 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Temporal Action Detection with Proposal-Free Masking
Jul 14, 2022
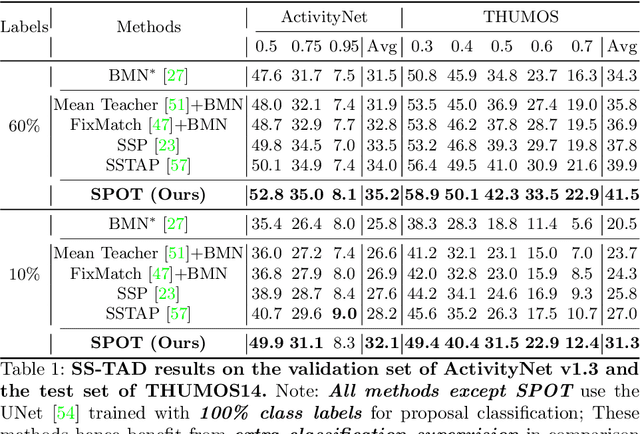
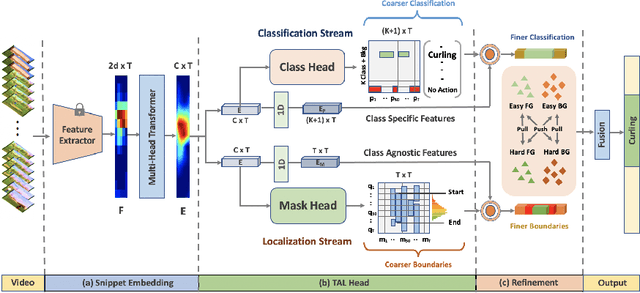
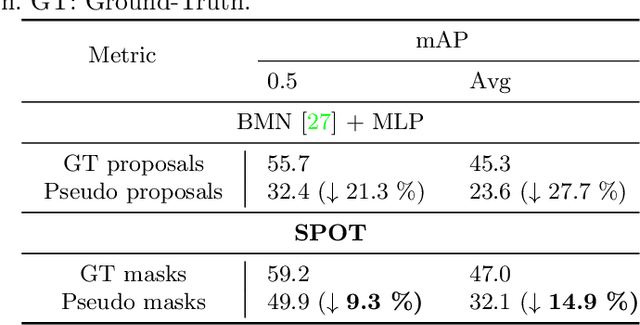
Existing temporal action detection (TAD) methods rely on a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAD (SS-TAD) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SS-TAD is also a much more challenging problem than supervised TAD, and consequently much under-studied. Prior SS-TAD methods directly combine an existing proposal-based TAD method and a SSL method. Due to their sequential localization (e.g, proposal generation) and classification design, they are prone to proposal error propagation. To overcome this limitation, in this work we propose a novel Semi-supervised Temporal action detection model based on PropOsal-free Temporal mask (SPOT) with a parallel localization (mask generation) and classification architecture. Such a novel design effectively eliminates the dependence between localization and classification by cutting off the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for prediction refinement, and a new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our SPOT outperforms state-of-the-art alternatives, often by a large margin. The PyTorch implementation of SPOT is available at https://github.com/sauradip/SPOT
Temporal Action Detection with Global Segmentation Mask Learning
Jul 14, 2022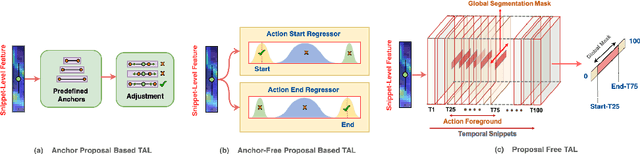
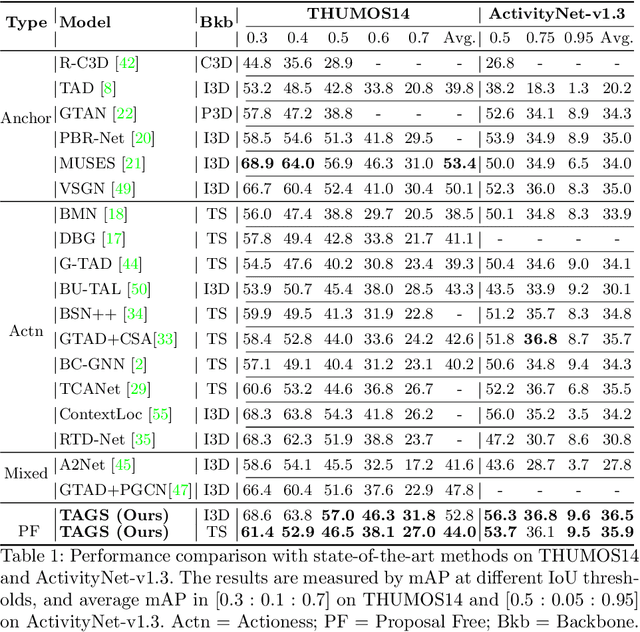
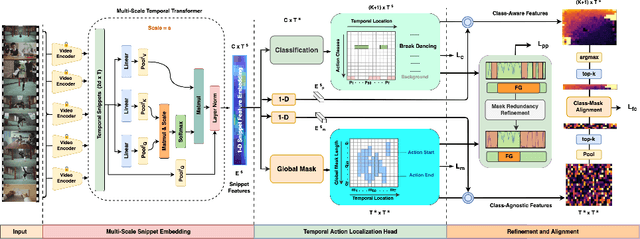
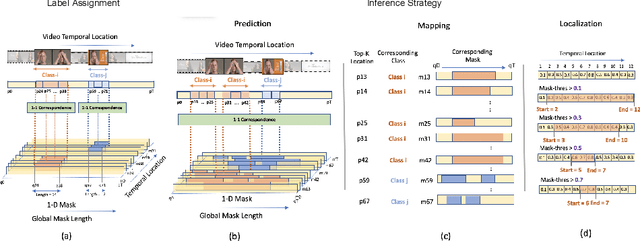
Existing temporal action detection (TAD) methods rely on generating an overwhelmingly large number of proposals per video. This leads to complex model designs due to proposal generation and/or per-proposal action instance evaluation and the resultant high computational cost. In this work, for the first time, we propose