 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Distributed Stochastic Variance Reduced Methods without Sampling Extra Data
May 29, 2019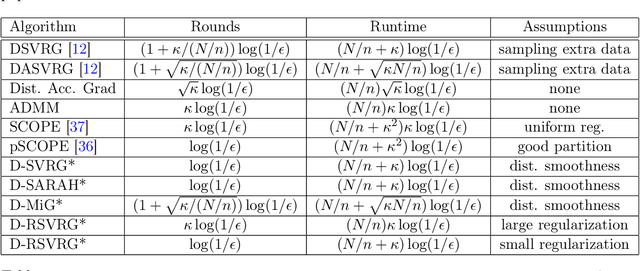
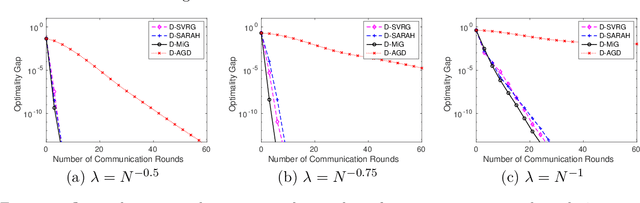
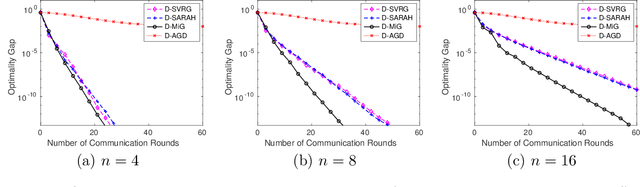
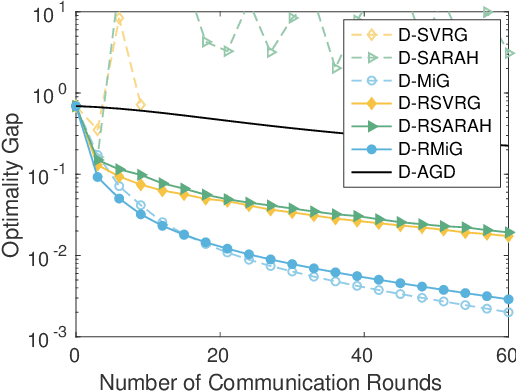
Stochastic variance reduced methods have gained a lot of interest recently for empirical risk minimization due to its appealing run time complexity. When the data size is large and disjointly stored on different machines, it becomes imperative to distribute the implementation of such variance reduced methods. In this paper, we consider a general framework that directly distributes popular stochastic variance reduced methods, by assigning outer loops to the parameter server, and inner loops to worker machines. This framework is natural as it does not require sampling extra data and is friendly to implement, but its theoretical convergence is not well understood. We obtain a unified understanding of the convergence for algorithms under this framework by measuring the smoothness of the discrepancy between the local and global loss functions. We establish the linear convergence of distributed versions of a family of stochastic variance reduced algorithms, including those using accelerated and recursive gradient updates, for minimizing strongly convex losses. Our theory captures how the convergence of distributed algorithms behaves as the number of machines and the size of local data vary. Furthermore, we show that when the smoothness discrepancy between local and global loss functions is large, regularization can be used to ensure convergence. Our analysis can be further extended to handle nonsmooth and nonconvex loss functions.
