 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom AGI to ASI
Jun 10, 2026Over the last decade, building human-level artificial general intelligence has moved from far-fetched speculation to being a concrete next-decade target for many of the largest AI organisations. Achieving this goal would have profound and far-reaching impacts on human society, which raises many complex questions for the decade ahead. This report investigates how AI itself might continue to develop in a post-AGI world along the continuum of machine intelligence. The endpoint of this continuum, Universal AI, is theoretically well understood, which provides some formal grounding for the main focus of this report: the transition from human-level AGI to artificial general superintelligence, which, intuitively, can be understood as a system that is more intelligent and cognitively capable than large organisations of humans. After characterizing ASI, the report discusses four potential pathways from AGI to ASI: scaling AGI, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi-agent collectives. The report then discusses possible frictions and bottlenecks along these pathways. Determining whether the impact of these frictions will be negligible or substantial raises a number of concrete open research questions. Due to large uncertainties for predicting ASI progress, it cannot be ruled out that AI progress might continue to accelerate over the next years. This could imply that the image of a single transformative step change, caused by the introduction of human-level AGI into our society, could be inaccurate. More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology. Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.
Can foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



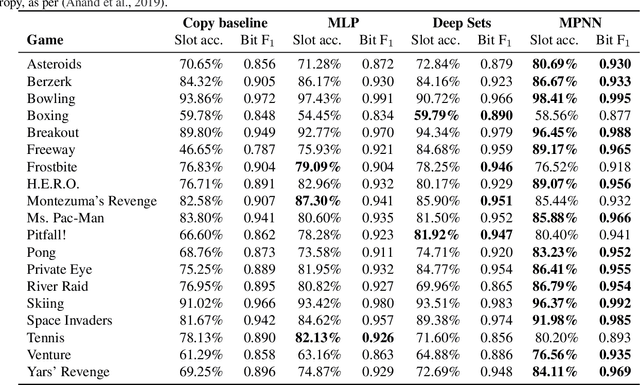
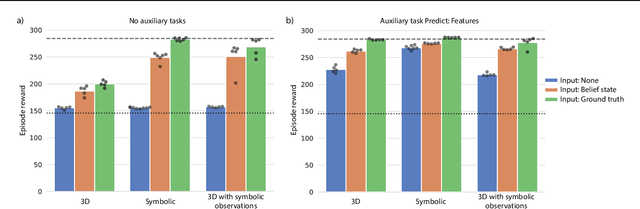
While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Evaluating VLMs for Score-Based, Multi-Probe Annotation of 3D Objects
Nov 29, 2023Unlabeled 3D objects present an opportunity to leverage pretrained vision language models (VLMs) on a range of annotation tasks -- from describing object semantics to physical properties. An accurate response must take into account the full appearance of the object in 3D, various ways of phrasing the question/prompt, and changes in other factors that affect the response. We present a method to marginalize over any factors varied across VLM queries, utilizing the VLM's scores for sampled responses. We first show that this probabilistic aggregation can outperform a language model (e.g., GPT4) for summarization, for instance avoiding hallucinations when there are contrasting details between responses. Secondly, we show that aggregated annotations are useful for prompt-chaining; they help improve downstream VLM predictions (e.g., of object material when the object's type is specified as an auxiliary input in the prompt). Such auxiliary inputs allow ablating and measuring the contribution of visual reasoning over language-only reasoning. Using these evaluations, we show how VLMs can approach, without additional training or in-context learning, the quality of human-verified type and material annotations on the large-scale Objaverse dataset.
