 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
May 30, 2024



Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
Mar 25, 2024



In recent years, there has been significant progress in the development of text-to-image generative models. Evaluating the quality of the generative models is one essential step in the development process. Unfortunately, the evaluation process could consume a significant amount of computational resources, making the required periodic evaluation of model performance (e.g., monitoring training progress) impractical. Therefore, we seek to improve the evaluation efficiency by selecting the representative subset of the text-image dataset. We systematically investigate the design choices, including the selection criteria (textural features or image-based metrics) and the selection granularity (prompt-level or set-level). We find that the insights from prior work on subset selection for training data do not generalize to this problem, and we propose FlashEval, an iterative search algorithm tailored to evaluation data selection. We demonstrate the effectiveness of FlashEval on ranking diffusion models with various configurations, including architectures, quantization levels, and sampler schedules on COCO and DiffusionDB datasets. Our searched 50-item subset could achieve comparable evaluation quality to the randomly sampled 500-item subset for COCO annotations on unseen models, achieving a 10x evaluation speedup. We release the condensed subset of these commonly used datasets to help facilitate diffusion algorithm design and evaluation, and open-source FlashEval as a tool for condensing future datasets, accessible at https://github.com/thu-nics/FlashEval.
Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection
Jul 17, 2023
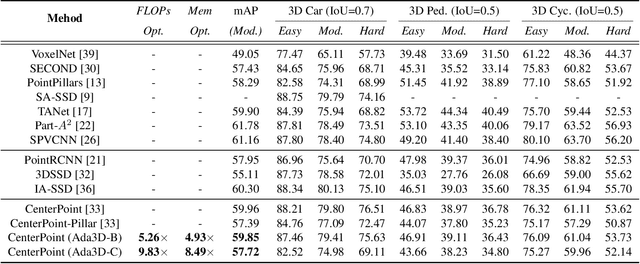

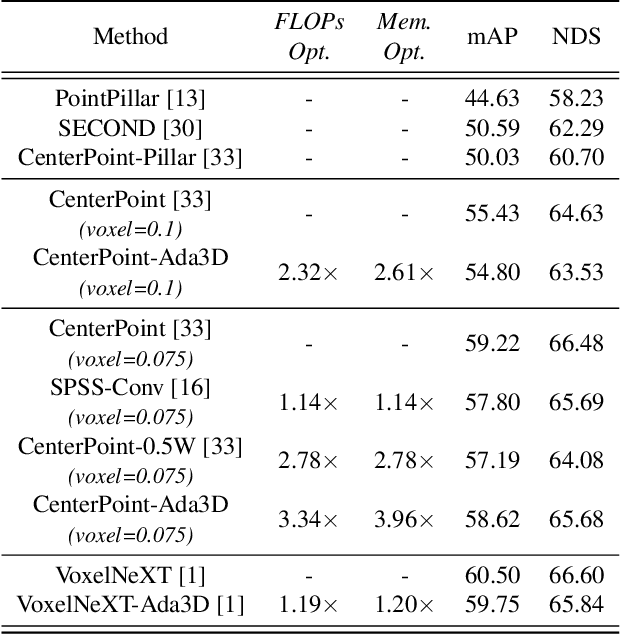
Voxel-based methods have achieved state-of-the-art performance for 3D object detection in autonomous driving. However, their significant computational and memory costs pose a challenge for their application to resource-constrained vehicles. One reason for this high resource consumption is the presence of a large number of redundant background points in Lidar point clouds, resulting in spatial redundancy in both 3D voxel and dense BEV map representations. To address this issue, we propose an adaptive inference framework called Ada3D, which focuses on exploiting the input-level spatial redundancy. Ada3D adaptively filters the redundant input, guided by a lightweight importance predictor and the unique properties of the Lidar point cloud. Additionally, we utilize the BEV features' intrinsic sparsity by introducing the Sparsity Preserving Batch Normalization. With Ada3D, we achieve 40% reduction for 3D voxels and decrease the density of 2D BEV feature maps from 100% to 20% without sacrificing accuracy. Ada3D reduces the model computational and memory cost by 5x, and achieves 1.52x/1.45x end-to-end GPU latency and 1.5x/4.5x GPU peak memory optimization for the 3D and 2D backbone respectively.
Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS "Cold-Start"
Feb 02, 2023Predictor-based Neural Architecture Search (NAS) employs an architecture performance predictor to improve the sample efficiency. However, predictor-based NAS suffers from the severe ``cold-start'' problem, since a large amount of architecture-performance data is required to get a working predictor. In this paper, we focus on exploiting information in cheaper-to-obtain performance estimations (i.e., low-fidelity information) to mitigate the large data requirements of predictor training. Despite the intuitiveness of this idea, we observe that using inappropriate low-fidelity information even damages the prediction ability and different search spaces have different preferences for low-fidelity information types. To solve the problem and better fuse beneficial information provided by different types of low-fidelity information, we propose a novel dynamic ensemble predictor framework that comprises two steps. In the first step, we train different sub-predictors on different types of available low-fidelity information to extract beneficial knowledge as low-fidelity experts. In the second step, we learn a gating network to dynamically output a set of weighting coefficients conditioned on each input neural architecture, which will be used to combine the predictions of different low-fidelity experts in a weighted sum. The overall predictor is optimized on a small set of actual architecture-performance data to fuse the knowledge from different low-fidelity experts to make the final prediction. We conduct extensive experiments across five search spaces with different architecture encoders under various experimental settings. Our method can easily be incorporated into existing predictor-based NAS frameworks to discover better architectures.
Scalable neural quantum states architecture for quantum chemistry
Aug 11, 2022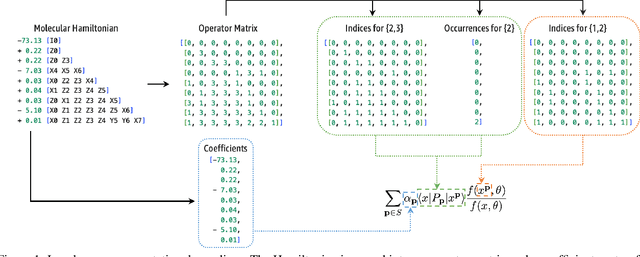
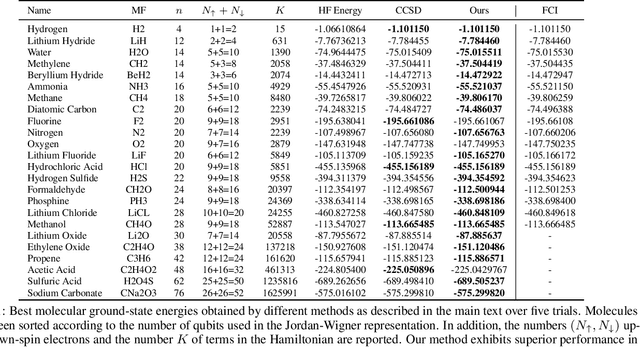
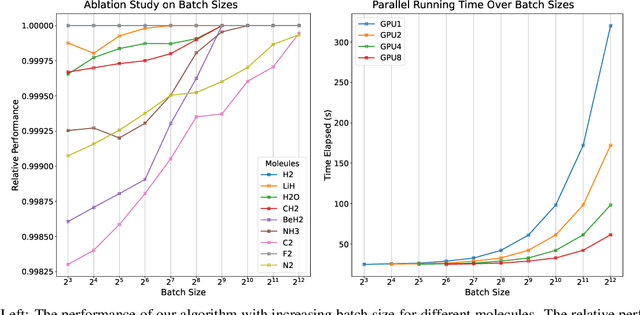
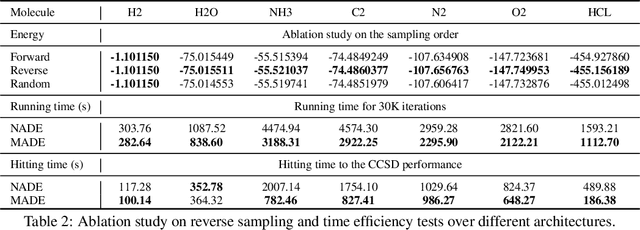
Variational optimization of neural-network representations of quantum states has been successfully applied to solve interacting fermionic problems. Despite rapid developments, significant scalability challenges arise when considering molecules of large scale, which correspond to non-locally interacting quantum spin Hamiltonians consisting of sums of thousands or even millions of Pauli operators. In this work, we introduce scalable parallelization strategies to improve neural-network-based variational quantum Monte Carlo calculations for ab-initio quantum chemistry applications. We establish GPU-supported local energy parallelism to compute the optimization objective for Hamiltonians of potentially complex molecules. Using autoregressive sampling techniques, we demonstrate systematic improvement in wall-clock timings required to achieve CCSD baseline target energies. The performance is further enhanced by accommodating the structure of resultant spin Hamiltonians into the autoregressive sampling ordering. The algorithm achieves promising performance in comparison with the classical approximate methods and exhibits both running time and scalability advantages over existing neural-network based methods.
