 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHOW3D: Capturing Scenes of 3D Hands and Objects in the Wild
Mar 30, 2026Accurate 3D understanding of human hands and objects during manipulation remains a significant challenge for egocentric computer vision. Existing hand-object interaction datasets are predominantly captured in controlled studio settings, which limits both environmental diversity and the ability of models trained on such data to generalize to real-world scenarios. To address this challenge, we introduce a novel marker-less multi-camera system that allows for nearly unconstrained mobility in genuinely in-the-wild conditions, while still having the ability to generate precise 3D annotations of hands and objects. The capture system consists of a lightweight, back-mounted, multi-camera rig that is synchronized and calibrated with a user-worn VR headset. For 3D ground-truth annotation of hands and objects, we develop an ego-exo tracking pipeline and rigorously evaluate its quality. Finally, we present SHOW3D, the first large-scale dataset with 3D annotations that show hands interacting with objects in diverse real-world environments, including outdoor settings. Our approach significantly reduces the fundamental trade-off between environmental realism and accuracy of 3D annotations, which we validate with experiments on several downstream tasks. show3d-dataset.github.io
emg2pose: A Large and Diverse Benchmark for Surface Electromyographic Hand Pose Estimation
Dec 02, 2024



Hands are the primary means through which humans interact with the world. Reliable and always-available hand pose inference could yield new and intuitive control schemes for human-computer interactions, particularly in virtual and augmented reality. Computer vision is effective but requires one or multiple cameras and can struggle with occlusions, limited field of view, and poor lighting. Wearable wrist-based surface electromyography (sEMG) presents a promising alternative as an always-available modality sensing muscle activities that drive hand motion. However, sEMG signals are strongly dependent on user anatomy and sensor placement, and existing sEMG models have required hundreds of users and device placements to effectively generalize. To facilitate progress on sEMG pose inference, we introduce the emg2pose benchmark, the largest publicly available dataset of high-quality hand pose labels and wrist sEMG recordings. emg2pose contains 2kHz, 16 channel sEMG and pose labels from a 26-camera motion capture rig for 193 users, 370 hours, and 29 stages with diverse gestures - a scale comparable to vision-based hand pose datasets. We provide competitive baselines and challenging tasks evaluating real-world generalization scenarios: held-out users, sensor placements, and stages. emg2pose provides the machine learning community a platform for exploring complex generalization problems, holding potential to significantly enhance the development of sEMG-based human-computer interactions.
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022



Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Lightweight Multi-View 3D Pose Estimation through Camera-Disentangled Representation
Apr 05, 2020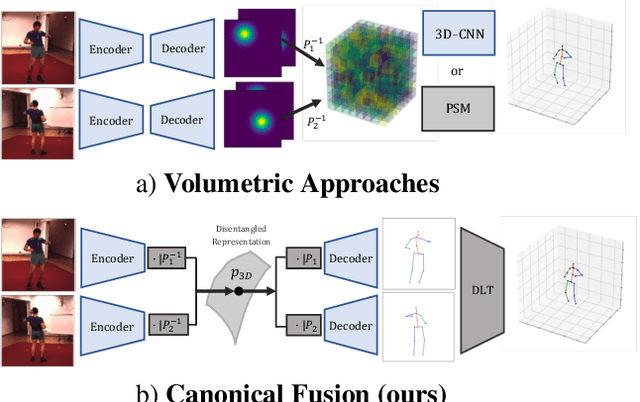
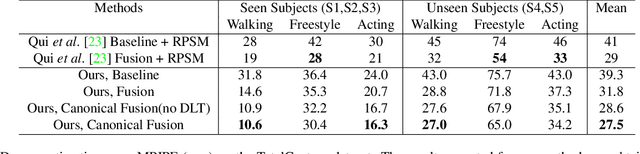
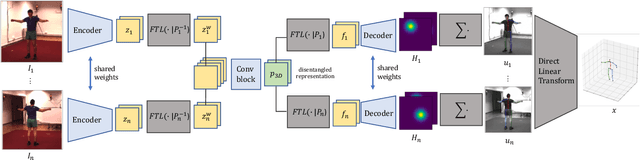
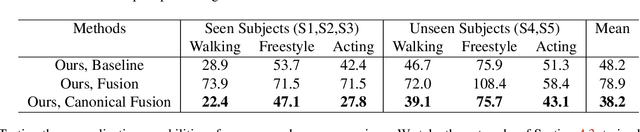
We present a lightweight solution to recover 3D pose from multi-view images captured with spatially calibrated cameras. Building upon recent advances in interpretable representation learning, we exploit 3D geometry to fuse input images into a unified latent representation of pose, which is disentangled from camera view-points. This allows us to reason effectively about 3D pose across different views without using compute-intensive volumetric grids. Our architecture then conditions the learned representation on camera projection operators to produce accurate per-view 2d detections, that can be simply lifted to 3D via a differentiable Direct Linear Transform (DLT) layer. In order to do it efficiently, we propose a novel implementation of DLT that is orders of magnitude faster on GPU architectures than standard SVD-based triangulation methods. We evaluate our approach on two large-scale human pose datasets (H36M and Total Capture): our method outperforms or performs comparably to the state-of-the-art volumetric methods, while, unlike them, yielding real-time performance.