 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM General Preference Alignment via Optimistic Online Mirror Descent
Feb 24, 2025


Reinforcement learning from human feedback (RLHF) has demonstrated remarkable effectiveness in aligning large language models (LLMs) with human preferences. Many existing alignment approaches rely on the Bradley-Terry (BT) model assumption, which assumes the existence of a ground-truth reward for each prompt-response pair. However, this assumption can be overly restrictive when modeling complex human preferences. In this paper, we drop the BT model assumption and study LLM alignment under general preferences, formulated as a two-player game. Drawing on theoretical insights from learning in games, we integrate optimistic online mirror descent into our alignment framework to approximate the Nash policy. Theoretically, we demonstrate that our approach achieves an $O(T^{-1})$ bound on the duality gap, improving upon the previous $O(T^{-1/2})$ result. More importantly, we implement our method and show through experiments that it outperforms state-of-the-art RLHF algorithms across multiple representative benchmarks.
OpenCharacter: Training Customizable Role-Playing LLMs with Large-Scale Synthetic Personas
Jan 26, 2025



Customizable role-playing in large language models (LLMs), also known as character generalization, is gaining increasing attention for its versatility and cost-efficiency in developing and deploying role-playing dialogue agents. This study explores a large-scale data synthesis approach to equip LLMs with character generalization capabilities. We begin by synthesizing large-scale character profiles using personas from Persona Hub and then explore two strategies: response rewriting and response generation, to create character-aligned instructional responses. To validate the effectiveness of our synthetic instruction tuning data for character generalization, we perform supervised fine-tuning (SFT) using the LLaMA-3 8B model. Our best-performing model strengthens the original LLaMA-3 8B Instruct model and achieves performance comparable to GPT-4o models on role-playing dialogue. We release our synthetic characters and instruction-tuning dialogues to support public research.
Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens
Nov 26, 2024



We reveal that low-bit quantization favors undertrained large language models (LLMs) by observing that models with larger sizes or fewer training tokens experience less quantization-induced degradation (QiD) when applying low-bit quantization, whereas smaller models with extensive training tokens suffer significant QiD. To gain deeper insights into this trend, we study over 1500 quantized LLM checkpoints of various sizes and at different training levels (undertrained or fully trained) in a controlled setting, deriving scaling laws for understanding the relationship between QiD and factors such as the number of training tokens, model size and bit width. With the derived scaling laws, we propose a novel perspective that we can use QiD to measure an LLM's training levels and determine the number of training tokens required for fully training LLMs of various sizes. Moreover, we use the scaling laws to predict the quantization performance of different-sized LLMs trained with 100 trillion tokens. Our projection shows that the low-bit quantization performance of future models, which are expected to be trained with over 100 trillion tokens, may NOT be desirable. This poses a potential challenge for low-bit quantization in the future and highlights the need for awareness of a model's training level when evaluating low-bit quantization research. To facilitate future research on this problem, we release all the 1500+ quantized checkpoints used in this work at https://huggingface.co/Xu-Ouyang.
Router-Tuning: A Simple and Effective Approach for Enabling Dynamic-Depth in Transformers
Oct 17, 2024Traditional transformer models often allocate a fixed amount of computational resources to every input token, leading to inefficient and unnecessary computation. To address this, the Mixture of Depths (MoD) was introduced to dynamically adjust the computational depth by skipping less important layers. Despite its promise, current MoD approaches remain under-explored and face two main challenges: (1) \textit{high training costs due to the need to train the entire model along with the routers that determine which layers to skip}, and (2) \textit{the risk of performance degradation when important layers are bypassed}. In response to the first issue, we propose Router-Tuning, a method that fine-tunes only the router on a small dataset, drastically reducing the computational overhead associated with full model training. For the second challenge, we propose MindSkip, which deploys \textit{Attention with Dynamic Depths}. This method preserves the model's performance while significantly enhancing computational and memory efficiency. Extensive experiments demonstrate that our approach delivers competitive results while dramatically improving the computation efficiency, e.g., 21\% speedup and only a 0.2\% performance drop. The code is released at \url{https://github.com/CASE-Lab-UMD/Router-Tuning}.
ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Oct 08, 2024



