 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing attention zones in machine reading comprehension models
Oct 28, 2024



The attention mechanism plays an important role in the machine reading comprehension (MRC) model. Here, we describe a pipeline for building an MRC model with a pretrained language model and visualizing the effect of each attention zone in different layers, which can indicate the explainability of the model. With the presented protocol and accompanying code, researchers can easily visualize the relevance of each attention zone in the MRC model. This approach can be generalized to other pretrained language models.
A Static and Dynamic Attention Framework for Multi Turn Dialogue Generation
Oct 28, 2024



Recently, research on open domain dialogue systems have attracted extensive interests of academic and industrial researchers. The goal of an open domain dialogue system is to imitate humans in conversations. Previous works on single turn conversation generation have greatly promoted the research of open domain dialogue systems. However, understanding multiple single turn conversations is not equal to the understanding of multi turn dialogue due to the coherent and context dependent properties of human dialogue. Therefore, in open domain multi turn dialogue generation, it is essential to modeling the contextual semantics of the dialogue history, rather than only according to the last utterance. Previous research had verified the effectiveness of the hierarchical recurrent encoder-decoder framework on open domain multi turn dialogue generation. However, using RNN-based model to hierarchically encoding the utterances to obtain the representation of dialogue history still face the problem of a vanishing gradient. To address this issue, in this paper, we proposed a static and dynamic attention-based approach to model the dialogue history and then generate open domain multi turn dialogue responses. Experimental results on Ubuntu and Opensubtitles datasets verify the effectiveness of the proposed static and dynamic attention-based approach on automatic and human evaluation metrics in various experimental settings. Meanwhile, we also empirically verify the performance of combining the static and dynamic attentions on open domain multi turn dialogue generation.
* published as a journal paper at ACM Transactions on Information Systems 2023. 30 pages, 6 figures
A Stack-Propagation Framework for Low-Resource Personalized Dialogue Generation
Oct 26, 2024



With the resurgent interest in building open-domain dialogue systems, the dialogue generation task has attracted increasing attention over the past few years. This task is usually formulated as a conditional generation problem, which aims to generate a natural and meaningful response given dialogue contexts and specific constraints, such as persona. And maintaining a consistent persona is essential for the dialogue systems to gain trust from the users. Although tremendous advancements have been brought, traditional persona-based dialogue models are typically trained by leveraging a large number of persona-dense dialogue examples. Yet, such persona-dense training data are expensive to obtain, leading to a limited scale. This work presents a novel approach to learning from limited training examples by regarding consistency understanding as a regularization of response generation. To this end, we propose a novel stack-propagation framework for learning a generation and understanding pipeline.Specifically, the framework stacks a Transformer encoder and two Transformer decoders, where the first decoder models response generation and the second serves as a regularizer and jointly models response generation and consistency understanding. The proposed framework can benefit from the stacked encoder and decoders to learn from much smaller personalized dialogue data while maintaining competitive performance. Under different low-resource settings, subjective and objective evaluations prove that the stack-propagation framework outperforms strong baselines in response quality and persona consistency and largely overcomes the shortcomings of traditional models that rely heavily on the persona-dense dialogue data.
* published as a journal paper at ACM Transactions on Information Systems 2023. 35 pages, 5 figures
Policy-driven Knowledge Selection and Response Generation for Document-grounded Dialogue
Oct 21, 2024



Document-grounded dialogue (DGD) uses documents as external knowledge for dialogue generation. Correctly understanding the dialogue context is crucial for selecting knowledge from the document and generating proper responses. In this paper, we propose using a dialogue policy to help the dialogue understanding in DGD. Our dialogue policy consists of two kinds of guiding signals: utterance function and topic transfer intent. The utterance function reflects the purpose and style of an utterance, and the topic transfer intent reflects the topic and content of an utterance. We propose a novel framework exploiting our dialogue policy for two core tasks in DGD, namely knowledge selection (KS) and response generation (RG). The framework consists of two modules: the Policy planner leverages policy-aware dialogue representation to select knowledge and predict the policy of the response; the generator uses policy/knowledge-aware dialogue representation for response generation. Our policy-driven model gets state-of-the-art performance on three public benchmarks and we provide a detailed analysis of the experimental results. Our code/data will be released on GitHub.
* 29 pages, 9 figures, 14 tables, TOIS 2024
Accelerating Diffusion Transformers with Token-wise Feature Caching
Oct 14, 2024



