 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
Jun 15, 2022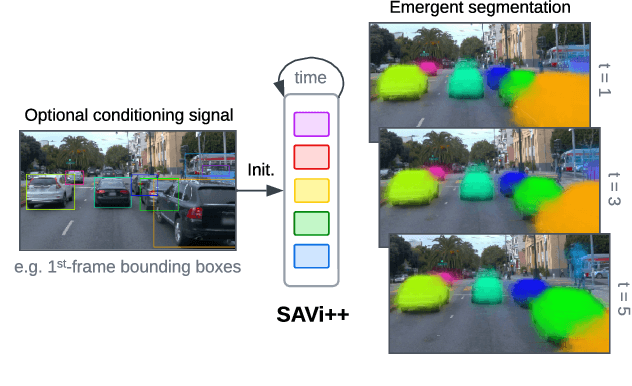
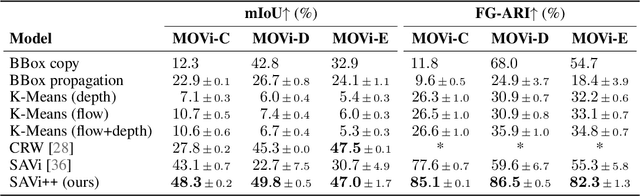
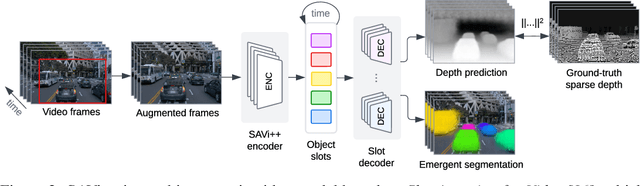

The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset.
Object Scene Representation Transformer
Jun 14, 2022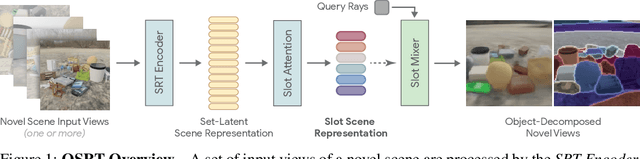

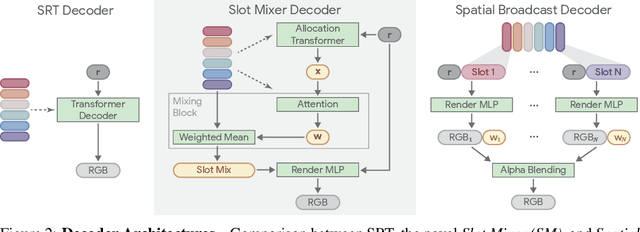
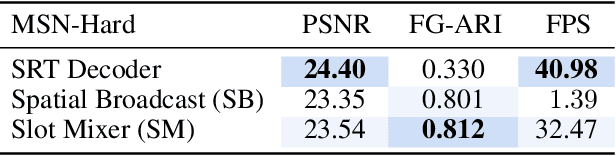
A compositional understanding of the world in terms of objects and their geometry in 3D space is considered a cornerstone of human cognition. Facilitating the learning of such a representation in neural networks holds promise for substantially improving labeled data efficiency. As a key step in this direction, we make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. We believe this work will not only accelerate future architecture exploration and scaling efforts, but it will also serve as a useful tool for both object-centric as well as neural scene representation learning communities.
