 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Dynamic Boltzmann Softmax Updates
Mar 15, 2019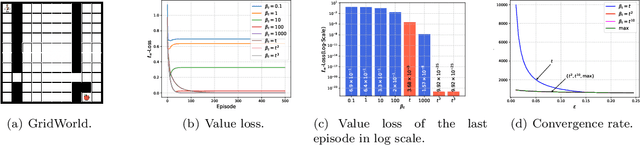
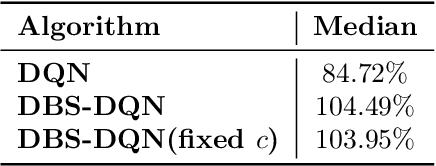
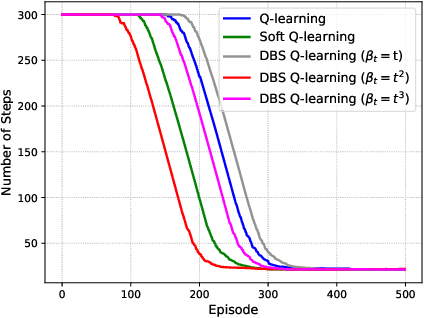
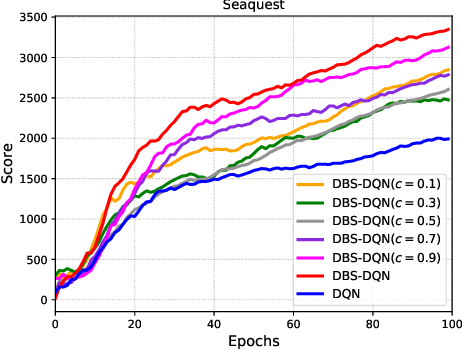
Value function estimation is an important task in reinforcement learning, i.e., prediction. The commonly used operator for prediction in Q-learning is the hard max operator, which always commits to the maximum action-value according to current estimation. Such `hard' updating scheme results in pure exploitation and may lead to misbehavior due to noise in stochastic environments. Thus, it is critical to balancing exploration and exploitation in value function estimation. The Boltzmann softmax operator has a greater capability in exploring potential action-values. However, it does not satisfy the non-expansion property, and its direct use may fail to converge even in value iteration. In this paper, we propose to update the value function with dynamic Boltzmann softmax (DBS) operator in value function estimation, which has good convergence property in the setting of planning and learning. Moreover, we prove that dynamic Boltzmann softmax updates can eliminate the overestimation phenomenon introduced by the hard max operator. Experimental results on GridWorld show that the DBS operator enables convergence and a better trade-off between exploration and exploitation in value function estimation. Finally, we propose the DBS-DQN algorithm by generalizing the dynamic Boltzmann softmax update in deep Q-network, which outperforms DQN substantially in 40 out of 49 Atari games.
Positively Scale-Invariant Flatness of ReLU Neural Networks
Mar 06, 2019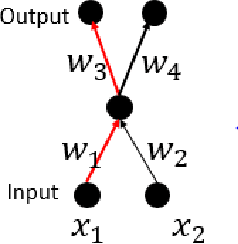
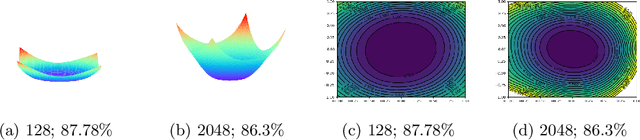
It was empirically confirmed by Keskar et al.\cite{SharpMinima} that flatter minima generalize better. However, for the popular ReLU network, sharp minimum can also generalize well \cite{SharpMinimacan}. The conclusion demonstrates that the existing definitions of flatness fail to account for the complex geometry of ReLU neural networks because they can't cover the Positively Scale-Invariant (PSI) property of ReLU network. In this paper, we formalize the PSI causes problem of existing definitions of flatness and propose a new description of flatness - \emph{PSI-flatness}. PSI-flatness is defined on the values of basis paths \cite{GSGD} instead of weights. Values of basis paths have been shown to be the PSI-variables and can sufficiently represent the ReLU neural networks which ensure the PSI property of PSI-flatness. Then we study the relation between PSI-flatness and generalization theoretically and empirically. First, we formulate a generalization bound based on PSI-flatness which shows generalization error decreasing with the ratio between the largest basis path value and the smallest basis path value. That is to say, the minimum with balanced values of basis paths will more likely to be flatter and generalize better. Finally. we visualize the PSI-flatness of loss surface around two learned models which indicates the minimum with smaller PSI-flatness can indeed generalize better.
