 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Adapted Pipeline for Structured Information Extraction from Police Incident Announcements on Social Media
Dec 18, 2025Structured information extraction from police incident announcements is crucial for timely and accurate data processing, yet presents considerable challenges due to the variability and informal nature of textual sources such as social media posts. To address these challenges, we developed a domain-adapted extraction pipeline that leverages targeted prompt engineering with parameter-efficient fine-tuning of the Qwen2.5-7B model using Low-Rank Adaptation (LoRA). This approach enables the model to handle noisy, heterogeneous text while reliably extracting 15 key fields, including location, event characteristics, and impact assessment, from a high-quality, manually annotated dataset of 4,933 instances derived from 27,822 police briefing posts on Chinese Weibo (2019-2020). Experimental results demonstrated that LoRA-based fine-tuning significantly improved performance over both the base and instruction-tuned models, achieving an accuracy exceeding 98.36% for mortality detection and Exact Match Rates of 95.31% for fatality counts and 95.54% for province-level location extraction. The proposed pipeline thus provides a validated and efficient solution for multi-task structured information extraction in specialized domains, offering a practical framework for transforming unstructured text into reliable structured data in social science research.
ERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment
Dec 17, 2025RAW images have shown superior performance than sRGB images in many image processing tasks, especially for low-light image enhancement. However, most existing methods for RAW-based low-light enhancement usually sequentially process multi-scale information, which makes it difficult to achieve lightweight models and high processing speeds. Besides, they usually ignore the green channel superiority of RAW images, and fail to achieve better reconstruction performance with good use of green channel information. In this work, we propose an efficient RAW Image Enhancement Network (ERIENet), which parallelly processes multi-scale information with efficient convolution modules, and takes advantage of rich information in green channels to guide the reconstruction of images. Firstly, we introduce an efficient multi-scale fully-parallel architecture with a novel channel-aware residual dense block to extract feature maps, which reduces computational costs and achieves real-time processing speed. Secondly, we introduce a green channel guidance branch to exploit the rich information within the green channels of the input RAW image. It increases the quality of reconstruction results with few parameters and computations. Experiments on commonly used low-light image enhancement datasets show that ERIENet outperforms state-of-the-art methods in enhancing low-light RAW images with higher effiency. It also achieves an optimal speed of over 146 frame-per-second (FPS) for 4K-resolution images on a single NVIDIA GeForce RTX 3090 with 24G memory.
GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection
Dec 10, 2025



Building AI systems for GUI automation task has attracted remarkable research efforts, where MLLMs are leveraged for processing user requirements and give operations. However, GUI automation includes a wide range of tasks, from document processing to online shopping, from CAD to video editing. Diversity between particular tasks requires MLLMs for GUI automation to have heterogeneous capabilities and master multidimensional expertise, raising problems on constructing such a model. To address such challenge, we propose GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection, a novel MLLM-based GUI automation agent framework designed for integrating knowledge and combining capabilities from heterogeneous models to build GUI automation agent systems with higher performance. Since different GUI-specific MLLMs are trained on different dataset and thus have different strengths, GAIR introduced a general-purpose MLLM for jointly processing the information from multiple GUI-specific models, further enhancing performance of the agent framework. The general-purpose MLLM also serves as decision maker, trying to execute a reasonable operation based on previously gathered information. When the general-purpose model thinks that there isn't sufficient information for a reasonable decision, GAIR would transit into group reflection status, where the general-purpose model would provide GUI-specific models with different instructions and hints based on their strengths and weaknesses, driving them to gather information with more significance and accuracy that can support deeper reasoning and decision. We evaluated the effectiveness and reliability of GAIR through extensive experiments on GUI benchmarks.