Simple Open-Vocabulary Object Detection with Vision Transformers
May 12, 2022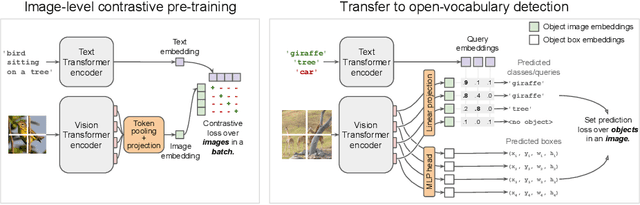
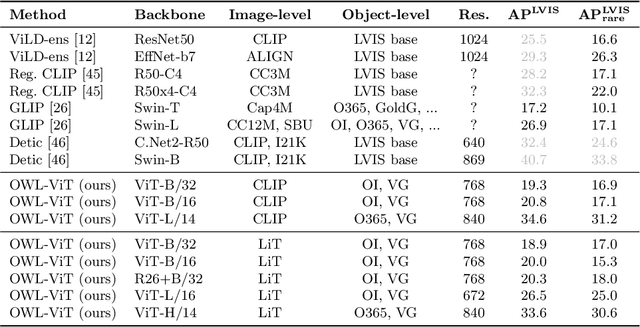
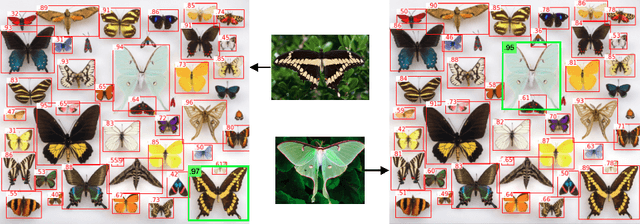
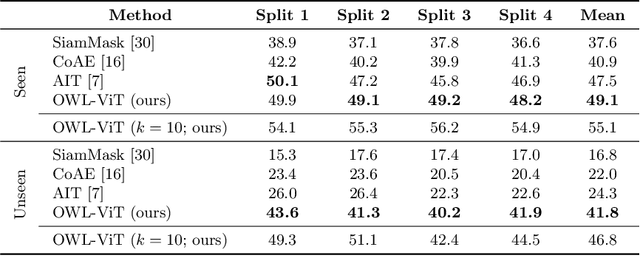
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
Binding Actions to Objects in World Models
Apr 27, 2022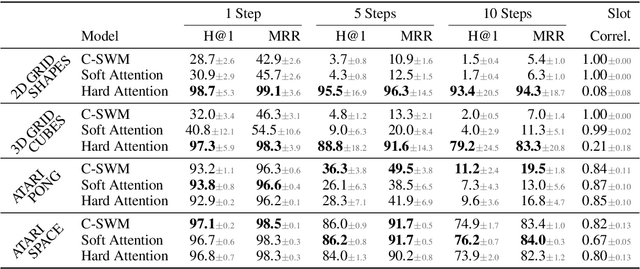
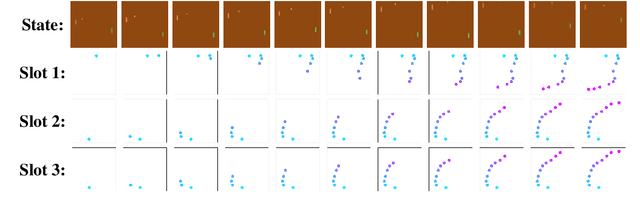
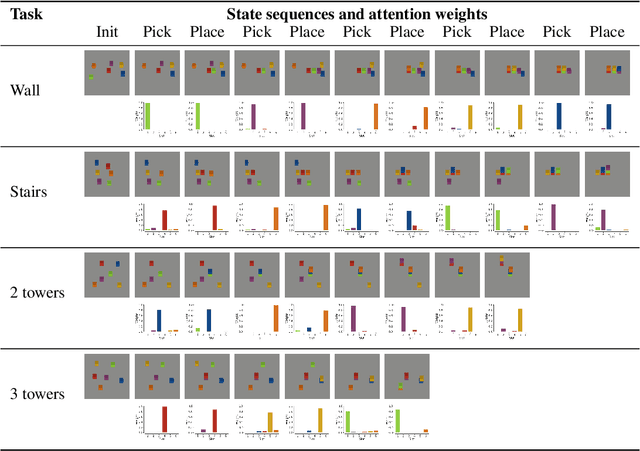
We study the problem of binding actions to objects in object-factored world models using action-attention mechanisms. We propose two attention mechanisms for binding actions to objects, soft attention and hard attention, which we evaluate in the context of structured world models for five environments. Our experiments show that hard attention helps contrastively-trained structured world models to learn to separate individual objects in an object-based grid-world environment. Further, we show that soft attention increases performance of factored world models trained on a robotic manipulation task. The learned action attention weights can be used to interpret the factored world model as the attention focuses on the manipulated object in the environment.