CodedVTR: Codebook-based Sparse Voxel Transformer with Geometric Guidance
Mar 27, 2022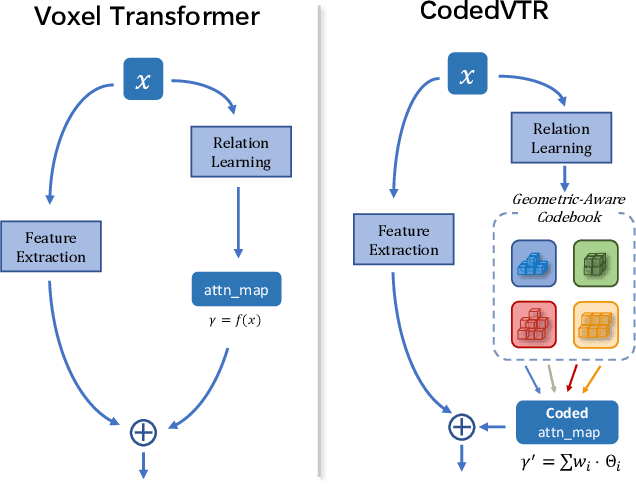
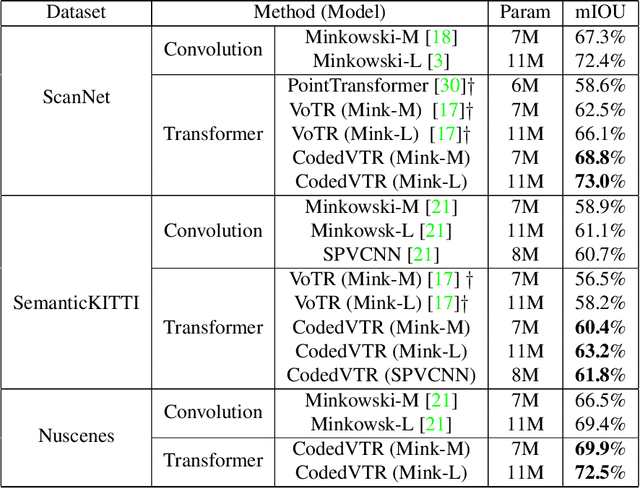
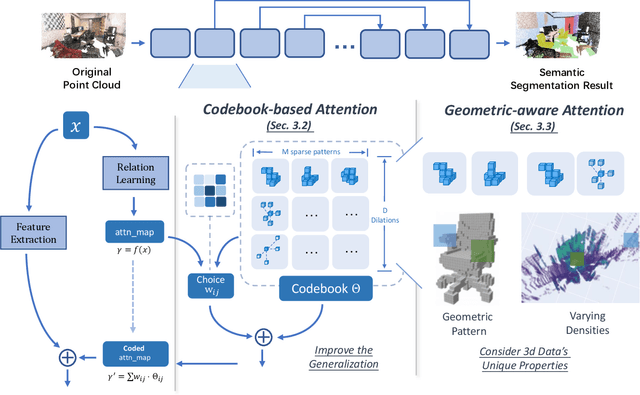
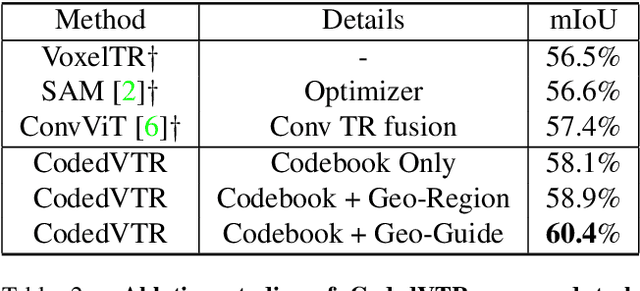
Transformers have gained much attention by outperforming convolutional neural networks in many 2D vision tasks. However, they are known to have generalization problems and rely on massive-scale pre-training and sophisticated training techniques. When applying to 3D tasks, the irregular data structure and limited data scale add to the difficulty of transformer's application. We propose CodedVTR (Codebook-based Voxel TRansformer), which improves data efficiency and generalization ability for 3D sparse voxel transformers. On the one hand, we propose the codebook-based attention that projects an attention space into its subspace represented by the combination of "prototypes" in a learnable codebook. It regularizes attention learning and improves generalization. On the other hand, we propose geometry-aware self-attention that utilizes geometric information (geometric pattern, density) to guide attention learning. CodedVTR could be embedded into existing sparse convolution-based methods, and bring consistent performance improvements for indoor and outdoor 3D semantic segmentation tasks
Multi-shot NAS for Discovering Adversarially Robust Convolutional Neural Architectures at Targeted Capacities