a proposal-free Temporal Action detection model with Global Segmentation mask (TAGS). Our core idea is to learn a global segmentation mask of each action instance jointly at the full video length. The TAGS model differs significantly from the conventional proposal-based methods by focusing on global temporal representation learning to directly detect local start and end points of action instances without proposals. Further, by modeling TAD holistically rather than locally at the individual proposal level, TAGS needs a much simpler model architecture with lower computational cost. Extensive experiments show that despite its simpler design, TAGS outperforms existing TAD methods, achieving new state-of-the-art performance on two benchmarks. Importantly, it is ~ 20x faster to train and ~1.6x more efficient for inference. Our PyTorch implementation of TAGS is available at https://github.com/sauradip/TAGS .
Adaptive Fine-Grained Sketch-Based Image Retrieval
Jul 06, 2022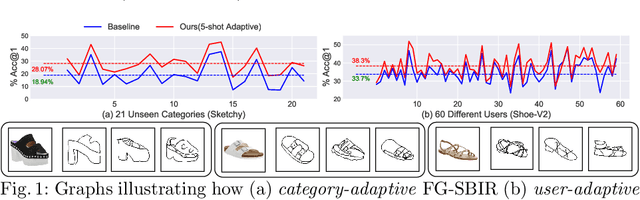
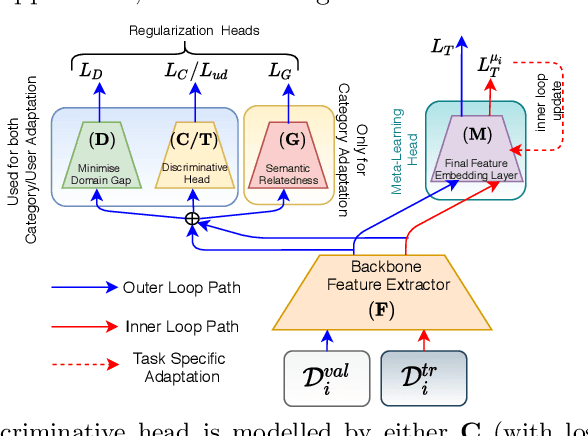
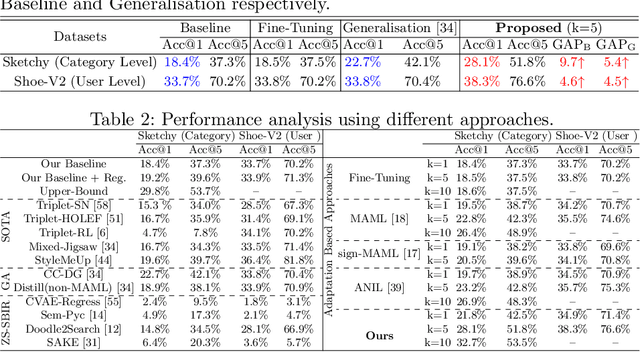
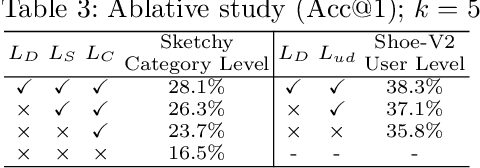
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted towards generalising a model to new categories without any training data from them. In real-world applications, however, a trained FG-SBIR model is often applied to both new categories and different human sketchers, i.e., different drawing styles. Although this complicates the generalisation problem, fortunately, a handful of examples are typically available, enabling the model to adapt to the new category/style. In this paper, we offer a novel perspective -- instead of asking for a model that generalises, we advocate for one that quickly adapts, with just very few samples during testing (in a few-shot manner). To solve this new problem, we introduce a novel model-agnostic meta-learning (MAML) based framework with several key modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the