FastSpeech: Fast, Robust and Controllable Text to Speech
May 29, 2019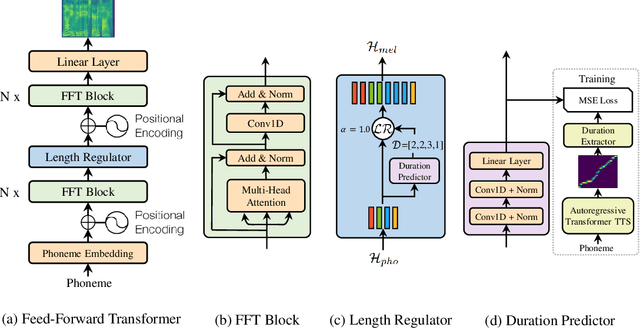


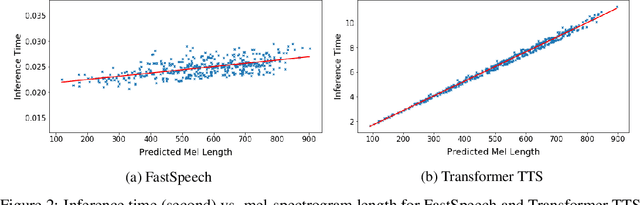
Neural network based end-to-end text to speech (TTS) has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron 2) usually first generate mel-spectrogram from text, and then synthesize speech from mel-spectrogram using vocoder such as WaveNet. Compared with traditional concatenative and statistical parametric approaches, neural network based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust (i.e., some words are skipped or repeated) and lack of controllability (voice speed or prosody control). In this work, we propose a novel feed-forward network based on Transformer to generate mel-spectrogram in parallel for TTS. Specifically, we extract attention alignments from an encoder-decoder based teacher model for phoneme duration prediction, which is used by a length regulator to expand the source phoneme sequence to match the length of target mel-spectrogram sequence for parallel mel-spectrogram generation. Experiments on the LJSpeech dataset show that our parallel model matches autoregressive models in terms of speech quality, nearly eliminates the problem of word skipping and repeating in particularly hard cases, and can adjust voice speed smoothly. Most importantly, compared with autoregressive Transformer TTS, our model speeds up the mel-spectrogram generation by 270x and the end-to-end speech synthesis by 38x. Therefore, we call our model FastSpeech. We will release the code on Github. Synthesized speech samples can be found in https://speechresearch.github.io/fastspeech/.
Beyond Exponentially Discounted Sum: Automatic Learning of Return Function
May 28, 2019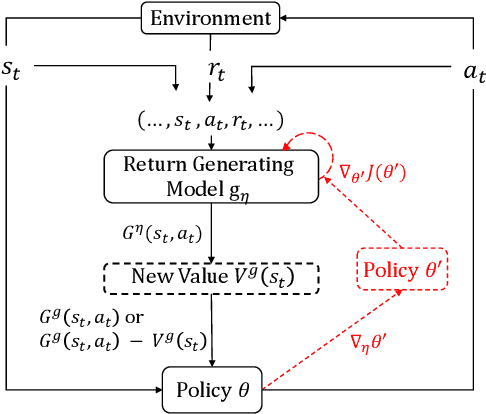
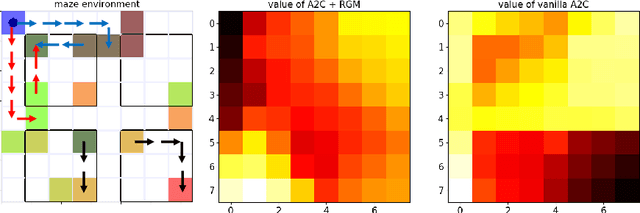
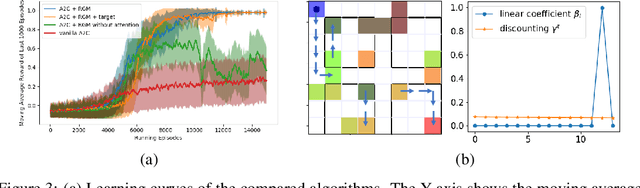
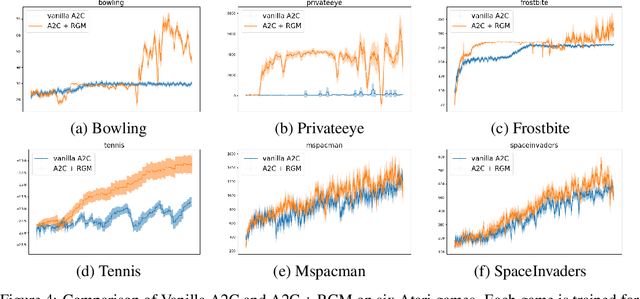
In reinforcement learning, Return, which is the weighted accumulated future rewards, and Value, which is the expected return, serve as the objective that guides the learning of the policy. In classic RL, return is defined as the exponentially discounted sum of future rewards. One key insight is that there could be many feasible ways to define the form of the return function (and thus the value), from which the same optimal policy can be derived, yet these different forms might render dramatically different speeds of learning this policy. In this paper, we research how to modify the form of the return function to enhance the learning towards the optimal policy. We propose to use a general mathematical form for return function, and employ meta-learning to learn the optimal return function in an end-to-end manner. We test our methods on a specially designed maze environment and several Atari games, and our experimental results clearly indicate the advantages of automatically learning optimal return functions in reinforcement learning.