Diffusion transformers have shown significant effectiveness in both image and video synthesis at the expense of huge computation costs. To address this problem, feature caching methods have been introduced to accelerate diffusion transformers by caching the features in previous timesteps and reusing them in the following timesteps. However, previous caching methods ignore that different tokens exhibit different sensitivities to feature caching, and feature caching on some tokens may lead to 10$\times$ more destruction to the overall generation quality compared with other tokens. In this paper, we introduce token-wise feature caching, allowing us to adaptively select the most suitable tokens for caching, and further enable us to apply different caching ratios to neural layers in different types and depths. Extensive experiments on PixArt-$\alpha$, OpenSora, and DiT demonstrate our effectiveness in both image and video generation with no requirements for training. For instance, 2.36$\times$ and 1.93$\times$ acceleration are achieved on OpenSora and PixArt-$\alpha$ with almost no drop in generation quality.
Understanding Robustness of Parameter-Efficient Tuning for Image Classification
Oct 13, 2024



Parameter-efficient tuning (PET) techniques calibrate the model's predictions on downstream tasks by freezing the pre-trained models and introducing a small number of learnable parameters. However, despite the numerous PET methods proposed, their robustness has not been thoroughly investigated. In this paper, we systematically explore the robustness of four classical PET techniques (e.g., VPT, Adapter, AdaptFormer, and LoRA) under both white-box attacks and information perturbations. For white-box attack scenarios, we first analyze the performance of PET techniques using FGSM and PGD attacks. Subsequently, we further explore the transferability of adversarial samples and the impact of learnable parameter quantities on the robustness of PET methods. Under information perturbation attacks, we introduce four distinct perturbation strategies, including Patch-wise Drop, Pixel-wise Drop, Patch Shuffle, and Gaussian Noise, to comprehensively assess the robustness of these PET techniques in the presence of information loss. Via these extensive studies, we enhance the understanding of the robustness of PET methods, providing valuable insights for improving their performance in computer vision applications. The code is available at https://github.com/JCruan519/PETRobustness.
Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning
Oct 06, 2024



Instruction Fine-Tuning (IFT) has become an essential method for adapting base Large Language Models (LLMs) into variants for professional and private use. However, researchers have raised concerns over a significant decrease in LLMs' security following IFT, even when the IFT process involves entirely benign instructions (termed Benign IFT). Our study represents a pioneering effort to mitigate the security risks arising from Benign IFT. Specifically, we conduct a Module Robustness Analysis, aiming to investigate how LLMs' internal modules contribute to their security. Based on our analysis, we propose a novel IFT strategy, called the Modular Layer-wise Learning Rate (ML-LR) strategy. In our analysis, we implement a simple security feature classifier that serves as a proxy to measure the robustness of modules (e.g. $Q$/$K$/$V$, etc.). Our findings reveal that the module robustness shows clear patterns, varying regularly with the module type and the layer depth. Leveraging these insights, we develop a proxy-guided search algorithm to identify a robust subset of modules, termed Mods$_{Robust}$. During IFT, the ML-LR strategy employs differentiated learning rates for Mods$_{Robust}$ and the rest modules. Our experimental results show that in security assessments, the application of our ML-LR strategy significantly mitigates the rise in harmfulness of LLMs following Benign IFT. Notably, our ML-LR strategy has little impact on the usability or expertise of LLMs following Benign IFT. Furthermore, we have conducted comprehensive analyses to verify the soundness and flexibility of our ML-LR strategy.
Lens: Rethinking Multilingual Enhancement for Large Language Models
Oct 06, 2024