MAML training in the inner loop to make it more stable and tractable. (2) The margin in our contrastive loss is also meta-learned with the rest of the model. (3) Three additional regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR model more effective for category/style adaptation. Extensive experiments on public datasets suggest a large gain over generalisation and zero-shot based approaches, and a few strong few-shot baselines.
SceneTrilogy: On Scene Sketches and its Relationship with Text and Photo
Apr 25, 2022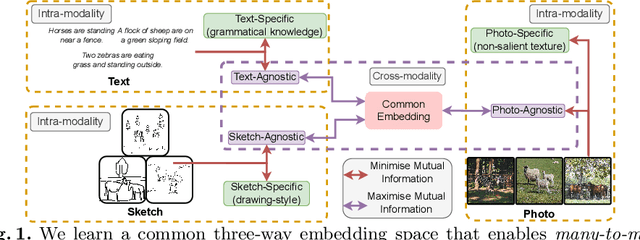
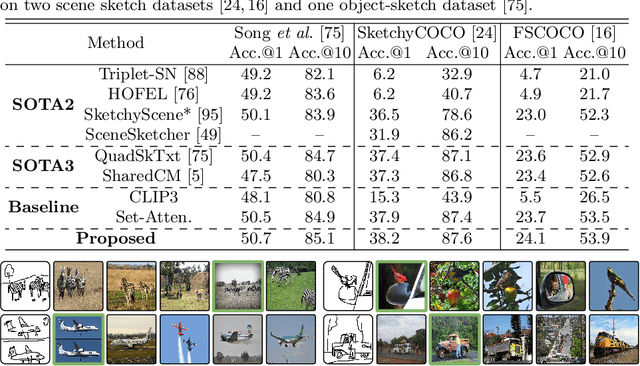
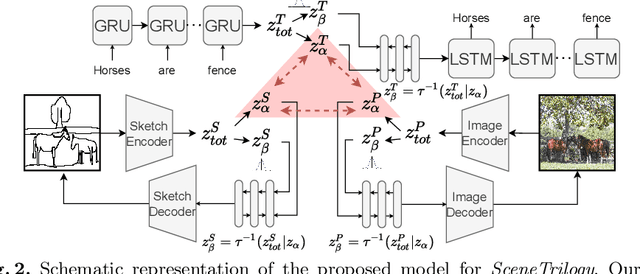

We for the first time extend multi-modal scene understanding to include that of free-hand scene sketches. This uniquely results in a trilogy of scene data modalities (sketch, text, and photo), where each offers unique perspectives for scene understanding, and together enable a series of novel scene-specific applications across discriminative (retrieval) and generative (captioning) tasks. Our key objective is to learn a common three-way embedding space that enables many-to-many modality interactions (e.g, sketch+text $\rightarrow$ photo retrieval). We importantly leverage the information bottleneck theory to achieve this goal, where we (i) decouple intra-modality information by minimising the mutual information between modality-specific and modality-agnostic components via a conditional invertible neural network, and (ii) align \textit{cross-modalities information} by maximising the mutual information between their modality-agnostic components using InfoNCE, with a specific multihead attention mechanism to allow many-to-many modality interactions. We spell out a few insights on the complementarity of each modality for scene understanding, and study for the first time a series of scene-specific applications like joint sketch- and text-based image retrieval, sketch captioning.