Symmetry Group Equivariant Architectures for Physics
Mar 11, 2022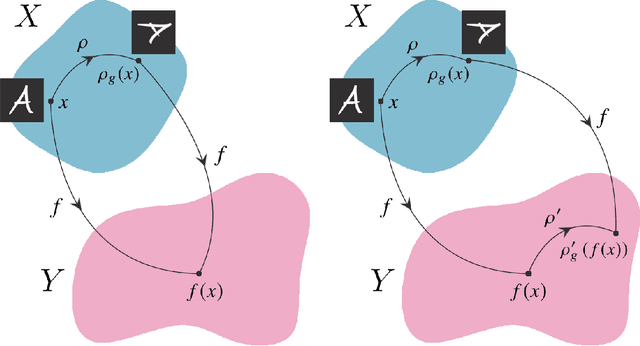
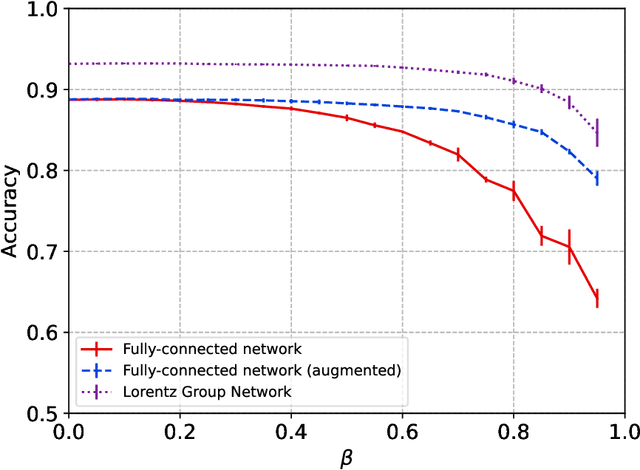
Physical theories grounded in mathematical symmetries are an essential component of our understanding of a wide range of properties of the universe. Similarly, in the domain of machine learning, an awareness of symmetries such as rotation or permutation invariance has driven impressive performance breakthroughs in computer vision, natural language processing, and other important applications. In this report, we argue that both the physics community and the broader machine learning community have much to understand and potentially to gain from a deeper investment in research concerning symmetry group equivariant machine learning architectures. For some applications, the introduction of symmetries into the fundamental structural design can yield models that are more economical (i.e. contain fewer, but more expressive, learned parameters), interpretable (i.e. more explainable or directly mappable to physical quantities), and/or trainable (i.e. more efficient in both data and computational requirements). We discuss various figures of merit for evaluating these models as well as some potential benefits and limitations of these methods for a variety of physics applications. Research and investment into these approaches will lay the foundation for future architectures that are potentially more robust under new computational paradigms and will provide a richer description of the physical systems to which they are applied.
Kubric: A scalable dataset generator
Mar 07, 2022

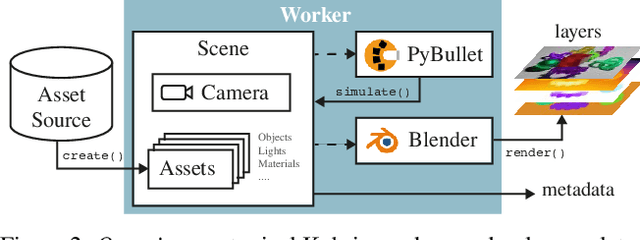