A Cooperative Multi-Agent Reinforcement Learning Framework for Resource Balancing in Complex Logistics Network
Mar 02, 2019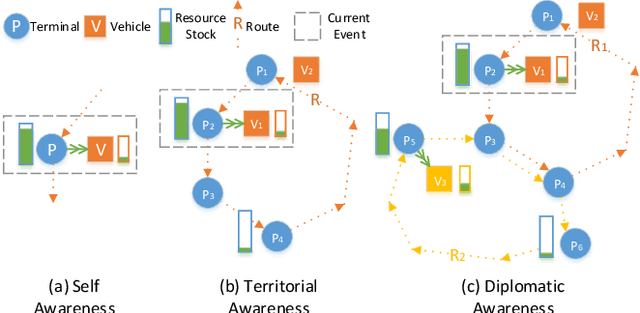
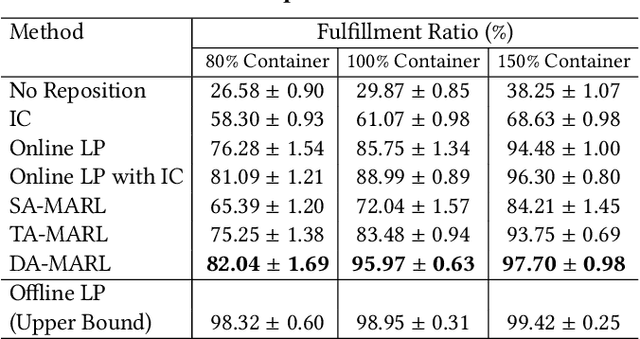

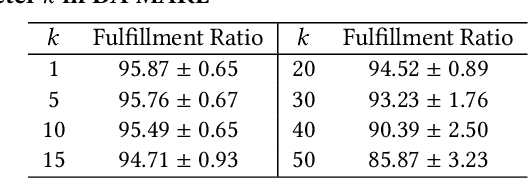
Resource balancing within complex transportation networks is one of the most important problems in real logistics domain. Traditional solutions on these problems leverage combinatorial optimization with demand and supply forecasting. However, the high complexity of transportation routes, severe uncertainty of future demand and supply, together with non-convex business constraints make it extremely challenging in the traditional resource management field. In this paper, we propose a novel sophisticated multi-agent reinforcement learning approach to address these challenges. In particular, inspired by the externalities especially the interactions among resource agents, we introduce an innovative cooperative mechanism for state and reward design resulting in more effective and efficient transportation. Extensive experiments on a simulated ocean transportation service demonstrate that our new approach can stimulate cooperation among agents and lead to much better performance. Compared with traditional solutions based on combinatorial optimization, our approach can give rise to a significant improvement in terms of both performance and stability.