JOGS: Joint Optimization of Pose Estimation and 3D Gaussian Splatting
Oct 30, 2025Traditional novel view synthesis methods heavily rely on external camera pose estimation tools such as COLMAP, which often introduce computational bottlenecks and propagate errors. To address these challenges, we propose a unified framework that jointly optimizes 3D Gaussian points and camera poses without requiring pre-calibrated inputs. Our approach iteratively refines 3D Gaussian parameters and updates camera poses through a novel co-optimization strategy, ensuring simultaneous improvements in scene reconstruction fidelity and pose accuracy. The key innovation lies in decoupling the joint optimization into two interleaved phases: first, updating 3D Gaussian parameters via differentiable rendering with fixed poses, and second, refining camera poses using a customized 3D optical flow algorithm that incorporates geometric and photometric constraints. This formulation progressively reduces projection errors, particularly in challenging scenarios with large viewpoint variations and sparse feature distributions, where traditional methods struggle. Extensive evaluations on multiple datasets demonstrate that our approach significantly outperforms existing COLMAP-free techniques in reconstruction quality, and also surpasses the standard COLMAP-based baseline in general.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025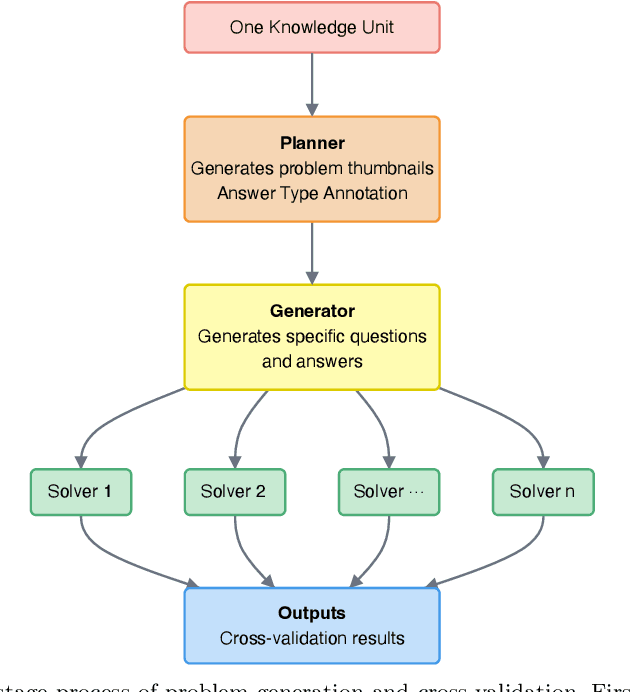
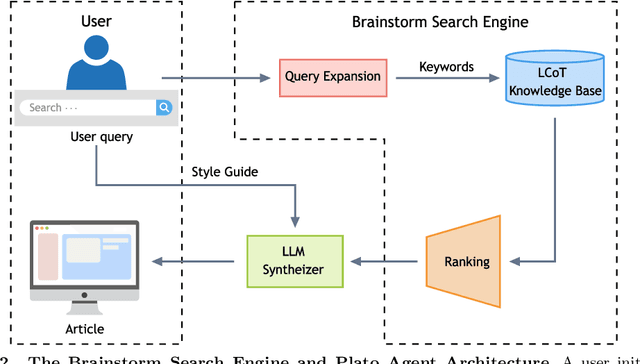
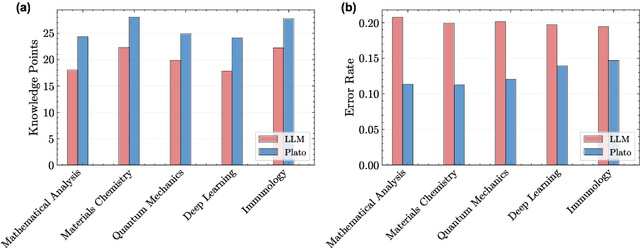
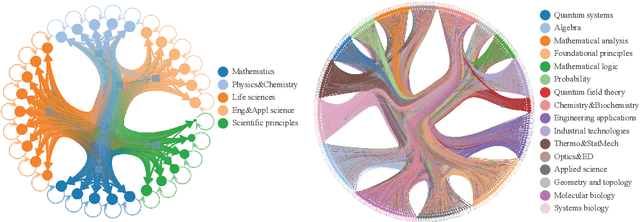
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
Arbitrarily-high-dimensional reconciliation via cross-rotation for continuous-variable quantum key distribution
Aug 08, 2025Multidimensional rotation serves as a powerful tool for enhancing information reconciliation and extending the transmission distance in continuous-variable quantum key distribution (CV-QKD). However, the lack of closed-form orthogonal transformations for high-dimensional rotations has limited the maximum reconciliation efficiency to channels with 8 dimensions over the past decade. This paper presents a cross-rotation scheme to overcome this limitation and enable reconciliation in arbitrarily high dimensions, constrained to even multiples of 8. The key treatment involves reshaping the string vector into matrix form and applying orthogonal transformations to its columns and rows in a cross manner, thereby increasing the reconciliation dimension by one order per cross-rotation while significantly reducing the communication overhead over the classical channel. A rigorous performance analysis is also presented from the perspective of achievable sum-rate. Simulation results demonstrate that 64-dimensional cross-rotation nearly approaches the upper bound, making it a recommended choice for practical implementations.