Learning Efficient and Effective Exploration Policies with Counterfactual Meta Policy
May 28, 2019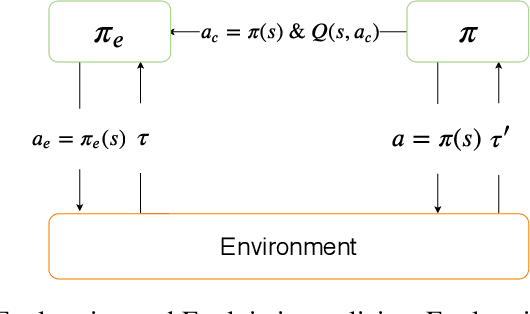
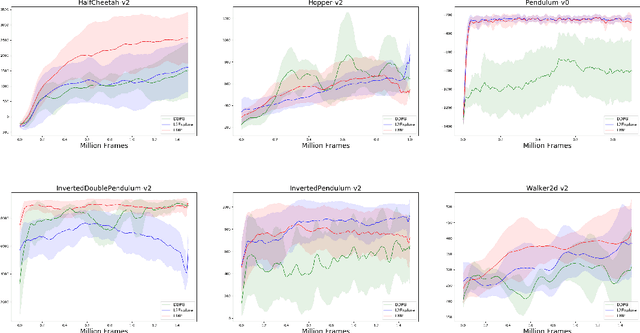
A fundamental issue in reinforcement learning algorithms is the balance between exploration of the environment and exploitation of information already obtained by the agent. Especially, exploration has played a critical role for both efficiency and efficacy of the learning process. However, Existing works for exploration involve task-agnostic design, that is performing well in one environment, but be ill-suited to another. To the purpose of learning an effective and efficient exploration policy in an automated manner. We formalized a feasible metric for measuring the utility of exploration based on counterfactual ideology. Based on that, We proposed an end-to-end algorithm to learn exploration policy by meta-learning. We demonstrate that our method achieves good results compared to previous works in the high-dimensional control tasks in MuJoCo simulator.
Soft Contextual Data Augmentation for Neural Machine Translation
May 25, 2019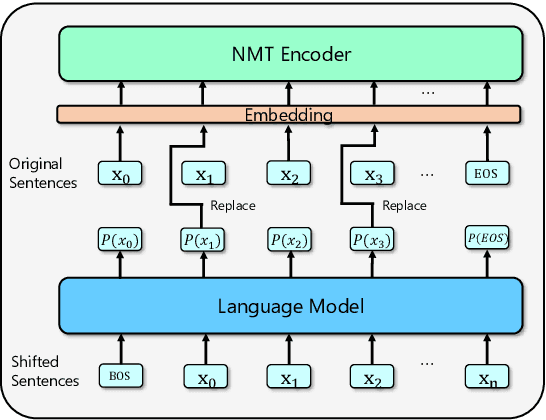
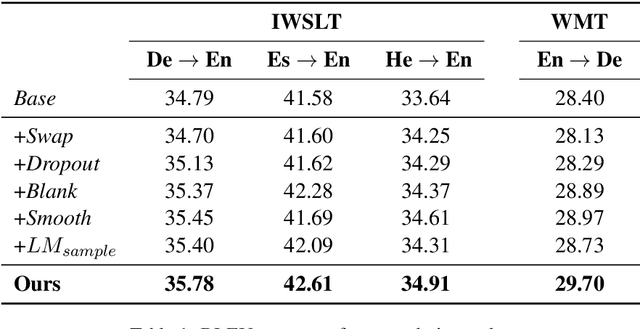
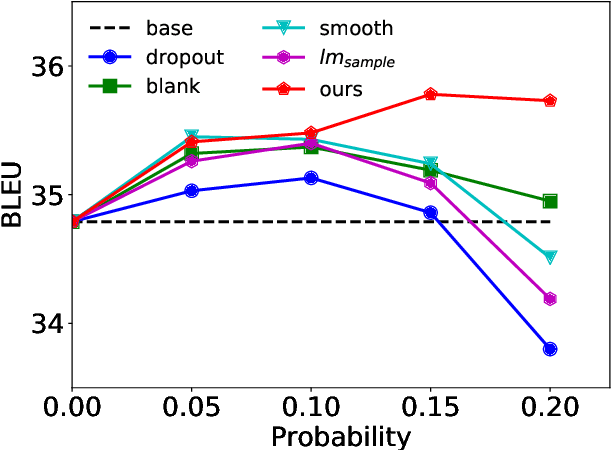
While data augmentation is an important trick to boost the accuracy of deep learning methods in computer vision tasks, its study in natural language tasks is still very limited. In this paper, we present a novel data augmentation method for neural machine translation. Different from previous augmentation methods that randomly drop, swap or replace words with other words in a sentence, we softly augment a randomly chosen word in a sentence by its contextual mixture of multiple related words. More accurately, we replace the one-hot representation of a word by a distribution (provided by a language model) over the vocabulary, i.e., replacing the embedding of this word by a weighted combination of multiple semantically similar words. Since the weights of those words depend on the contextual information of the word to be replaced, the newly generated sentences capture much richer information than previous augmentation methods. Experimental results on both small scale and large scale machine translation datasets demonstrate the superiority of our method over strong baselines.