Multilingual Neural Machine Translation with Knowledge Distillation
Feb 28, 2019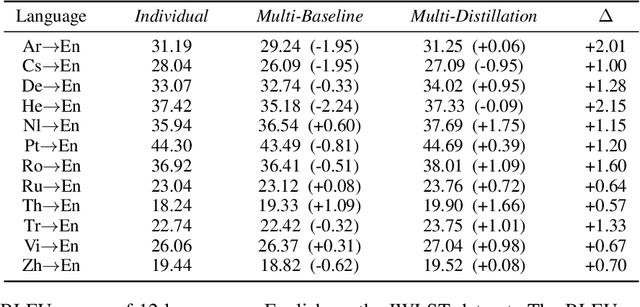
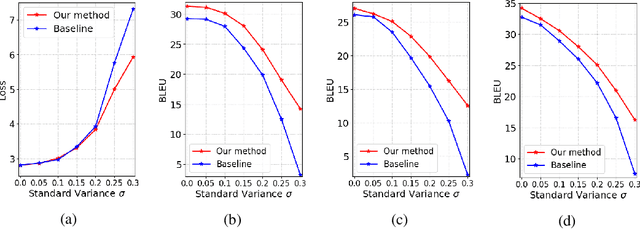
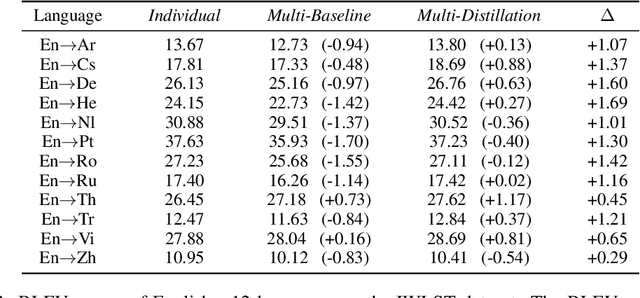

Multilingual machine translation, which translates multiple languages with a single model, has attracted much attention due to its efficiency of offline training and online serving. However, traditional multilingual translation usually yields inferior accuracy compared with the counterpart using individual models for each language pair, due to language diversity and model capacity limitations. In this paper, we propose a distillation-based approach to boost the accuracy of multilingual machine translation. Specifically, individual models are first trained and regarded as teachers, and then the multilingual model is trained to fit the training data and match the outputs of individual models simultaneously through knowledge distillation. Experiments on IWSLT, WMT and Ted talk translation datasets demonstrate the effectiveness of our method. Particularly, we show that one model is enough to handle multiple languages (up to 44 languages in our experiment), with comparable or even better accuracy than individual models.
Non-Autoregressive Machine Translation with Auxiliary Regularization
Feb 22, 2019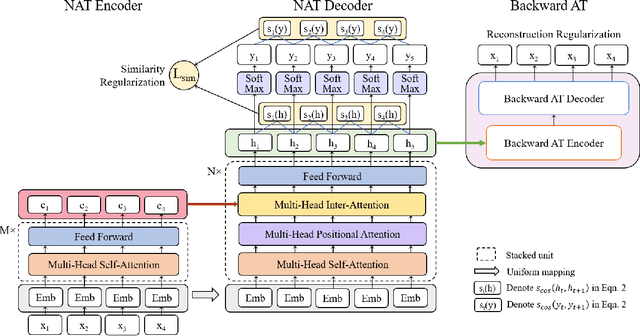
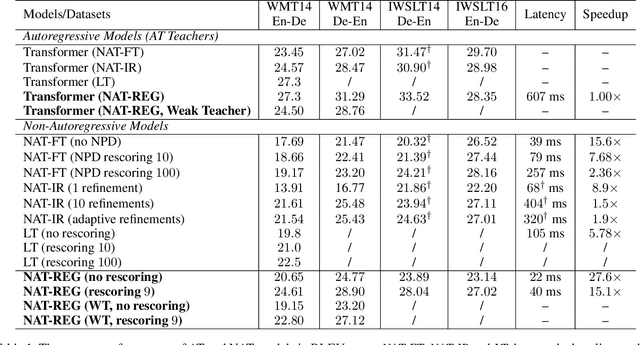


As a new neural machine translation approach, Non-Autoregressive machine Translation (NAT) has attracted attention recently due to its high efficiency in inference. However, the high efficiency has come at the cost of not capturing the sequential dependency on the target side of translation, which causes NAT to suffer from two kinds of translation errors: 1) repeated translations (due to indistinguishable adjacent decoder hidden states), and 2) incomplete translations (due to incomplete transfer of source side information via the decoder hidden states). In this paper, we propose to address these two problems by improving the quality of decoder hidden representations via two auxiliary regularization terms in the training process of an NAT model. First, to make the hidden states more distinguishable, we regularize the similarity between consecutive hidden states based on the corresponding target tokens. Second, to force the hidden states to contain all the information in the source sentence, we leverage the dual nature of translation tasks (e.g., English to German and German to English) and minimize a backward reconstruction error to ensure that the hidden states of the NAT decoder are able to recover the source side sentence. Extensive experiments conducted on several benchmark datasets show that both regularization strategies are effective and can alleviate the issues of repeated translations and incomplete translations in NAT models. The accuracy of NAT models is therefore improved significantly over the state-of-the-art NAT models with even better efficiency for inference.