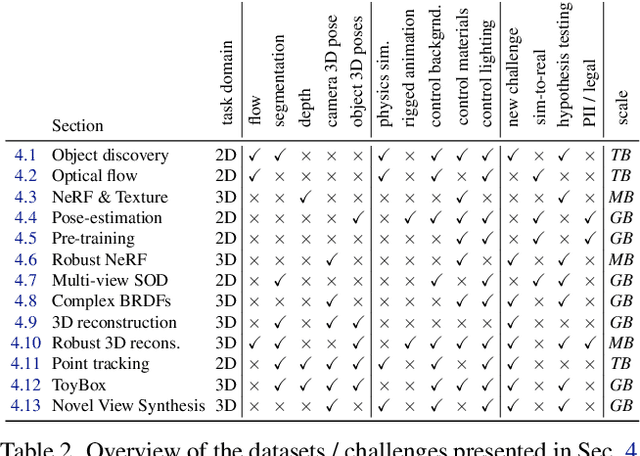
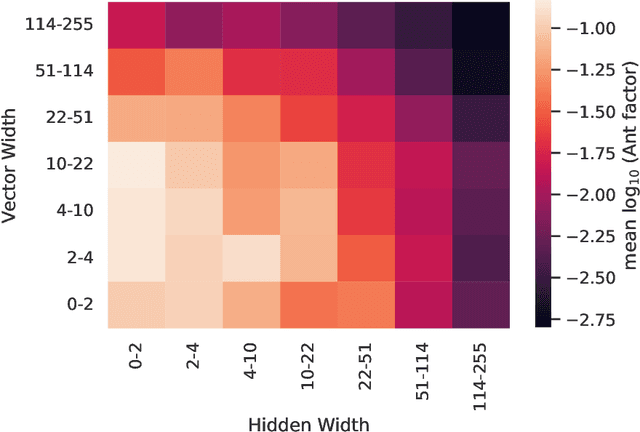
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
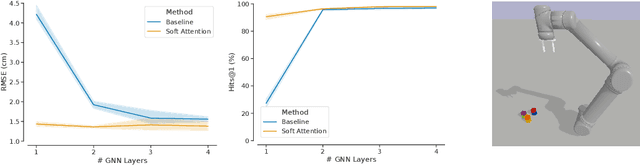
Factored World Models for Zero-Shot Generalization in Robotic Manipulation
Feb 10, 2022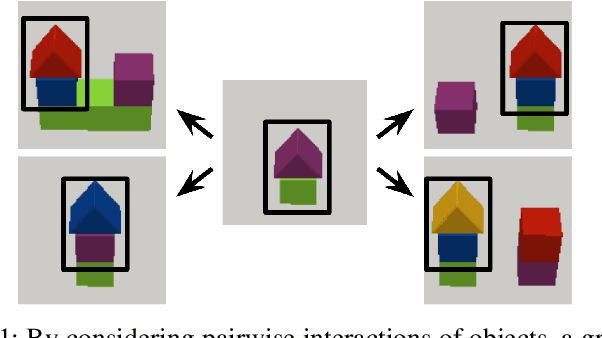

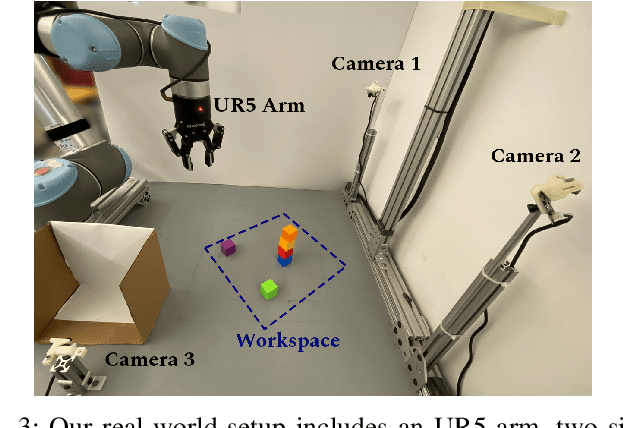
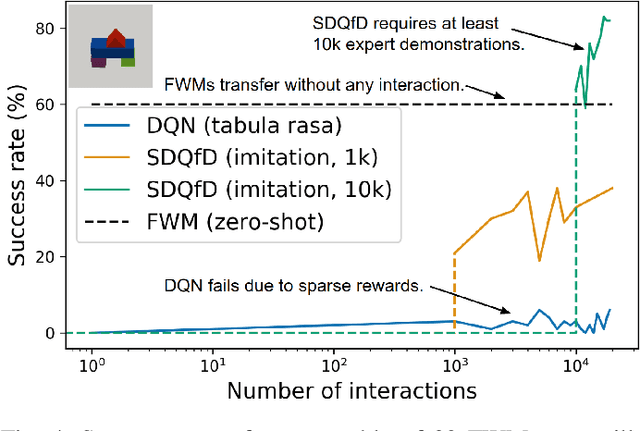
World models for environments with many objects face a combinatorial explosion of states: as the number of objects increases, the number of possible arrangements grows exponentially. In this paper, we learn to generalize over robotic pick-and-place tasks using object-factored world models, which combat the combinatorial explosion by ensuring that predictions are equivariant to permutations of objects. Previous object-factored models were limited either by their inability to model actions, or by their inability to plan for complex manipulation tasks. We build on recent contrastive methods for training object-factored world models, which we extend to model continuous robot actions and to accurately predict the physics of robotic pick-and-place. To do so, we use a residual stack of graph neural networks that receive action information at multiple levels in both their node and edge neural networks. Crucially, our learned model can make predictions about tasks not represented in the training data. That is, we demonstrate successful zero-shot generalization to novel tasks, with only a minor decrease in model performance. Moreover, we show that an ensemble of our models can be used to plan for tasks involving up to 12 pick and place actions using heuristic search. We also demonstrate transfer to a physical robot.