Jan 01, 2021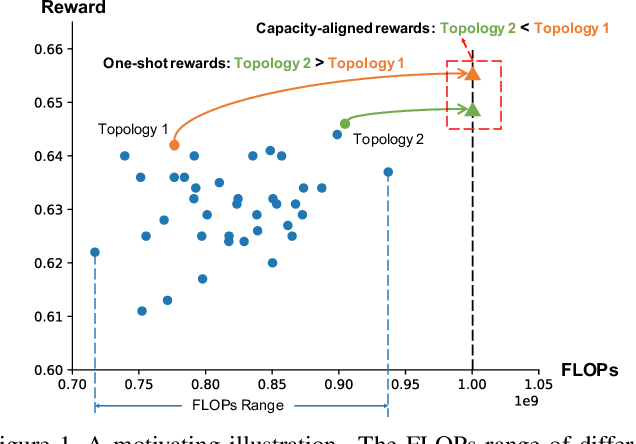
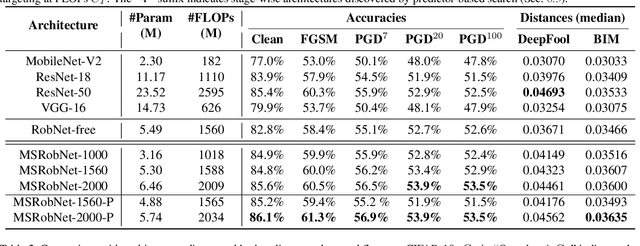

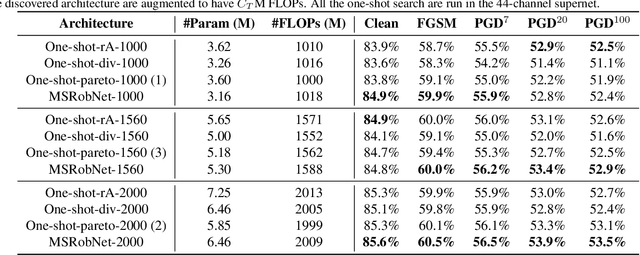
Convolutional neural networks (CNNs) are vulnerable to adversarial examples, and studies show that increasing the model capacity of an architecture topology (e.g., width expansion) can bring consistent robustness improvements. This reveals a clear robustness-efficiency trade-off that should be considered in architecture design. Recent studies have employed one-shot neural architecture search (NAS) to discover adversarially robust architectures. However, since the capacities of different topologies cannot be easily aligned during the search process, current one-shot NAS methods might favor topologies with larger capacity in the supernet. And the discovered topology might be sub-optimal when aligned to the targeted capacity. This paper proposes a novel multi-shot NAS method to explicitly search for adversarially robust architectures at a certain targeted capacity. Specifically, we estimate the reward at the targeted capacity using interior extra-polation of the rewards from multiple supernets. Experimental results demonstrate the effectiveness of the proposed method. For instance, at the targeted FLOPs of 1560M, the discovered MSRobNet-1560 (clean 84.8%, PGD100 52.9%) outperforms the recent NAS-discovered architecture RobNet-free (clean 82.8%, PGD100 52.6%) with similar FLOPs. Codes are available at https://github.com/walkerning/aw_nas.