Almost Unsupervised Text to Speech and Automatic Speech Recognition
May 22, 2019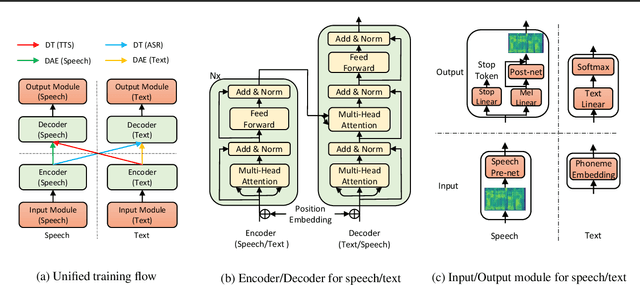
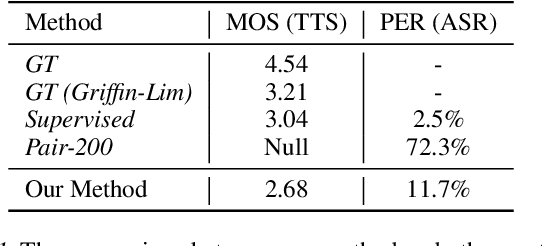
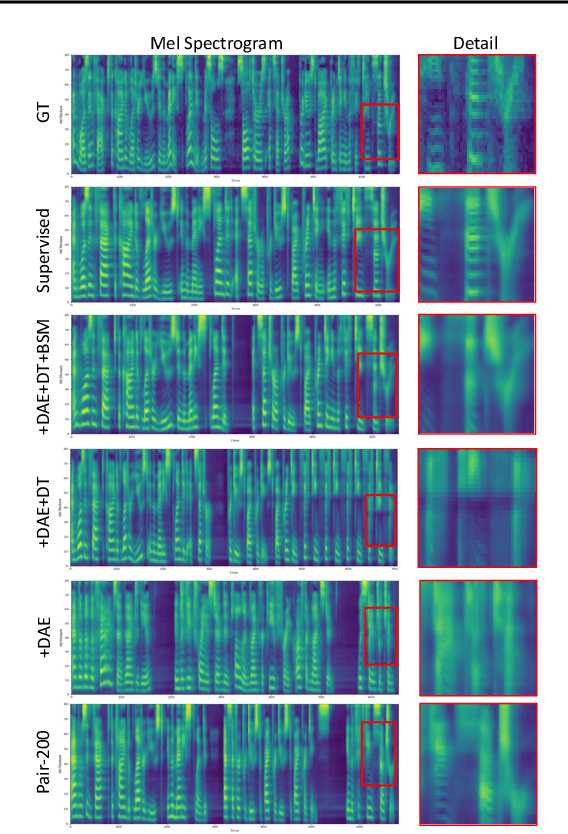

Text to speech (TTS) and automatic speech recognition (ASR) are two dual tasks in speech processing and both achieve impressive performance thanks to the recent advance in deep learning and large amount of aligned speech and text data. However, the lack of aligned data poses a major practical problem for TTS and ASR on low-resource languages. In this paper, by leveraging the dual nature of the two tasks, we propose an almost unsupervised learning method that only leverages few hundreds of paired data and extra unpaired data for TTS and ASR. Our method consists of the following components: (1) a denoising auto-encoder, which reconstructs speech and text sequences respectively to develop the capability of language modeling both in speech and text domain; (2) dual transformation, where the TTS model transforms the text $y$ into speech $\hat{x}$, and the ASR model leverages the transformed pair $(\hat{x},y)$ for training, and vice versa, to boost the accuracy of the two tasks; (3) bidirectional sequence modeling, which addresses error propagation especially in the long speech and text sequence when training with few paired data; (4) a unified model structure, which combines all the above components for TTS and ASR based on Transformer model. Our method achieves 99.84% in terms of word level intelligible rate and 2.68 MOS for TTS, and 11.7% PER for ASR on LJSpeech dataset, by leveraging only 200 paired speech and text data (about 20 minutes audio), together with extra unpaired speech and text data.
MASS: Masked Sequence to Sequence Pre-training for Language Generation
May 13, 2019
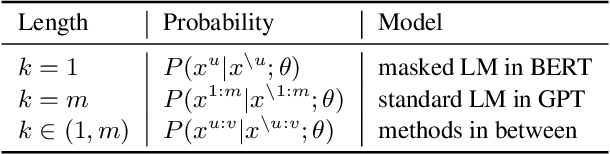

