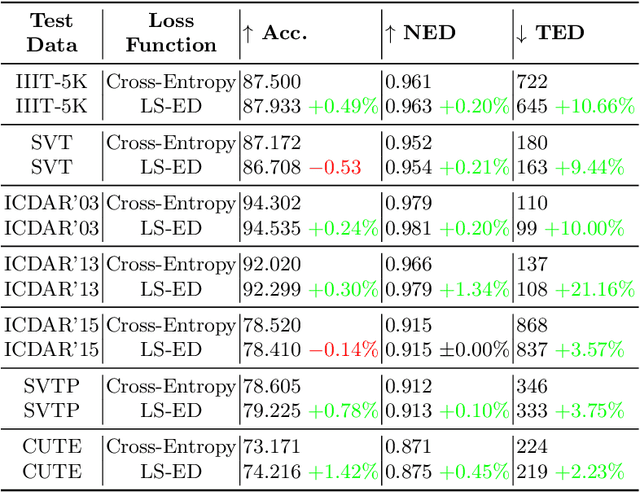
This paper proposes a technique for training a neural network by minimizing a surrogate loss that approximates the target evaluation metric, which may be non-differentiable. The surrogate is learned via a deep embedding where the Euclidean distance between the prediction and the ground truth corresponds to the value of the evaluation metric. The effectiveness of the proposed technique is demonstrated in a post-tuning setup, where a trained model is tuned using the learned surrogate. Without a significant computational overhead and any bells and whistles, improvements are demonstrated on challenging and practical tasks of scene-text recognition and detection. In the recognition task, the model is tuned using a surrogate approximating the edit distance metric and achieves up to $39\%$ relative improvement in the total edit distance. In the detection task, the surrogate approximates the intersection over union metric for rotated bounding boxes and yields up to $4.25\%$ relative improvement in the $F_{1}$ score.
EPOS: Estimating 6D Pose of Objects with Symmetries
Apr 01, 2020
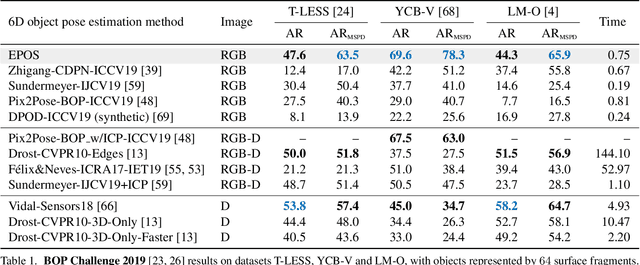
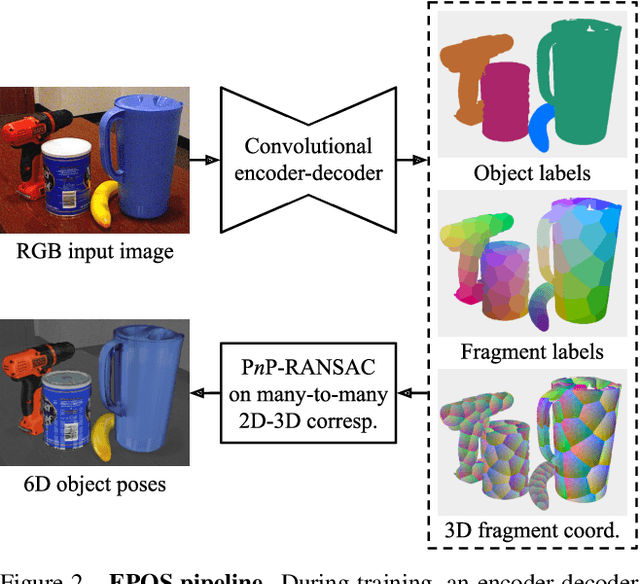
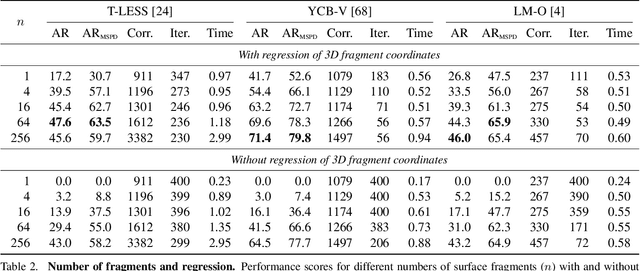
We present a new method for estimating the 6D pose of rigid objects with available 3D models from a single RGB input image. The method is applicable to a broad range of objects, including challenging ones with global or partial symmetries. An object is represented by compact surface fragments which allow handling symmetries in a systematic manner. Correspondences between densely sampled pixels and the fragments are predicted using an encoder-decoder network. At each pixel, the network predicts: (i) the probability of each object's presence, (ii) the probability of the fragments given the object's presence, and (iii) the precise 3D location on each fragment. A data-dependent number of corresponding 3D locations is selected per pixel, and poses of possibly multiple object instances are estimated using a robust and efficient variant of the PnP-RANSAC algorithm. In the BOP Challenge 2019, the method outperforms all RGB and most RGB-D and D methods on the T-LESS and LM-O datasets. On the YCB-V dataset, it is superior to all competitors, with a large margin over the second-best RGB method. Source code is at: cmp.felk.cvut.cz/epos.
Photorealistic Image Synthesis for Object Instance Detection
Feb 09, 2019
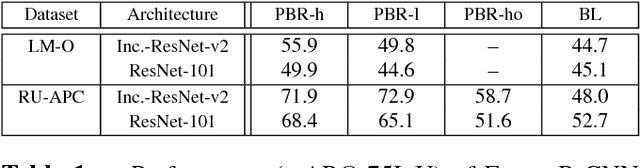


We present an approach to synthesize highly photorealistic images of 3D object models, which we use to train a convolutional neural network for detecting the objects in real images. The proposed approach has three key ingredients: (1) 3D object models are rendered in 3D models of complete scenes with realistic materials and lighting, (2) plausible geometric configuration of objects and cameras in a scene is generated using physics simulations, and (3) high photorealism of the synthesized images achieved by physically based rendering. When trained on images synthesized by the proposed approach, the Faster R-CNN object detector achieves a 24% absolute improvement of mAP@.75IoU on Rutgers APC and 11% on LineMod-Occluded datasets, compared to a baseline where the training images are synthesized by rendering object models on top of random photographs. This work is a step towards being able to effectively train object detectors without capturing or annotating any real images. A dataset of 600K synthetic images with ground truth annotations for various computer vision tasks will be released on the project website: thodan.github.io/objectsynth.