UIGR: Unified Interactive Garment Retrieval
Apr 06, 2022
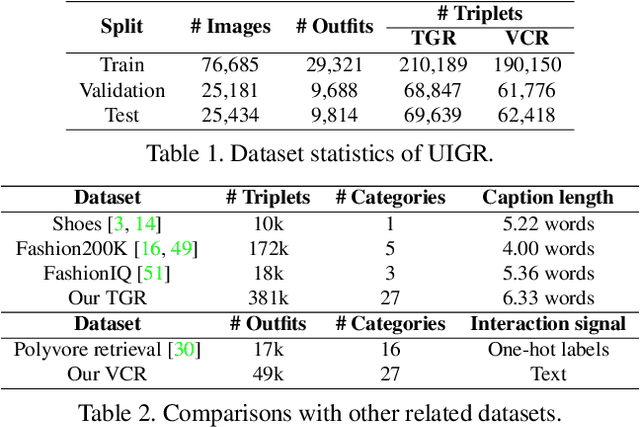
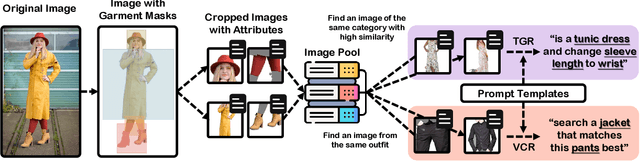
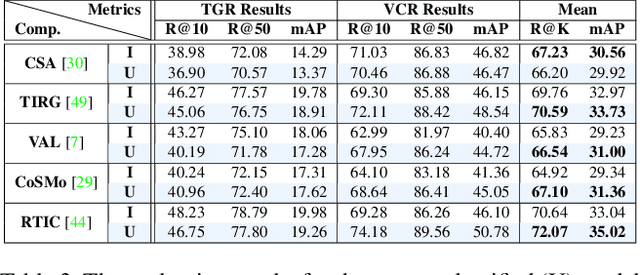
Interactive garment retrieval (IGR) aims to retrieve a target garment image based on a reference garment image along with user feedback on what to change on the reference garment. Two IGR tasks have been studied extensively: text-guided garment retrieval (TGR) and visually compatible garment retrieval (VCR). The user feedback for the former indicates what semantic attributes to change with the garment category preserved, while the category is the only thing to be changed explicitly for the latter, with an implicit requirement on style preservation. Despite the similarity between these two tasks and the practical need for an efficient system tackling both, they have never been unified and modeled jointly. In this paper, we propose a Unified Interactive Garment Retrieval (UIGR) framework to unify TGR and VCR. To this end, we first contribute a large-scale benchmark suited for both problems. We further propose a strong baseline architecture to integrate TGR and VCR in one model. Extensive experiments suggest that unifying two tasks in one framework is not only more efficient by requiring a single model only, it also leads to better performance. Code and datasets are available at https://github.com/BrandonHanx/CompFashion.
Style-Based Global Appearance Flow for Virtual Try-On
Apr 03, 2022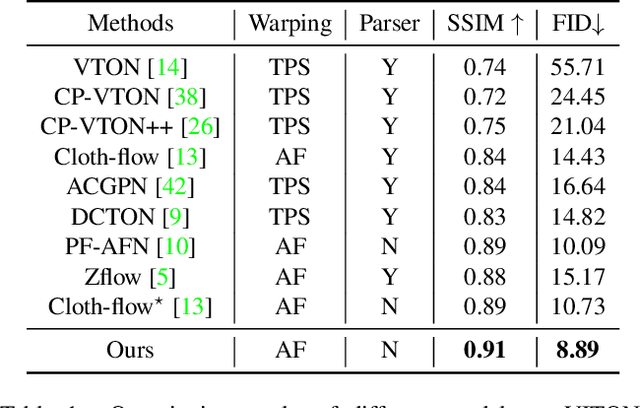
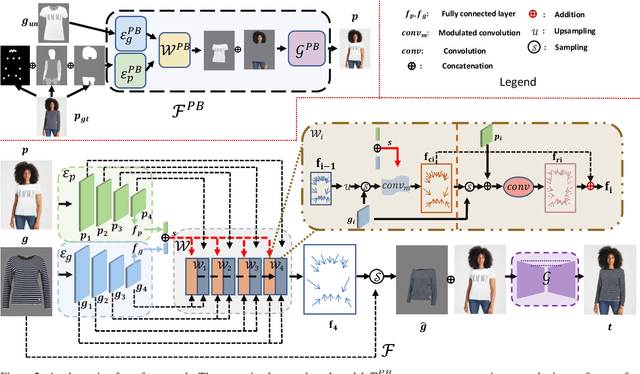

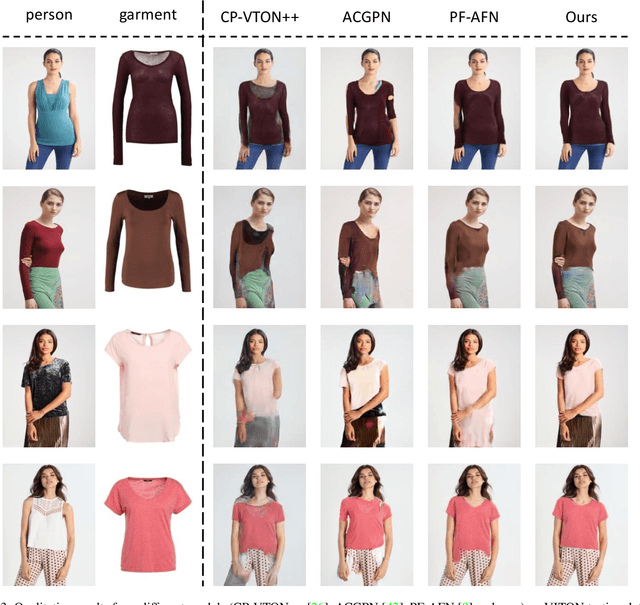
Image-based virtual try-on aims to fit an in-shop garment into a clothed person image. To achieve this, a key step is garment warping which spatially aligns the target garment with the corresponding body parts in the person image. Prior methods typically adopt a local appearance flow estimation model. They are thus intrinsically susceptible to difficult body poses/occlusions and large mis-alignments between person and garment images (see Fig.