Constellation: Learning relational abstractions over objects for compositional imagination
Jul 23, 2021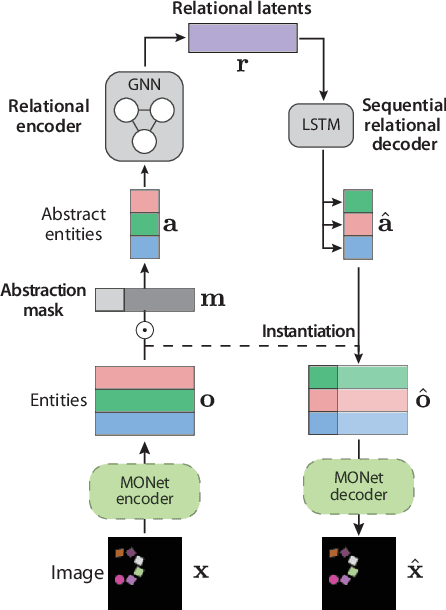
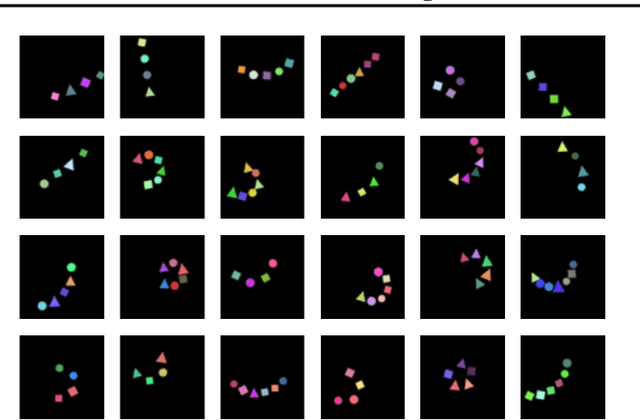


Learning structured representations of visual scenes is currently a major bottleneck to bridging perception with reasoning. While there has been exciting progress with slot-based models, which learn to segment scenes into sets of objects, learning configurational properties of entire groups of objects is still under-explored. To address this problem, we introduce Constellation, a network that learns relational abstractions of static visual scenes, and generalises these abstractions over sensory particularities, thus offering a potential basis for abstract relational reasoning. We further show that this basis, along with language association, provides a means to imagine sensory content in new ways. This work is a first step in the explicit representation of visual relationships and using them for complex cognitive procedures.
Reasoning-Modulated Representations
Jul 19, 2021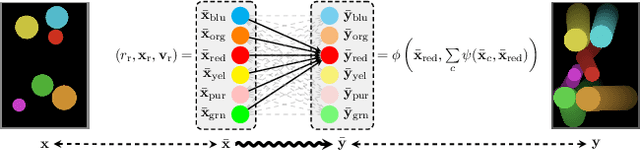
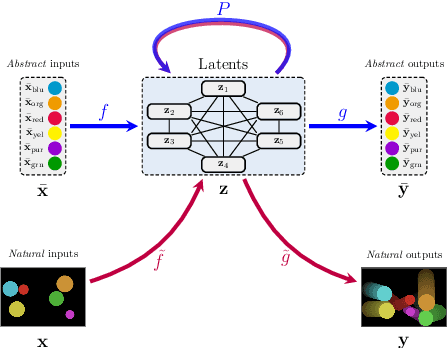
Neural networks leverage robust internal representations in order to generalise. Learning them is difficult, and often requires a large training set that covers the data distribution densely. We study a common setting where our task is not purely opaque. Indeed, very often we may have access to information about the underlying system (e.g. that observations must obey certain laws of physics) that any "tabula rasa" neural network would need to re-learn from scratch, penalising data efficiency. We incorporate this information into a pre-trained reasoning module, and investigate its role in shaping the discovered representations in diverse self-supervised learning settings from pixels. Our approach paves the way for a new class of data-efficient representation learning.