Joint parameter estimation and multidimensional reconciliation for CV-QKD
Aug 07, 2025Accurate quantum channel parameter estimation is essential for effective information reconciliation in continuous-variable quantum key distribution (CV-QKD). However, conventional maximum likelihood (ML) estimators rely on a large amount of discarded data (or pilot symbols), leading to a significant loss in symbol efficiency. Moreover, the separation between the estimation and reconciliation phases can introduce error propagation. In this paper, we propose a novel joint message-passing scheme that unifies channel parameter estimation and information reconciliation within a Bayesian framework. By leveraging the expectation-maximization (EM) algorithm, the proposed method simultaneously estimates unknown parameters during decoding, eliminating the need for separate ML estimation. Furthermore, we introduce a hybrid multidimensional rotation scheme that removes the requirement for norm feedback, significantly reducing classical channel overhead. To the best of our knowledge, this is the first work to unify multidimensional reconciliation and channel parameter estimation in CV-QKD, providing a practical solution for high-efficiency reconciliation with minimal pilots.
Dual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
Aug 06, 2025



Recently, prompt learning has demonstrated remarkable success in adapting pre-trained Vision-Language Models (VLMs) to various downstream tasks such as image classification. However, its application to the downstream Image-Text Retrieval (ITR) task is more challenging. We find that the challenge lies in discriminating both fine-grained attributes and similar subcategories of the downstream data. To address this challenge, we propose Dual prompt Learning with Joint Category-Attribute Reweighting (DCAR), a novel dual-prompt learning framework to achieve precise image-text matching. The framework dynamically adjusts prompt vectors from both semantic and visual dimensions to improve the performance of CLIP on the downstream ITR task. Based on the prompt paradigm, DCAR jointly optimizes attribute and class features to enhance fine-grained representation learning. Specifically, (1) at the attribute level, it dynamically updates the weights of attribute descriptions based on text-image mutual information correlation; (2) at the category level, it introduces negative samples from multiple perspectives with category-matching weighting to learn subcategory distinctions. To validate our method, we construct the Fine-class Described Retrieval Dataset (FDRD), which serves as a challenging benchmark for ITR in downstream data domains. It covers over 1,500 downstream fine categories and 230,000 image-caption pairs with detailed attribute annotations. Extensive experiments on FDRD demonstrate that DCAR achieves state-of-the-art performance over existing baselines.
CorrMoE: Mixture of Experts with De-stylization Learning for Cross-Scene and Cross-Domain Correspondence Pruning
Jul 16, 2025Establishing reliable correspondences between image pairs is a fundamental task in computer vision, underpinning applications such as 3D reconstruction and visual localization. Although recent methods have made progress in pruning outliers from dense correspondence sets, they often hypothesize consistent visual domains and overlook the challenges posed by diverse scene structures. In this paper, we propose CorrMoE, a novel correspondence pruning framework that enhances robustness under cross-domain and cross-scene variations. To address domain shift, we introduce a De-stylization Dual Branch, performing style mixing on both implicit and explicit graph features to mitigate the adverse influence of domain-specific representations. For scene diversity, we design a Bi-Fusion Mixture of Experts module that adaptively integrates multi-perspective features through linear-complexity attention and dynamic expert routing. Extensive experiments on benchmark datasets demonstrate that CorrMoE achieves superior accuracy and generalization compared to state-of-the-art methods. The code and pre-trained models are available at https://github.com/peiwenxia/CorrMoE.