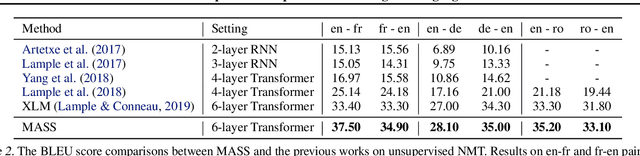
Pre-training and fine-tuning, e.g., BERT, have achieved great success in language understanding by transferring knowledge from rich-resource pre-training task to the low/zero-resource downstream tasks. Inspired by the success of BERT, we propose MAsked Sequence to Sequence pre-training (MASS) for the encoder-decoder based language generation tasks. MASS adopts the encoder-decoder framework to reconstruct a sentence fragment given the remaining part of the sentence: its encoder takes a sentence with randomly masked fragment (several consecutive tokens) as input, and its decoder tries to predict this masked fragment. In this way, MASS can jointly train the encoder and decoder to develop the capability of representation extraction and language modeling. By further fine-tuning on a variety of zero/low-resource language generation tasks, including neural machine translation, text summarization and conversational response generation (3 tasks and totally 8 datasets), MASS achieves significant improvements over the baselines without pre-training or with other pre-training methods. Specially, we achieve the state-of-the-art accuracy (37.5 in terms of BLEU score) on the unsupervised English-French translation, even beating the early attention-based supervised model.
Adaptive Regret of Convex and Smooth Functions
May 09, 2019
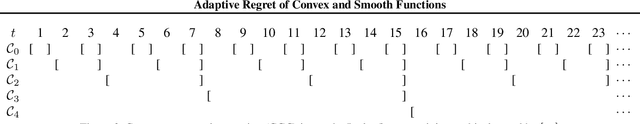

We investigate online convex optimization in changing environments, and choose the adaptive regret as the performance measure. The goal is to achieve a small regret over every interval so that the comparator is allowed to change over time. Different from previous works that only utilize the convexity condition, this paper further exploits smoothness to improve the adaptive regret. To this end, we develop novel adaptive algorithms for convex and smooth functions, and establish problem-dependent regret bounds over any interval. Our regret bounds are comparable to existing results in the worst case, and become much tighter when the comparator has a small loss.