SIMONe: View-Invariant, Temporally-Abstracted Object Representations via Unsupervised Video Decomposition
Jun 07, 2021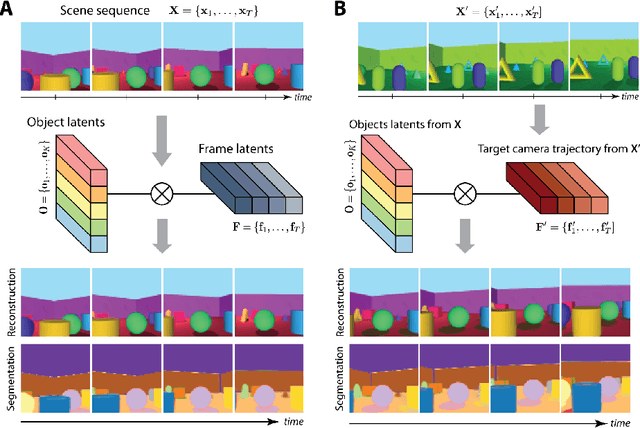
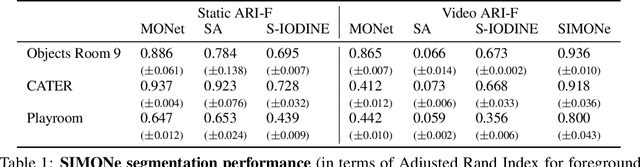
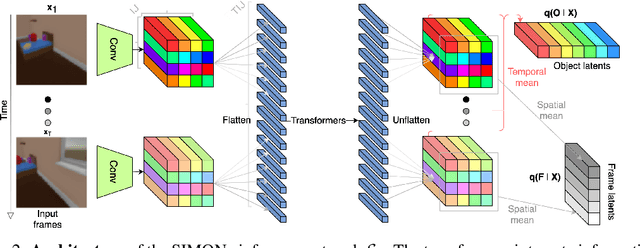

To help agents reason about scenes in terms of their building blocks, we wish to extract the compositional structure of any given scene (in particular, the configuration and characteristics of objects comprising the scene). This problem is especially difficult when scene structure needs to be inferred while also estimating the agent's location/viewpoint, as the two variables jointly give rise to the agent's observations. We present an unsupervised variational approach to this problem. Leveraging the shared structure that exists across different scenes, our model learns to infer two sets of latent representations from RGB video input alone: a set of "object" latents, corresponding to the time-invariant, object-level contents of the scene, as well as a set of "frame" latents, corresponding to global time-varying elements such as viewpoint. This factorization of latents allows our model, SIMONe, to represent object attributes in an allocentric manner which does not depend on viewpoint. Moreover, it allows us to disentangle object dynamics and summarize their trajectories as time-abstracted, view-invariant, per-object properties. We demonstrate these capabilities, as well as the model's performance in terms of view synthesis and instance segmentation, across three procedurally generated video datasets.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021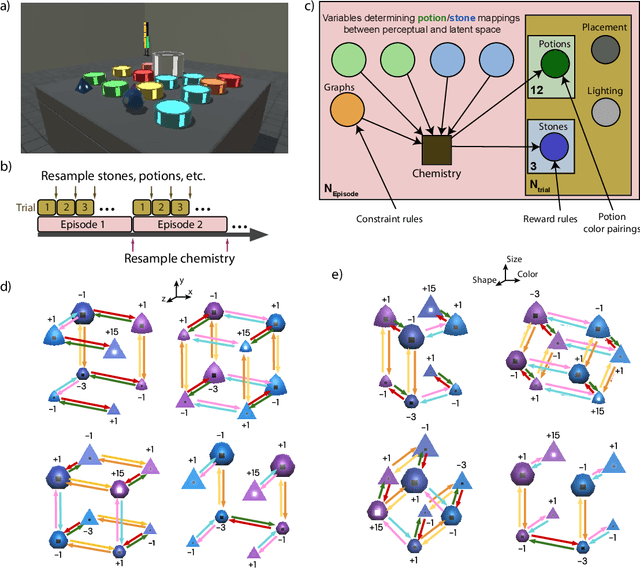


There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
Formalising Concepts as Grounded Abstractions
Jan 13, 2021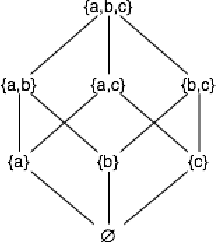
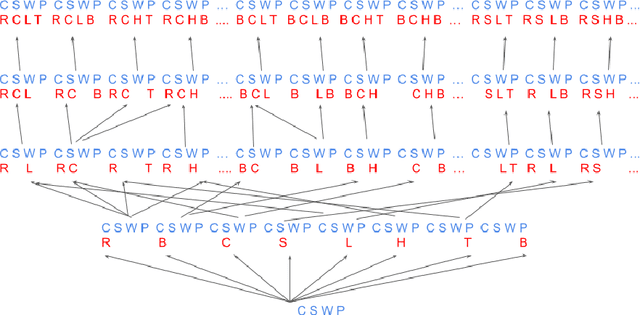
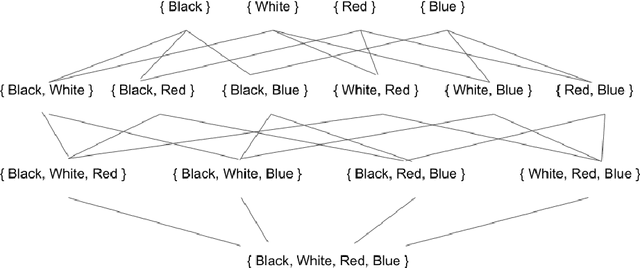
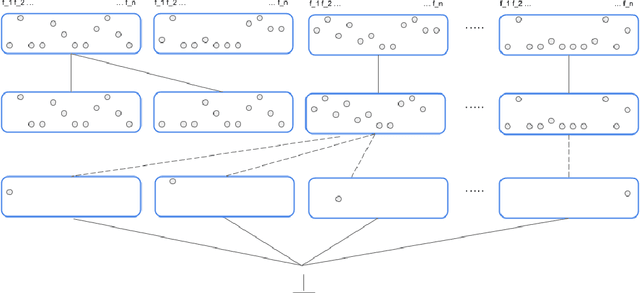
The notion of concept has been studied for centuries, by philosophers, linguists, cognitive scientists, and researchers in artificial intelligence (Margolis & Laurence, 1999). There is a large literature on formal, mathematical models of concepts, including a whole sub-field of AI -- Formal Concept Analysis -- devoted to this topic (Ganter & Obiedkov, 