Conditional Object-Centric Learning from Video
Nov 24, 2021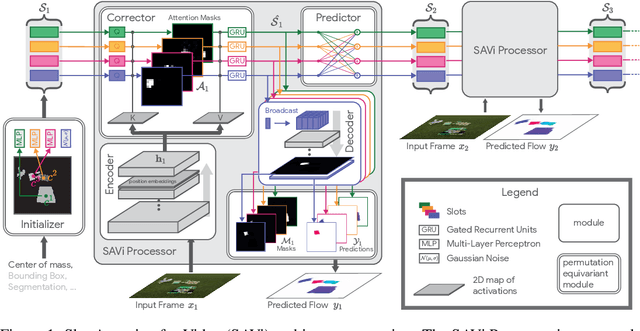

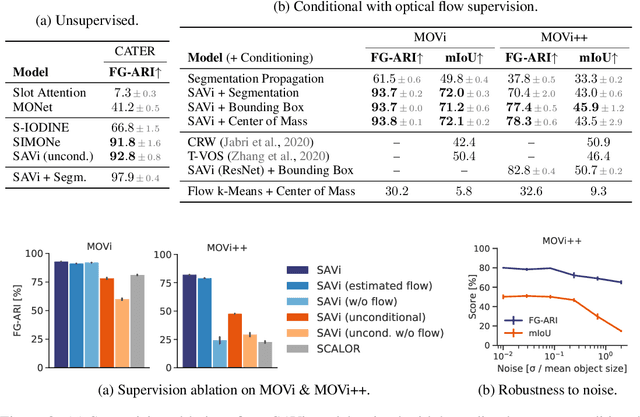

Object-centric representations are a promising path toward more systematic generalization by providing flexible abstractions upon which compositional world models can be built. Recent work on simple 2D and 3D datasets has shown that models with object-centric inductive biases can learn to segment and represent meaningful objects from the statistical structure of the data alone without the need for any supervision. However, such fully-unsupervised methods still fail to scale to diverse realistic data, despite the use of increasingly complex inductive biases such as priors for the size of objects or the 3D geometry of the scene. In this paper, we instead take a weakly-supervised approach and focus on how 1) using the temporal dynamics of video data in the form of optical flow and 2) conditioning the model on simple object location cues can be used to enable segmenting and tracking objects in significantly more realistic synthetic data. We introduce a sequential extension to Slot Attention which we train to predict optical flow for realistic looking synthetic scenes and show that conditioning the initial state of this model on a small set of hints, such as center of mass of objects in the first frame, is sufficient to significantly improve instance segmentation. These benefits generalize beyond the training distribution to novel objects, novel backgrounds, and to longer video sequences. We also find that such initial-state-conditioning can be used during inference as a flexible interface to query the model for specific objects or parts of objects, which could pave the way for a range of weakly-supervised approaches and allow more effective interaction with trained models.