Non-Autoregressive Neural Machine Translation with Enhanced Decoder Input
Dec 23, 2018
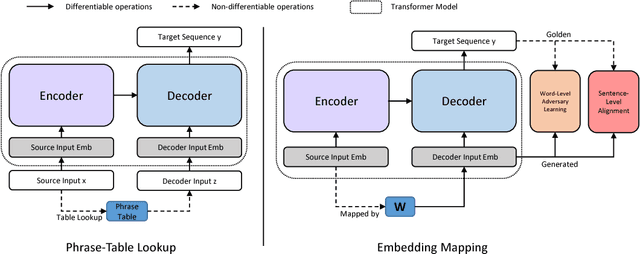
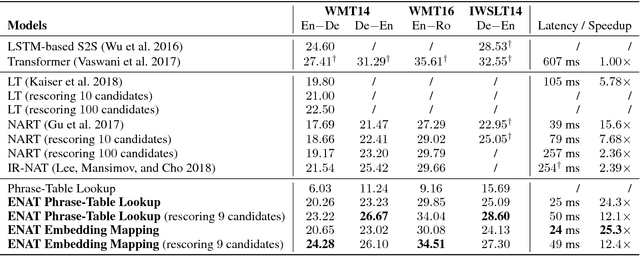
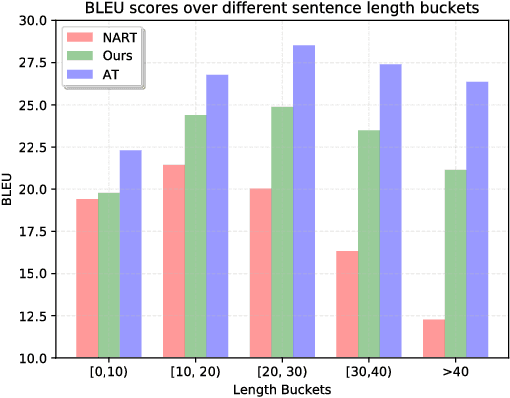
Non-autoregressive translation (NAT) models, which remove the dependence on previous target tokens from the inputs of the decoder, achieve significantly inference speedup but at the cost of inferior accuracy compared to autoregressive translation (AT) models. Previous work shows that the quality of the inputs of the decoder is important and largely impacts the model accuracy. In this paper, we propose two methods to enhance the decoder inputs so as to improve NAT models. The first one directly leverages a phrase table generated by conventional SMT approaches to translate source tokens to target tokens, which are then fed into the decoder as inputs. The second one transforms source-side word embeddings to target-side word embeddings through sentence-level alignment and word-level adversary learning, and then feeds the transformed word embeddings into the decoder as inputs. Experimental results show our method largely outperforms the NAT baseline~\citep{gu2017non} by $5.11$ BLEU scores on WMT14 English-German task and $4.72$ BLEU scores on WMT16 English-Romanian task.