~\ref{fig:fig1}). To overcome this limitation, a novel global appearance flow estimation model is proposed in this work. For the first time, a StyleGAN based architecture is adopted for appearance flow estimation. This enables us to take advantage of a global style vector to encode a whole-image context to cope with the aforementioned challenges. To guide the StyleGAN flow generator to pay more attention to local garment deformation, a flow refinement module is introduced to add local context. Experiment results on a popular virtual try-on benchmark show that our method achieves new state-of-the-art performance. It is particularly effective in a `in-the-wild' application scenario where the reference image is full-body resulting in a large mis-alignment with the garment image (Fig.~\ref{fig:fig1} Top). Code is available at: \url{https://github.com/SenHe/Flow-Style-VTON}.
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches
Mar 28, 2022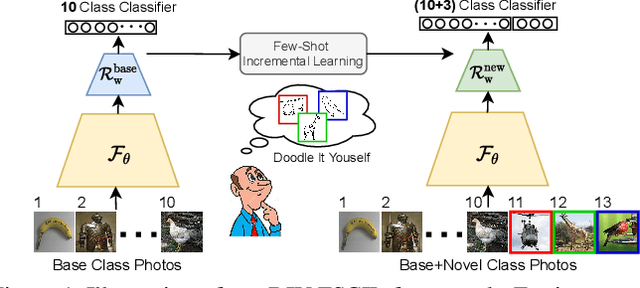
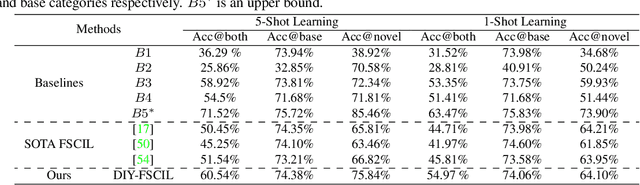
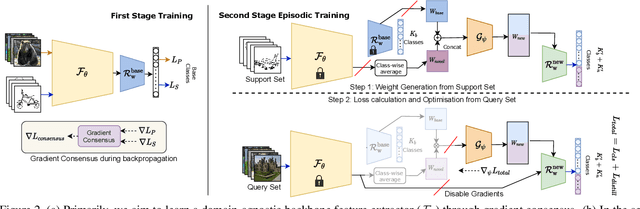

The human visual system is remarkable in learning new visual concepts from just a few examples. This is precisely the goal behind few-shot class incremental learning (FSCIL), where the emphasis is additionally placed on ensuring the model does not suffer from "forgetting". In this paper, we push the boundary further for FSCIL by addressing two key questions that bottleneck its ubiquitous application (i) can the model learn from diverse modalities other than just photo (as humans do), and (ii) what if photos are not readily accessible (due to ethical and privacy constraints). Our key innovation lies in advocating the use of sketches as a new modality for class support. The product is a "Doodle It Yourself" (DIY) FSCIL framework where the users can freely sketch a few examples of a novel class for the model to learn to recognize photos of that class. For that, we present a framework that infuses (i) gradient consensus for domain invariant learning, (ii) knowledge distillation for preserving old class information, and (iii) graph attention networks for message passing between old and novel classes. We experimentally show that sketches are better class support than text in the context of FSCIL, echoing findings elsewhere in the sketching literature.
Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Mar 28, 2022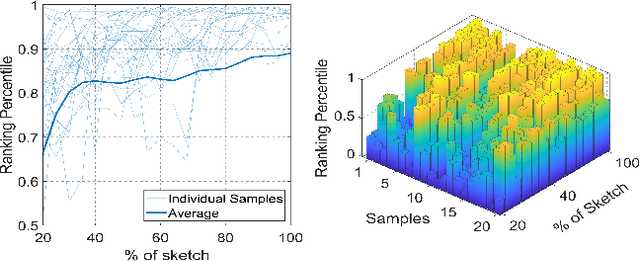
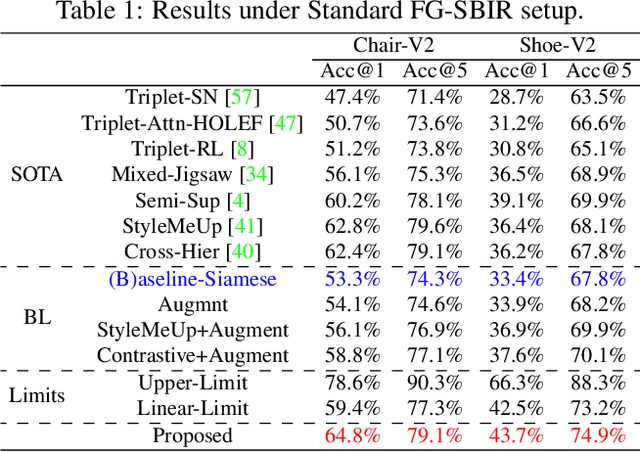
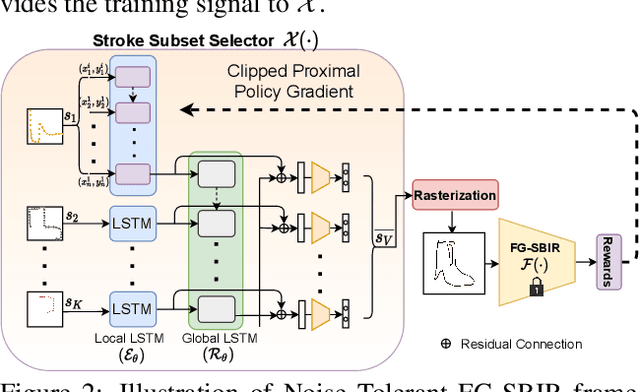
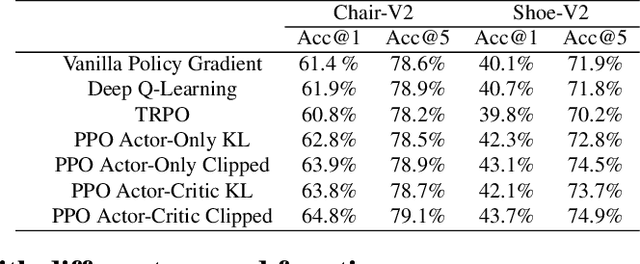
Sketching enables many exciting applications, notably, image retrieval. The fear-to-sketch problem (i.e., "I can't sketch") has however proven to be fatal for its widespread adoption. This paper tackles this "fear" head on, and for the first time, proposes an auxiliary module for existing retrieval models that predominantly lets the users sketch without having to worry. We first conducted a pilot study that revealed the secret lies in the existence of noisy strokes, but not so much of the "I can't sketch". We consequently design a stroke subset selector that {detects noisy strokes, leaving only those} which make a positive contribution towards successful retrieval. Our Reinforcement Learning based formulation quantifies the importance of each stroke present in a given subset, based on the extent to which that stroke contributes to retrieval. When combined with pre-trained retrieval models as a pre-processing module, we achieve a significant gain of 8%-10% over standard baselines and in turn report new state-of-the-art performance. Last but not least, we demonstrate the selector once trained, can also be used in a plug-and-play manner to empower various sketch applications in ways that were not previously possible.
