 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More with Less: A Dynamic Dual-Level Down-Sampling Framework for Efficient Policy Optimization
Sep 26, 2025Critic-free methods like GRPO reduce memory demands by estimating advantages from multiple rollouts but tend to converge slowly, as critical learning signals are diluted by an abundance of uninformative samples and tokens. To tackle this challenge, we propose the \textbf{Dynamic Dual-Level Down-Sampling (D$^3$S)} framework that prioritizes the most informative samples and tokens across groups to improve the efficient of policy optimization. D$^3$S operates along two levels: (1) the sample-level, which selects a subset of rollouts to maximize advantage variance ($\text{Var}(A)$). We theoretically proven that this selection is positively correlated with the upper bound of the policy gradient norms, yielding higher policy gradients. (2) the token-level, which prioritizes tokens with a high product of advantage magnitude and policy entropy ($|A_{i,t}|\times H_{i,t}$), focusing updates on tokens where the policy is both uncertain and impactful. Moreover, to prevent overfitting to high-signal data, D$^3$S employs a dynamic down-sampling schedule inspired by curriculum learning. This schedule starts with aggressive down-sampling to accelerate early learning and gradually relaxes to promote robust generalization. Extensive experiments on Qwen2.5 and Llama3.1 demonstrate that integrating D$^3$S into advanced RL algorithms achieves state-of-the-art performance and generalization while requiring \textit{fewer} samples and tokens across diverse reasoning benchmarks. Our code is added in the supplementary materials and will be made publicly available.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
Discriminative Policy Optimization for Token-Level Reward Models
May 29, 2025Process reward models (PRMs) provide more nuanced supervision compared to outcome reward models (ORMs) for optimizing policy models, positioning them as a promising approach to enhancing the capabilities of LLMs in complex reasoning tasks. Recent efforts have advanced PRMs from step-level to token-level granularity by integrating reward modeling into the training of generative models, with reward scores derived from token generation probabilities. However, the conflict between generative language modeling and reward modeling may introduce instability and lead to inaccurate credit assignments. To address this challenge, we revisit token-level reward assignment by decoupling reward modeling from language generation and derive a token-level reward model through the optimization of a discriminative policy, termed the Q-function Reward Model (Q-RM). We theoretically demonstrate that Q-RM explicitly learns token-level Q-functions from preference data without relying on fine-grained annotations. In our experiments, Q-RM consistently outperforms all baseline methods across various benchmarks. For example, when integrated into PPO/REINFORCE algorithms, Q-RM enhances the average Pass@1 score by 5.85/4.70 points on mathematical reasoning tasks compared to the ORM baseline, and by 4.56/5.73 points compared to the token-level PRM counterpart. Moreover, reinforcement learning with Q-RM significantly enhances training efficiency, achieving convergence 12 times faster than ORM on GSM8K and 11 times faster than step-level PRM on MATH. Code and data are available at https://github.com/homzer/Q-RM.
Wizard of Search Engine: Access to Information Through Conversations with Search Engines
May 18, 2021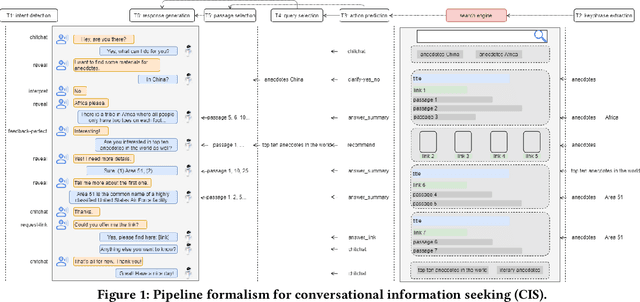

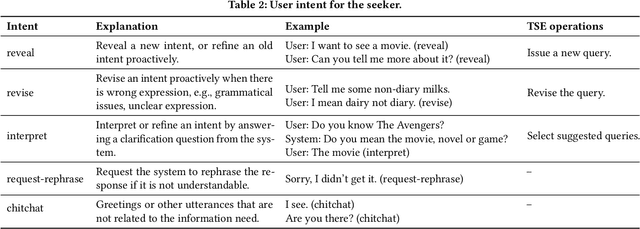
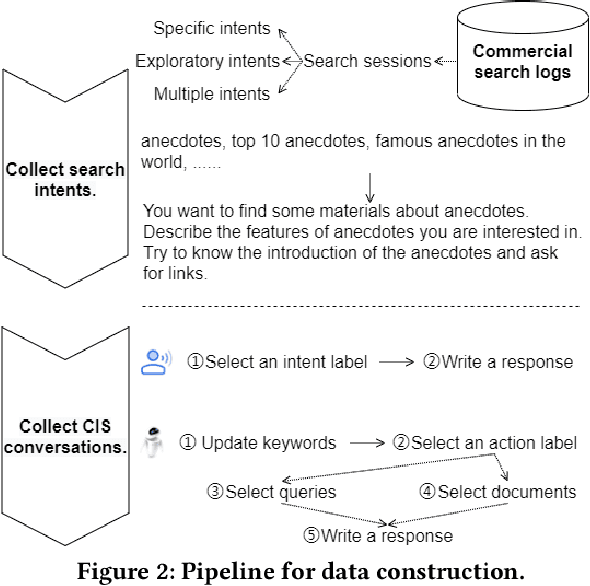
Conversational information seeking (CIS) is playing an increasingly important role in connecting people to information. Due to the lack of suitable resource, previous studies on CIS are limited to the study of theoretical/conceptual frameworks, laboratory-based user studies, or a particular aspect of CIS (e.g., asking clarifying questions). In this work, we make efforts to facilitate research on CIS from three aspects. (1) We formulate a pipeline for CIS with six sub-tasks: intent detection (ID), keyphrase extraction (KE), action prediction (AP), query selection (QS), passage selection (PS), and response generation (RG). (2) We release a benchmark dataset, called wizard of search engine (WISE), which allows for comprehensive and in-depth research on all aspects of CIS. (3) We design a neural architecture capable of training and evaluating both jointly and separately on the six sub-tasks, and devise a pre-train/fine-tune learning scheme, that can reduce the requirements of WISE in scale by making full use of available data. We report some useful characteristics of CIS based on statistics of WISE. We also show that our best performing model variant isable to achieve effective CIS as indicated by several metrics. We release the dataset, the code, as well as the evaluation scripts to facilitate future research by measuring further improvements in this important research direction.