Modeling Local Dependence in Natural Language with Multi-channel Recurrent Neural Networks
Nov 13, 2018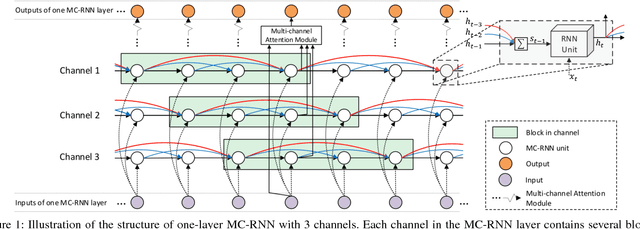

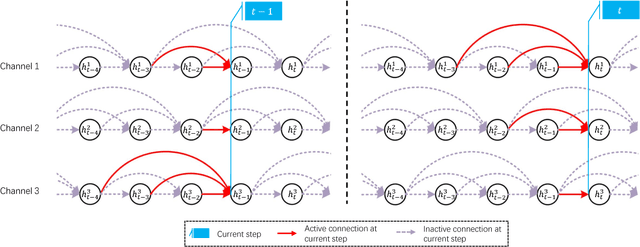
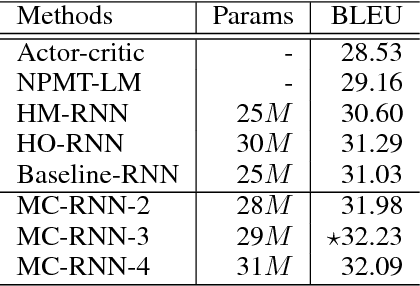
Recurrent Neural Networks (RNNs) have been widely used in processing natural language tasks and achieve huge success. Traditional RNNs usually treat each token in a sentence uniformly and equally. However, this may miss the rich semantic structure information of a sentence, which is useful for understanding natural languages. Since semantic structures such as word dependence patterns are not parameterized, it is a challenge to capture and leverage structure information. In this paper, we propose an improved variant of RNN, Multi-Channel RNN (MC-RNN), to dynamically capture and leverage local semantic structure information. Concretely, MC-RNN contains multiple channels, each of which represents a local dependence pattern at a time. An attention mechanism is introduced to combine these patterns at each step, according to the semantic information. Then we parameterize structure information by adaptively selecting the most appropriate connection structures among channels. In this way, diverse local structures and dependence patterns in sentences can be well captured by MC-RNN. To verify the effectiveness of MC-RNN, we conduct extensive experiments on typical natural language processing tasks, including neural machine translation, abstractive summarization, and language modeling. Experimental results on these tasks all show significant improvements of MC-RNN over current top systems.
Neural Architecture Optimization
Oct 31, 2018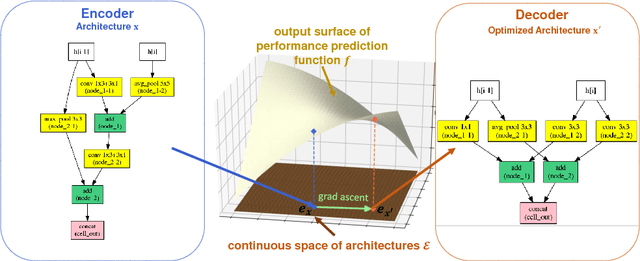
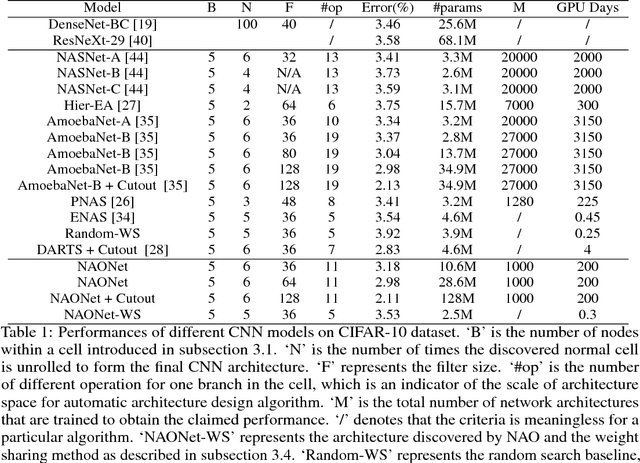
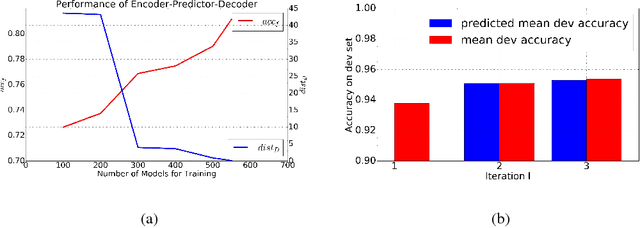
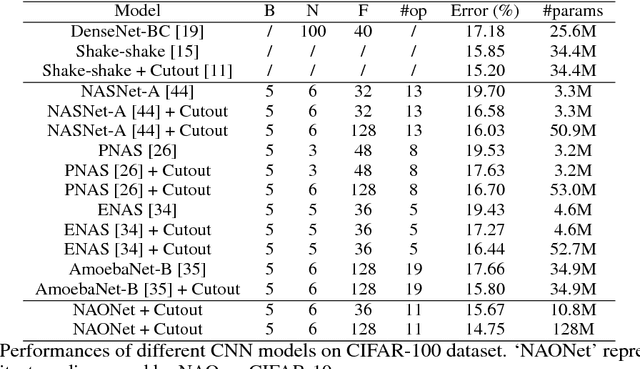