2016). Recently, researchers in machine learning have begun to investigate how methods from representation learning can be used to induce concepts from raw perceptual data (Higgins, Sonnerat, et al., 2018). The goal of this report is to provide a formal account of concepts which is compatible with this latest work in deep learning. The main technical goal of this report is to show how techniques from representation learning can be married with a lattice-theoretic formulation of conceptual spaces. The mathematics of partial orders and lattices is a standard tool for modelling conceptual spaces (Ch.2, Mitchell (1997), Ganter and Obiedkov (2016)); however, there is no formal work that we are aware of which defines a conceptual lattice on top of a representation that is induced using unsupervised deep learning (Goodfellow et al., 2016). The advantages of partially-ordered lattice structures are that these provide natural mechanisms for use in concept discovery algorithms, through the meets and joins of the lattice.
A Heuristic for Unsupervised Model Selection for Variational Disentangled Representation Learning
May 29, 2019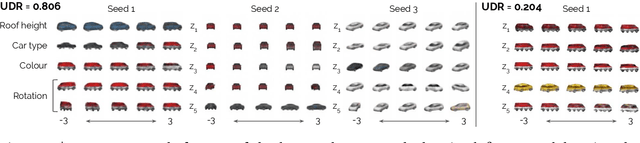

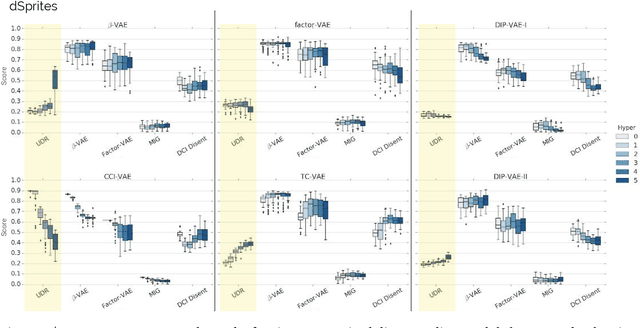

Disentangled representations have recently been shown to improve data efficiency, generalisation, robustness and interpretability in simple supervised and reinforcement learning tasks. To extend such results to more complex domains, it is important to address a major shortcoming of the current state of the art unsupervised disentangling approaches -- high convergence variance, whereby different disentanglement quality may be achieved by the same model depending on its initial state. The existing model selection methods require access to the ground truth attribute labels, which are not available for most datasets. Hence, the benefits of disentangled representations have not yet been fully explored in practical applications. This paper addresses this problem by introducing a simple yet robust and reliable method for unsupervised disentangled model selection. We show that our approach performs comparably to the existing supervised alternatives across 5400 models from six state of the art unsupervised disentangled representation learning model classes.