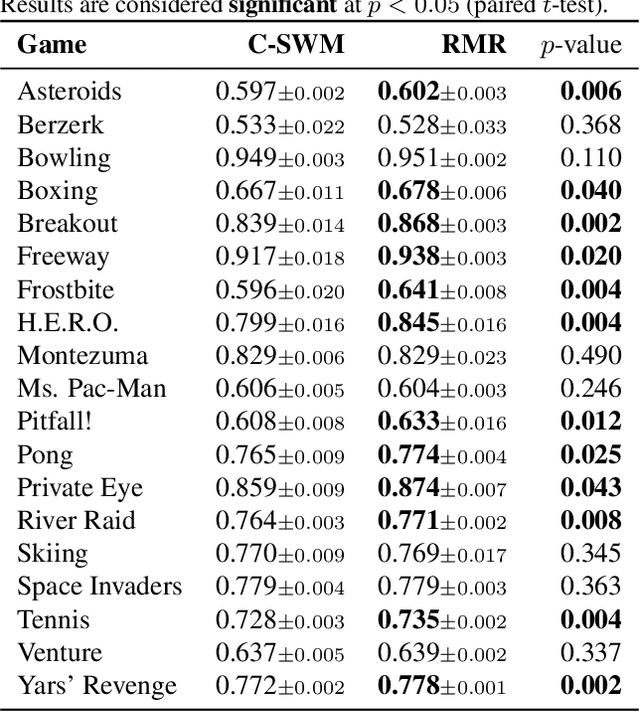
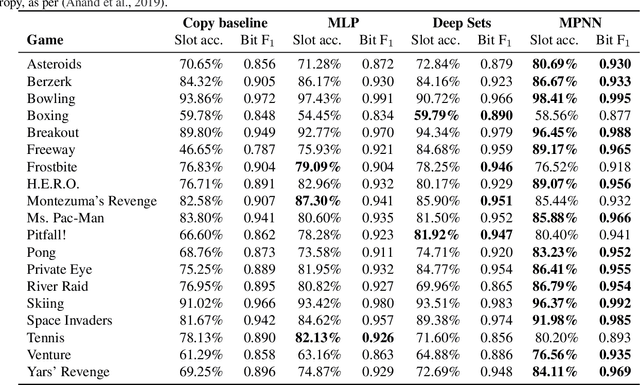
The Impact of Negative Sampling on Contrastive Structured World Models
Jul 24, 2021
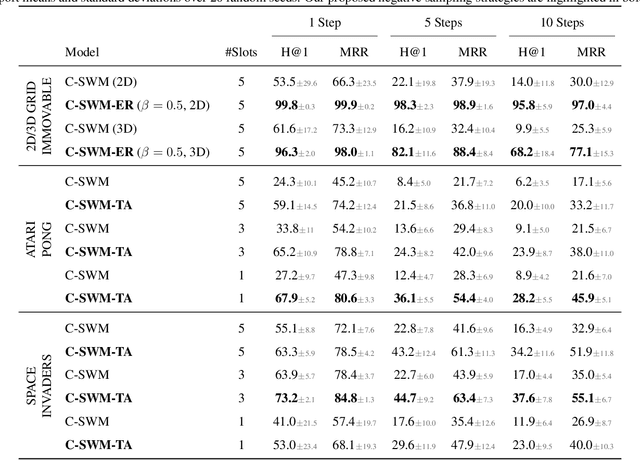

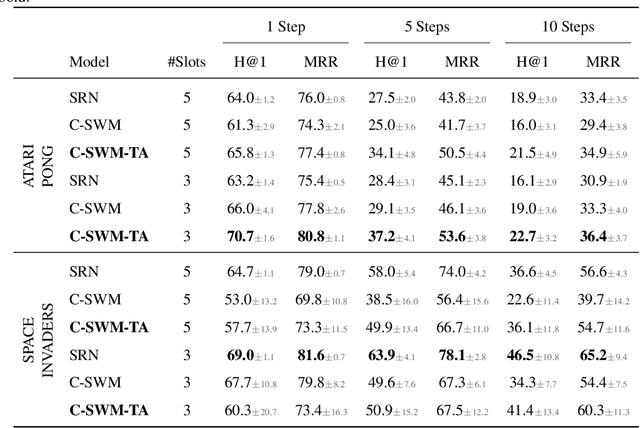
World models trained by contrastive learning are a compelling alternative to autoencoder-based world models, which learn by reconstructing pixel states. In this paper, we describe three cases where small changes in how we sample negative states in the contrastive loss lead to drastic changes in model performance. In previously studied Atari datasets, we show that leveraging time step correlations can double the performance of the Contrastive Structured World Model. We also collect a full version of the datasets to study contrastive learning under a more diverse set of experiences.
Reasoning-Modulated Representations
Jul 19, 2021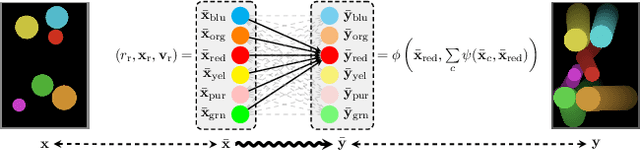
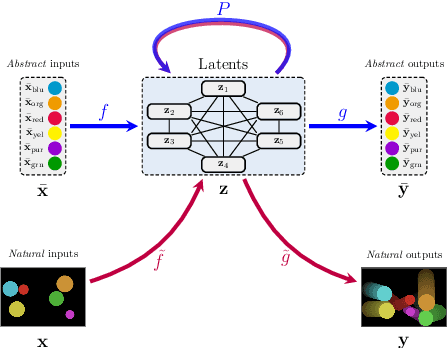
Neural networks leverage robust internal representations in order to generalise. Learning them is difficult, and often requires a large training set that covers the data distribution densely. We study a common setting where our task is not purely opaque. Indeed, very often we may have access to information about the underlying system (e.g. that observations must obey certain laws of physics) that any "tabula rasa" neural network would need to re-learn from scratch, penalising data efficiency. We incorporate this information into a pre-trained reasoning module, and investigate its role in shaping the discovered representations in diverse self-supervised learning settings from pixels. Our approach paves the way for a new class of data-efficient representation learning.