Automatic neural architecture design has shown its potential in discovering powerful neural network architectures. Existing methods, no matter based on reinforcement learning or evolutionary algorithms (EA), conduct architecture search in a discrete space, which is highly inefficient. In this paper, we propose a simple and efficient method to automatic neural architecture design based on continuous optimization. We call this new approach neural architecture optimization (NAO). There are three key components in our proposed approach: (1) An encoder embeds/maps neural network architectures into a continuous space. (2) A predictor takes the continuous representation of a network as input and predicts its accuracy. (3) A decoder maps a continuous representation of a network back to its architecture. The performance predictor and the encoder enable us to perform gradient based optimization in the continuous space to find the embedding of a new architecture with potentially better accuracy. Such a better embedding is then decoded to a network by the decoder. Experiments show that the architecture discovered by our method is very competitive for image classification task on CIFAR-10 and language modeling task on PTB, outperforming or on par with the best results of previous architecture search methods with a significantly reduction of computational resources. Specifically we obtain $2.11\%$ test set error rate for CIFAR-10 image classification task and $56.0$ test set perplexity of PTB language modeling task. Furthermore, combined with the recent proposed weight sharing mechanism, we discover powerful architecture on CIFAR-10 (with error rate $3.53\%$) and on PTB (with test set perplexity $56.6$), with very limited computational resources (less than $10$ GPU hours) for both tasks.