Partially Does It: Towards Scene-Level FG-SBIR with Partial Input
Mar 28, 2022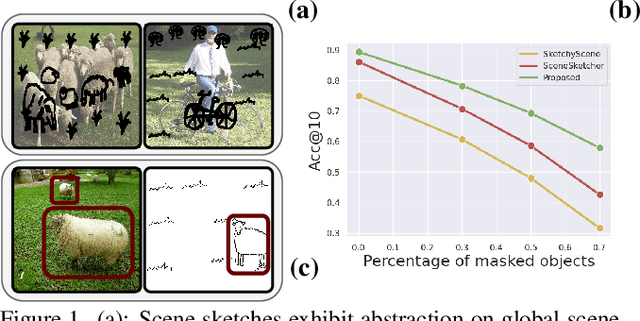
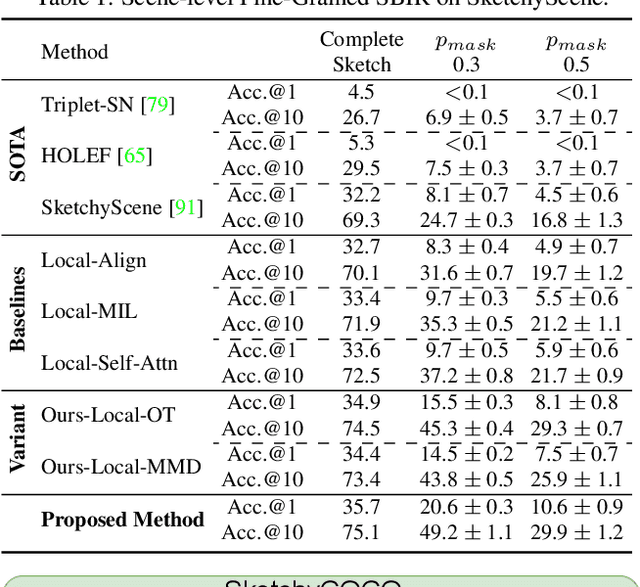
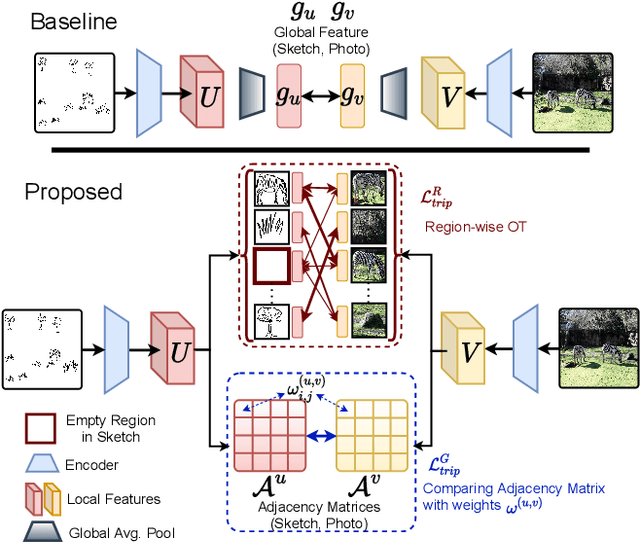
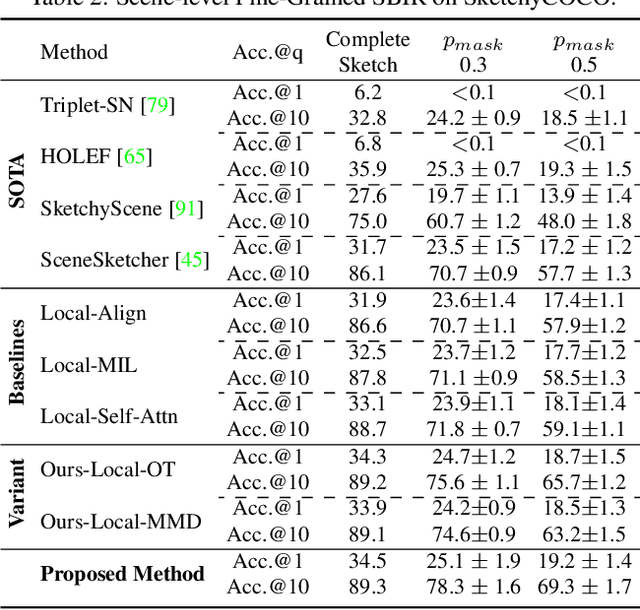
We scrutinise an important observation plaguing scene-level sketch research -- that a significant portion of scene sketches are "partial". A quick pilot study reveals: (i) a scene sketch does not necessarily contain all objects in the corresponding photo, due to the subjective holistic interpretation of scenes, (ii) there exists significant empty (white) regions as a result of object-level abstraction, and as a result, (iii) existing scene-level fine-grained sketch-based image retrieval methods collapse