BARS: Joint Search of Cell Topology and Layout for Accurate and Efficient Binary ARchitectures
Dec 21, 2020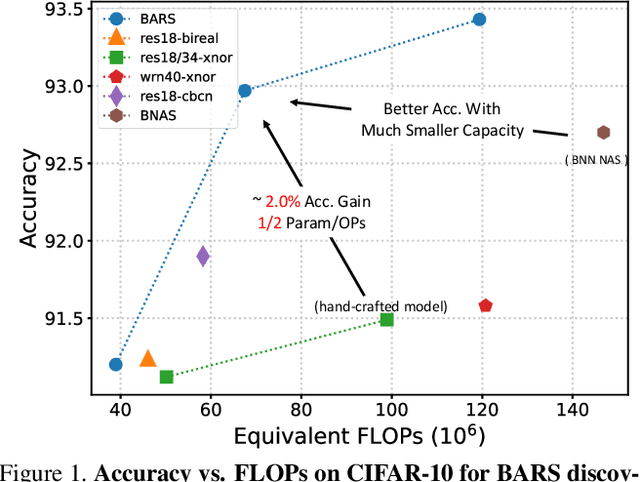

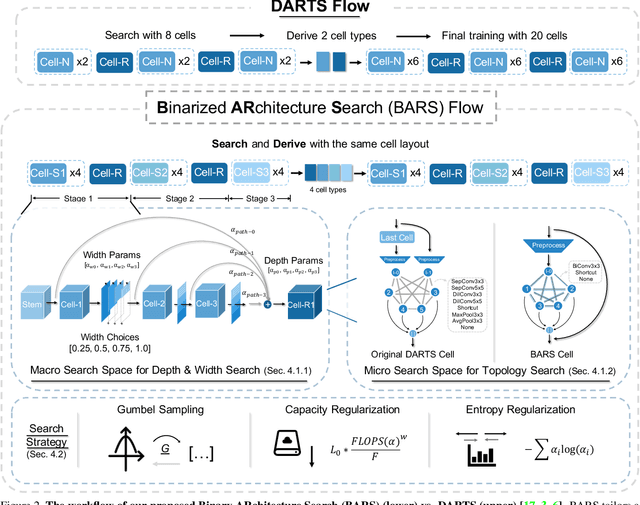
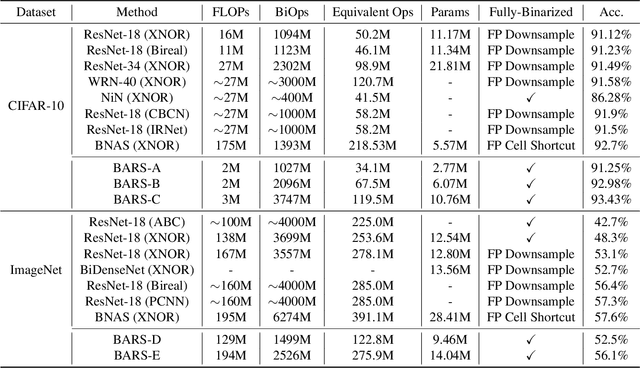
Binary Neural Networks (BNNs) have received significant attention due to their promising efficiency. Currently, most BNN studies directly adopt widely-used CNN architectures, which can be suboptimal for BNNs. This paper proposes a novel Binary ARchitecture Search (BARS) flow to discover superior binary architecture in a large design space. Specifically, we design a two-level (Macro & Micro) search space tailored for BNNs and apply a differentiable neural architecture search (NAS) to explore this search space efficiently. The macro-level search space includes depth and width decisions, which is required for better balancing the model performance and capacity. And we also make modifications to the micro-level search space to strengthen the information flow for BNN. A notable challenge of BNN architecture search lies in that binary operations exacerbate the "collapse" problem of differentiable NAS, and we incorporate various search and derive strategies to stabilize the search process. On CIFAR-10, BARS achieves 1.5% higher accuracy with 2/3 binary Ops and $1/10$ floating-point Ops. On ImageNet, with similar resource consumption, BARS-discovered architecture achieves 3% accuracy gain than hand-crafted architectures, while removing the full-precision downsample layer.