Learning to Teach with Dynamic Loss Functions
Oct 29, 2018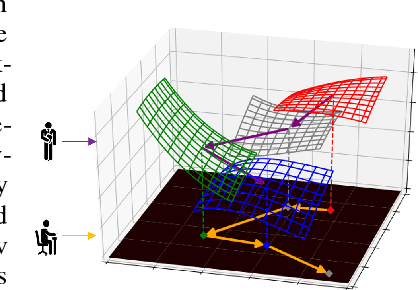
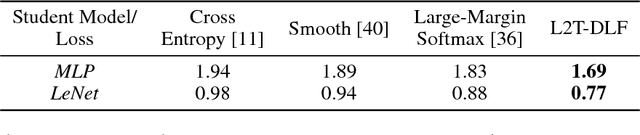
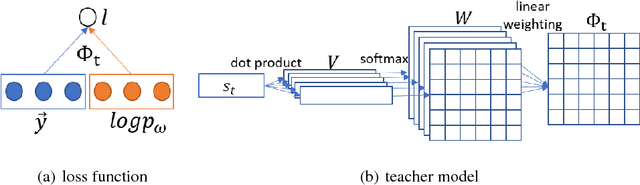
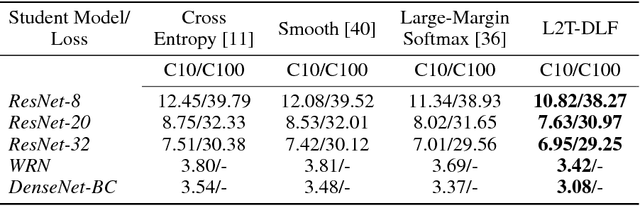
Teaching is critical to human society: it is with teaching that prospective students are educated and human civilization can be inherited and advanced. A good teacher not only provides his/her students with qualified teaching materials (e.g., textbooks), but also sets up appropriate learning objectives (e.g., course projects and exams) considering different situations of a student. When it comes to artificial intelligence, treating machine learning models as students, the loss functions that are optimized act as perfect counterparts of the learning objective set by the teacher. In this work, we explore the possibility of imitating human teaching behaviors by dynamically and automatically outputting appropriate loss functions to train machine learning models. Different from typical learning settings in which the loss function of a machine learning model is predefined and fixed, in our framework, the loss function of a machine learning model (we call it student) is defined by another machine learning model (we call it teacher). The ultimate goal of teacher model is cultivating the student to have better performance measured on development dataset. Towards that end, similar to human teaching, the teacher, a parametric model, dynamically outputs different loss functions that will be used and optimized by its student model at different training stages. We develop an efficient learning method for the teacher model that makes gradient based optimization possible, exempt of the ineffective solutions such as policy optimization. We name our method as "learning to teach with dynamic loss functions" (L2T-DLF for short). Extensive experiments on real world tasks including image classification and neural machine translation demonstrate that our method significantly improves the quality of various student models.
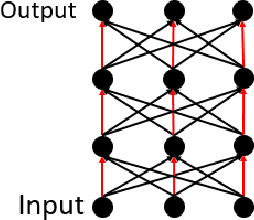
$\mathcal{G}$-SGD: Optimizing ReLU Neural Networks in its Positively Scale-Invariant Space
Oct 09, 2018



It is well known that neural networks with rectified linear units (ReLU) activation functions are positively scale-invariant. Conventional algorithms like stochastic gradient descent optimize the neural networks in the vector space of weights, which is, however, not positively scale-invariant. This mismatch may lead to problems during the optimization process. Then, a natural question is: \emph{can we construct a new vector space that is positively scale-invariant and sufficient to represent ReLU neural networks so as to better facilitate the optimization process }? In this paper, we provide our positive answer to this question. First, we conduct a formal study on the positive scaling operators which forms a transformation group, denoted as $\mathcal{G}$. We show that the value of a path (i.e. the product of the weights along the path) in the neural network is invariant to positive scaling and prove that the value vector of all the paths is sufficient to represent the neural networks under mild conditions. Second, we show that one can identify some basis paths out of all the paths and prove that the linear span of their value vectors (denoted as $\mathcal{G}$-space) is an invariant space with lower dimension under the positive scaling group. Finally, we design stochastic gradient descent algorithm in $\mathcal{G}$-space (abbreviated as $\mathcal{G}$-SGD) to optimize the value vector of the basis paths of neural networks with little extra cost by leveraging back-propagation. Our experiments show that $\mathcal{G}$-SGD significantly outperforms the conventional SGD algorithm in optimizing ReLU networks on benchmark datasets.