Despite the growing global demand for large language models (LLMs) that serve users from diverse linguistic backgrounds, most cutting-edge LLMs remain predominantly English-centric. This creates a performance gap across languages, restricting access to advanced AI services for non-English speakers. Current methods to enhance multilingual capabilities largely rely on data-driven post-training techniques, such as multilingual instruction tuning or continual pre-training. However, these approaches encounter significant challenges, including the scarcity of high-quality multilingual datasets and the limited enhancement of multilingual capabilities. They often suffer from off-target issues and catastrophic forgetting of central language abilities. To this end, we propose Lens, a novel approach to enhance multilingual capabilities of LLMs by leveraging their internal language representation spaces. Specially, Lens operates by manipulating the hidden representations within the language-agnostic and language-specific subspaces from top layers of LLMs. Using the central language as a pivot, the target language is drawn closer to it within the language-agnostic subspace, allowing it to inherit well-established semantic representations. Meanwhile, in the language-specific subspace, the representations of the target and central languages are pushed apart, enabling the target language to express itself distinctly. Extensive experiments on one English-centric and two multilingual LLMs demonstrate that Lens effectively improves multilingual performance without sacrificing the original central language capabilities of the backbone model, achieving superior results with much fewer computational resources compared to existing post-training approaches.
$ε$-VAE: Denoising as Visual Decoding
Oct 05, 2024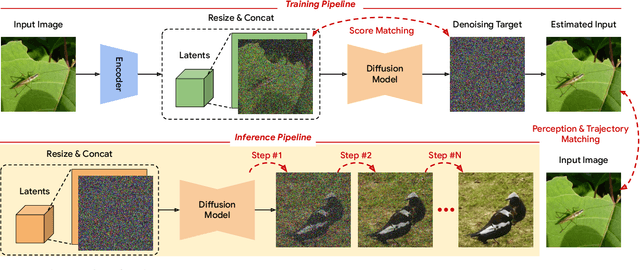
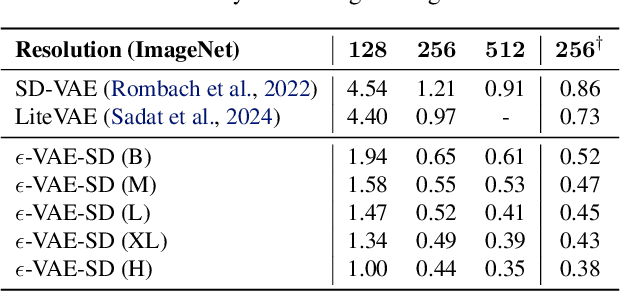
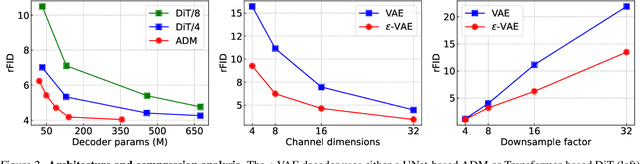
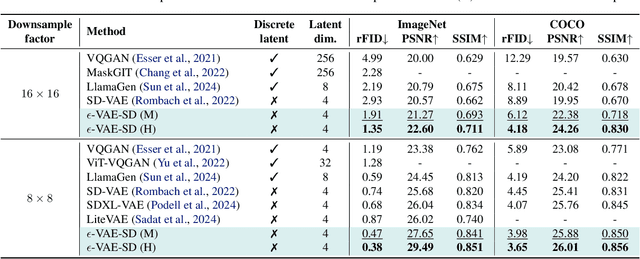
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
Supervised Fine-Tuning: An Activation Pattern Optimization Process for Attention Heads
Sep 24, 2024



Though demonstrating promising potential, LLMs' performance on complex tasks, such as advanced mathematics and complex disease diagnosis is still unsatisfactory. A key issue is the present LLMs learn in a data-driven schema, while the instruction dataset about these complex tasks is both scarce and hard to collect or construct. On the contrary, a prominent phenomenon is that LLMs can learn rather fast on those simpler tasks with adequate prior knowledge captured during pretraining stage. Thus, if the prerequisite and mechanism of such rapid generalization could be elucidated, it could be highly beneficial in enhancing the efficiency and effectiveness of the LLM's ability to learn complex tasks. Thus, in this paper, we employ a gradient-based method, to dissect the process that the SFT process adapts LLMs to downstream tasks via the perspective of attention patterns. We find that: (1) LLMs selectively activate task-specific attention heads during SFT; (2) activation patterns for complex tasks are combinations of basic task patterns; and (3) changes in a few parameters can significantly impact activation patterns after SFT on a small number of samples. Based on these insights, we conduct experiments to examine whether these conclusions could effectively enhance the efficiency and effectiveness of SFT, particularly in handling complex tasks and when instructional resources are scarce. Our research not only uncovers the underlying reasons behind LLMs' rapid learning and generalization mechanisms but also provides practical solutions for addressing data challenges in complex and specialized tasks.