Token-Level Ensemble Distillation for Grapheme-to-Phoneme Conversion
Apr 06, 2019
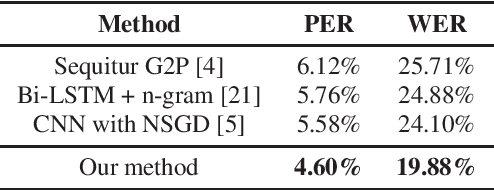


Grapheme-to-phoneme (G2P) conversion is an important task in automatic speech recognition and text-to-speech systems. Recently, G2P conversion is viewed as a sequence to sequence task and modeled by RNN or CNN based encoder-decoder framework. However, previous works do not consider the practical issues when deploying G2P model in the production system, such as how to leverage additional unlabeled data to boost the accuracy, as well as reduce model size for online deployment. In this work, we propose token-level ensemble distillation for G2P conversion, which can (1) boost the accuracy by distilling the knowledge from additional unlabeled data, and (2) reduce the model size but maintain the high accuracy, both of which are very practical and helpful in the online production system. We use token-level knowledge distillation, which results in better accuracy than the sequence-level counterpart. What is more, we adopt the Transformer instead of RNN or CNN based models to further boost the accuracy of G2P conversion. Experiments on the publicly available CMUDict dataset and an internal English dataset demonstrate the effectiveness of our proposed method. Particularly, our method achieves 19.88% WER on CMUDict dataset, outperforming the previous works by more than 4.22% WER, and setting the new state-of-the-art results.
Training Over-parameterized Deep ResNet Is almost as Easy as Training a Two-layer Network
Mar 17, 2019
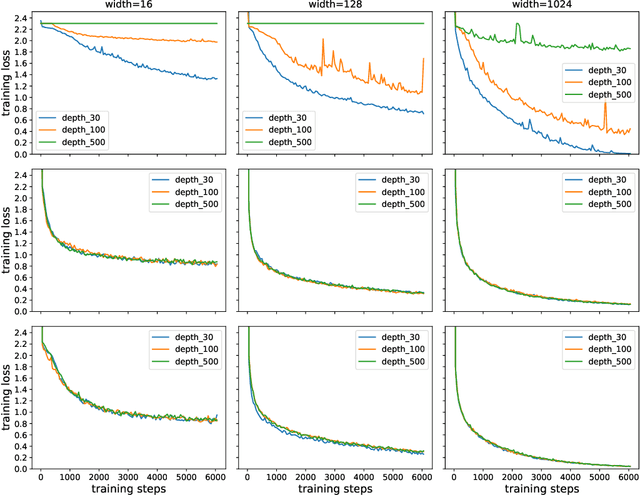
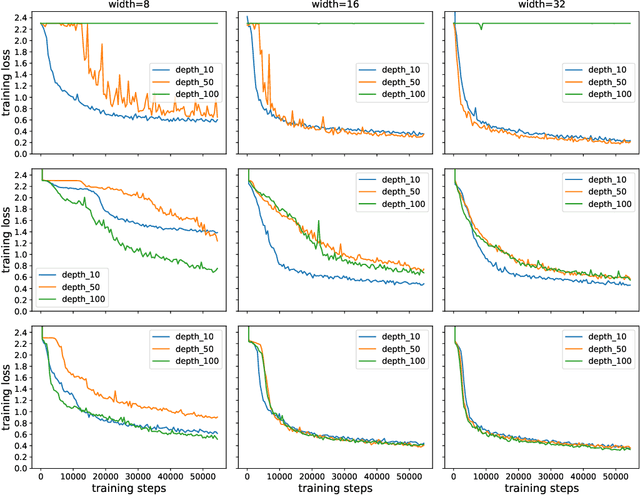
It has been proved that gradient descent converges linearly to the global minima for training deep neural network in the over-parameterized regime. However, according to \citet{allen2018convergence}, the width of each layer should grow at least with the polynomial of the depth (the number of layers) for residual network (ResNet) in order to guarantee the linear convergence of gradient descent, which shows no obvious advantage over feedforward network. In this paper, we successfully remove the dependence of the width on the depth of the network for ResNet and reach a conclusion that training deep residual network can be as easy as training a two-layer network. This theoretically justifies the benefit of skip connection in terms of facilitating the convergence of gradient descent. Our experiments also justify that the width of ResNet to guarantee successful training is much smaller than that of deep feedforward neural network.