as scene sketches become more partial. To solve this "partial" problem, we advocate for a simple set-based approach using optimal transport (OT) to model cross-modal region associativity in a partially-aware fashion. Importantly, we improve upon OT to further account for holistic partialness by comparing intra-modal adjacency matrices. Our proposed method is not only robust to partial scene-sketches but also yields state-of-the-art performance on existing datasets.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022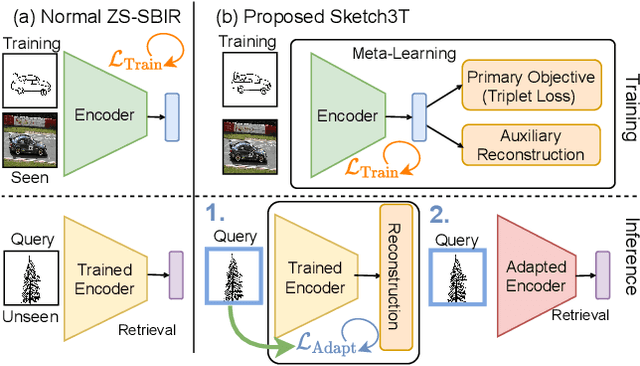
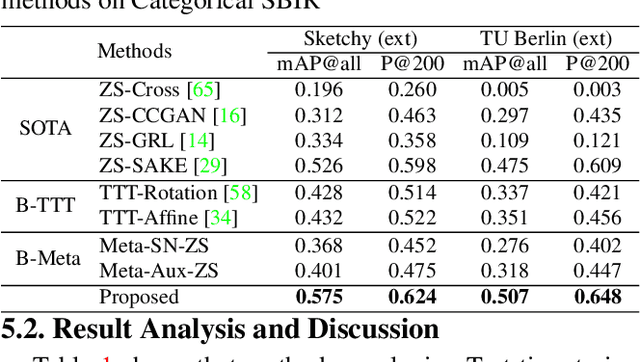
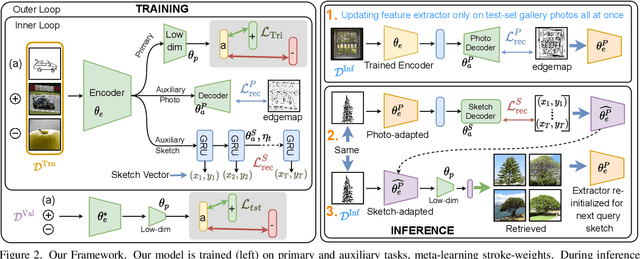
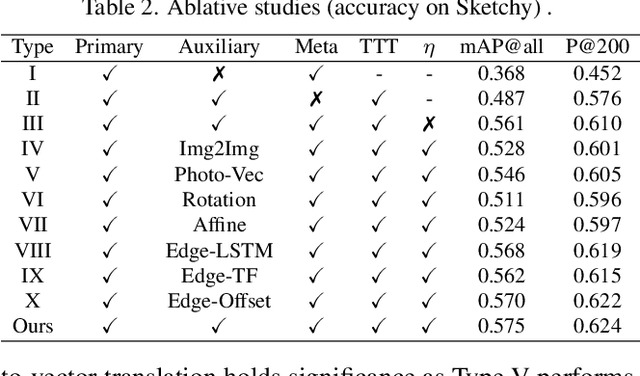
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.