Speculative decoding has proven to be an efficient solution to large language model (LLM) inference, where the small drafter predicts future tokens at a low cost, and the target model is leveraged to verify them in parallel. However, most existing works still draft tokens auto-regressively to maintain sequential dependency in language modeling, which we consider a huge computational burden in speculative decoding. We present ParallelSpec, an alternative to auto-regressive drafting strategies in state-of-the-art speculative decoding approaches. In contrast to auto-regressive drafting in the speculative stage, we train a parallel drafter to serve as an efficient speculative model. ParallelSpec learns to efficiently predict multiple future tokens in parallel using a single model, and it can be integrated into any speculative decoding framework that requires aligning the output distributions of the drafter and the target model with minimal training cost. Experimental results show that ParallelSpec accelerates baseline methods in latency up to 62% on text generation benchmarks from different domains, and it achieves 2.84X overall speedup on the Llama-2-13B model using third-party evaluation criteria.
Refining Corpora from a Model Calibration Perspective for Chinese Spelling Correction
Jul 22, 2024



Chinese Spelling Correction (CSC) commonly lacks large-scale high-quality corpora, due to the labor-intensive labeling of spelling errors in real-life human writing or typing scenarios. Two data augmentation methods are widely adopted: (1) \textit{Random Replacement} with the guidance of confusion sets and (2) \textit{OCR/ASR-based Generation} that simulates character misusing. However, both methods inevitably introduce noisy data (e.g., false spelling errors), potentially leading to over-correction. By carefully analyzing the two types of corpora, we find that though the latter achieves more robust generalization performance, the former yields better-calibrated CSC models. We then provide a theoretical analysis of this empirical observation, based on which a corpus refining strategy is proposed. Specifically, OCR/ASR-based data samples are fed into a well-calibrated CSC model trained on random replacement-based corpora and then filtered based on prediction confidence. By learning a simple BERT-based model on the refined OCR/ASR-based corpus, we set up impressive state-of-the-art performance on three widely-used benchmarks, while significantly alleviating over-correction (e.g., lowering false positive predictions).
Enhancing Language Model Rationality with Bi-Directional Deliberation Reasoning
Jul 08, 2024



This paper introduces BI-Directional DEliberation Reasoning (BIDDER), a novel reasoning approach to enhance the decision rationality of language models. Traditional reasoning methods typically rely on historical information and employ uni-directional (left-to-right) reasoning strategy. This lack of bi-directional deliberation reasoning results in limited awareness of potential future outcomes and insufficient integration of historical context, leading to suboptimal decisions. BIDDER addresses this gap by incorporating principles of rational decision-making, specifically managing uncertainty and predicting expected utility. Our approach involves three key processes: Inferring hidden states to represent uncertain information in the decision-making process from historical data; Using these hidden states to predict future potential states and potential outcomes; Integrating historical information (past contexts) and long-term outcomes (future contexts) to inform reasoning. By leveraging bi-directional reasoning, BIDDER ensures thorough exploration of both past and future contexts, leading to more informed and rational decisions. We tested BIDDER's effectiveness in two well-defined scenarios: Poker (Limit Texas Hold'em) and Negotiation. Our experiments demonstrate that BIDDER significantly improves the decision-making capabilities of LLMs and LLM agents.
xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
May 22, 2024