Learning to Recognize Patch-Wise Consistency for Deepfake Detection
Dec 16, 2020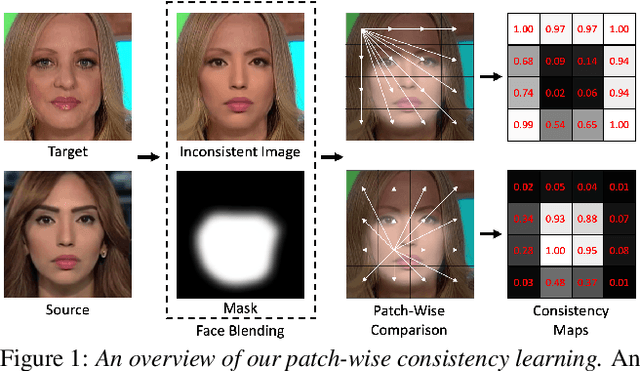

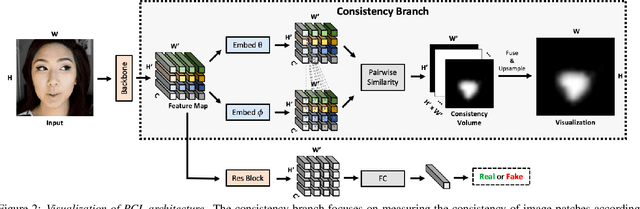
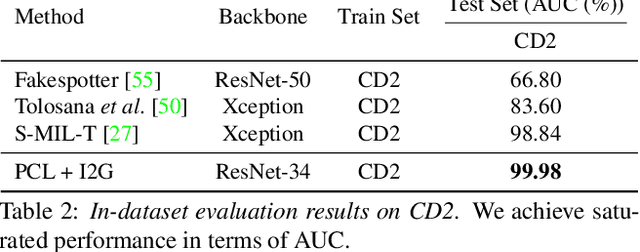
We propose to detect Deepfake generated by face manipulation based on one of their fundamental features: images are blended by patches from multiple sources, carrying distinct and persistent source features. In particular, we propose a novel representation learning approach for this task, called patch-wise consistency learning (PCL). It learns by measuring the consistency of image source features, resulting to representation with good interpretability and robustness to multiple forgery methods. We develop an inconsistency image generator (I2G) to generate training data for PCL and boost its robustness. We evaluate our approach on seven popular Deepfake detection datasets. Our model achieves superior detection accuracy and generalizes well to unseen generation methods. On average, our model outperforms the state-of-the-art in terms of AUC by 2% and 8% in the in- and cross-dataset evaluation, respectively.
aw_nas: A Modularized and Extensible NAS framework
Nov 25, 2020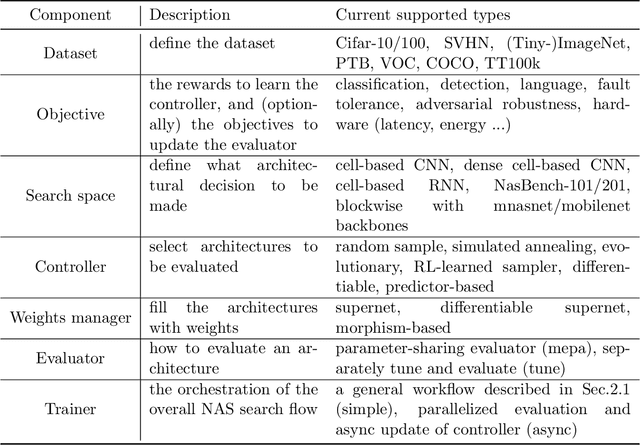
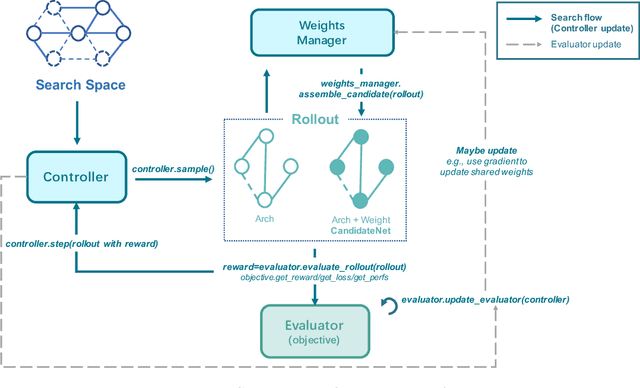

Neural Architecture Search (NAS) has received extensive attention due to its capability to discover neural network architectures in an automated manner. aw_nas is an open-source Python framework implementing various NAS algorithms in a modularized manner. Currently, aw_nas can be used to reproduce the results of mainstream NAS algorithms of various types. Also, due to the modularized design, one can simply experiment with different NAS algorithms for various applications with awnas (e.g., classification, detection, text modeling, fault tolerance, adversarial robustness, hardware efficiency, and etc.). Codes and documentation are available at https://github.com/walkerning/aw_nas.