This paper introduces xRAG, an innovative context compression method tailored for retrieval-augmented generation. xRAG reinterprets document embeddings in dense retrieval--traditionally used solely for retrieval--as features from the retrieval modality. By employing a modality fusion methodology, xRAG seamlessly integrates these embeddings into the language model representation space, effectively eliminating the need for their textual counterparts and achieving an extreme compression rate. In xRAG, the only trainable component is the modality bridge, while both the retriever and the language model remain frozen. This design choice allows for the reuse of offline-constructed document embeddings and preserves the plug-and-play nature of retrieval augmentation. Experimental results demonstrate that xRAG achieves an average improvement of over 10% across six knowledge-intensive tasks, adaptable to various language model backbones, ranging from a dense 7B model to an 8x7B Mixture of Experts configuration. xRAG not only significantly outperforms previous context compression methods but also matches the performance of uncompressed models on several datasets, while reducing overall FLOPs by a factor of 3.53. Our work pioneers new directions in retrieval-augmented generation from the perspective of multimodality fusion, and we hope it lays the foundation for future efficient and scalable retrieval-augmented systems
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024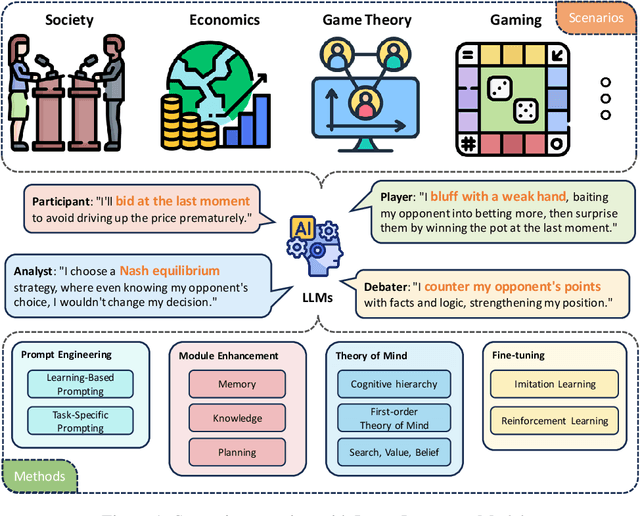
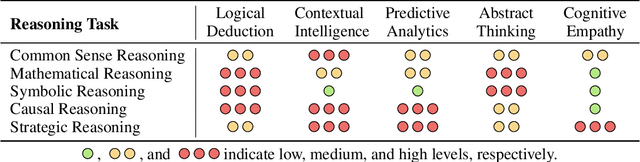
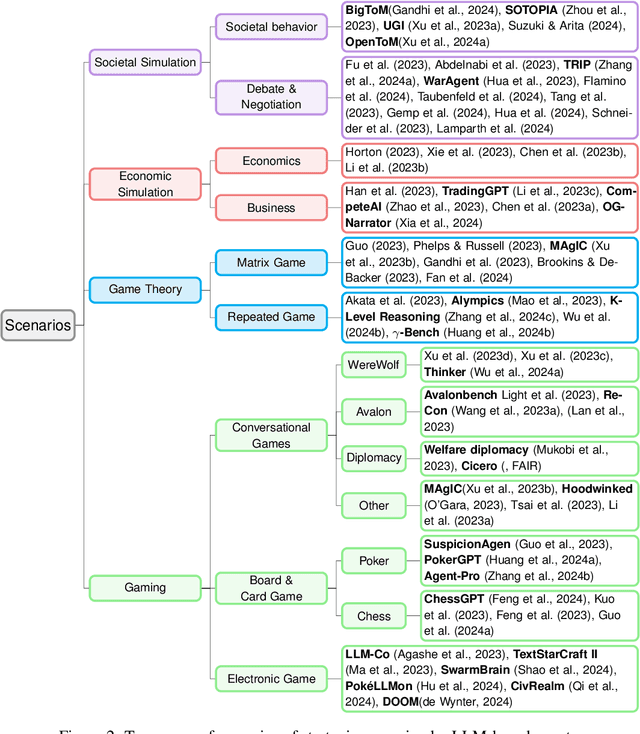

This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.
K-Level Reasoning with Large Language Models
Feb 02, 2024While Large Language Models (LLMs) have demonstrated their proficiency in complex reasoning tasks, their performance in dynamic, interactive, and competitive scenarios - such as business strategy and stock market analysis - remains underexplored. To bridge this gap, we formally explore the dynamic reasoning capabilities of LLMs for decision-making in rapidly evolving environments. We introduce two game theory-based pilot challenges that mirror the complexities of real-world dynamic decision-making. These challenges are well-defined, enabling clear, controllable, and precise evaluation of LLMs' dynamic reasoning abilities. Through extensive experiments, we find that existing reasoning methods tend to falter in dynamic settings that require k-level thinking - a key concept not tackled by previous works. To address this, we propose a novel reasoning approach for LLMs, named "K-Level Reasoning". This approach adopts the perspective of rivals to recursively employ k-level thinking based on available historical information, which significantly improves the prediction accuracy of rivals' subsequent moves and informs more strategic decision-making. This research not only sets a robust quantitative benchmark for the assessment of dynamic reasoning but also markedly enhances the proficiency of LLMs in dynamic contexts.