 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Your Tone: Introducing a New Dataset for Polite Language Rewrite
Dec 20, 2022We introduce \textsc{PoliteRewrite} -- a dataset for polite language rewrite which is a novel sentence rewrite task. Compared with previous text style transfer tasks that can be mostly addressed by slight token- or phrase-level edits, polite language rewrite requires deep understanding and extensive sentence-level edits over an offensive and impolite sentence to deliver the same message euphemistically and politely, which is more challenging -- not only for NLP models but also for human annotators to rewrite with effort. To alleviate the human effort for efficient annotation, we first propose a novel annotation paradigm by a collaboration of human annotators and GPT-3.5 to annotate \textsc{PoliteRewrite}. The released dataset has 10K polite sentence rewrites annotated collaboratively by GPT-3.5 and human, which can be used as gold standard for training, validation and test; and 100K high-quality polite sentence rewrites by GPT-3.5 without human review. We wish this work (The dataset (10K+100K) will be released soon) could contribute to the research on more challenging sentence rewrite, and provoke more thought in future on resource annotation paradigm with the help of the large-scaled pretrained models.
Extensible Prompts for Language Models
Dec 01, 2022We propose eXtensible Prompt (X-Prompt) for prompting a large language model (LLM) beyond natural language (NL). X-Prompt instructs an LLM with not only NL but also an extensible vocabulary of imaginary words that are introduced to help represent what NL words hardly describe, allowing a prompt to be more descriptive. Like NL prompts, X-Prompt is out-of-distribution (OOD) robust, for which we propose context-guided learning with prompt augmentation to learn its imaginary words for general usability, enabling them to use in different prompt contexts for fine-grain specifications. The promising results of X-Prompt demonstrate its potential of approaching advanced interaction between humans and LLMs to bridge their communication gap.
Lossless Acceleration for Seq2seq Generation with Aggressive Decoding
May 20, 2022We study lossless acceleration for seq2seq generation with a novel decoding algorithm -- Aggressive Decoding. Unlike the previous efforts (e.g., non-autoregressive decoding) speeding up seq2seq generation at the cost of quality loss, our approach aims to yield the identical (or better) generation compared with autoregressive decoding but in a significant speedup, achieved by innovative cooperation of aggressive decoding and verification that are both efficient due to parallel computing. We propose two Aggressive Decoding paradigms for 2 kinds of seq2seq tasks: 1) For the seq2seq tasks whose inputs and outputs are highly similar (e.g., Grammatical Error Correction), we propose Input-guided Aggressive Decoding (IAD) that aggressively copies from the input sentence as drafted decoded tokens to verify in parallel; 2) For other general seq2seq tasks (e.g., Machine Translation), we propose Generalized Aggressive Decoding (GAD) that first employs an additional non-autoregressive decoding model for aggressive decoding and then verifies in parallel in the autoregressive manner. We test Aggressive Decoding on the most popular 6-layer Transformer model on GPU in multiple seq2seq tasks: 1) For IAD, we show that it can introduce a 7x-9x speedup for the Transformer in Grammatical Error Correction and Text Simplification tasks with the identical results as greedy decoding; 2) For GAD, we observe a 3x-5x speedup with the identical or even better quality in two important seq2seq tasks: Machine Translation and Abstractive Summarization. Moreover, Aggressive Decoding can benefit even more from stronger computing devices that are better at parallel computing. Given the lossless quality as well as significant and promising speedup, we believe Aggressive Decoding may potentially evolve into a de facto standard for efficient and lossless seq2seq generation in the near future.
Text Revision by On-the-Fly Representation Optimization
Apr 15, 2022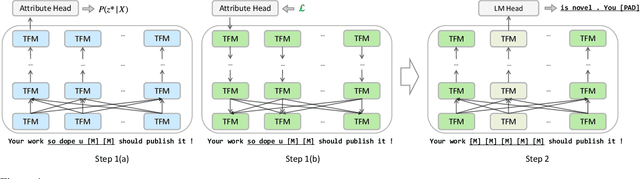
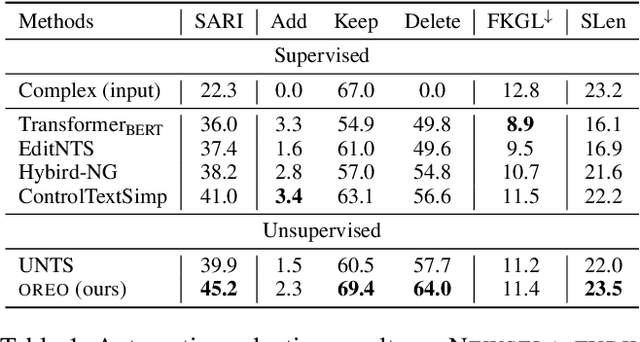
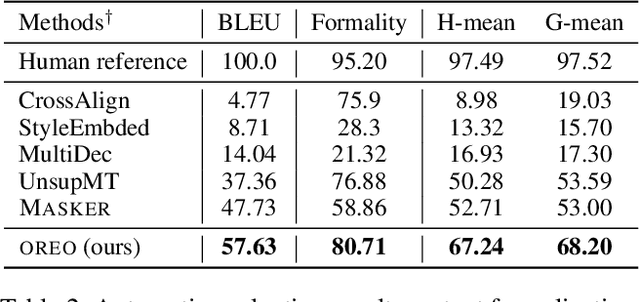
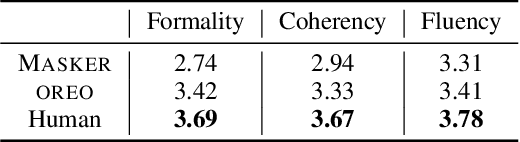
Text revision refers to a family of natural language generation tasks, where the source and target sequences share moderate resemblance in surface form but differentiate in attributes, such as text formality and simplicity. Current state-of-the-art methods formulate these tasks as sequence-to-sequence learning problems, which rely on large-scale parallel training corpus. In this paper, we present an iterative in-place editing approach for text revision, which requires no parallel data. In this approach, we simply fine-tune a pre-trained Transformer with masked language modeling and attribute classification. During inference, the editing at each iteration is realized by two-step span replacement. At the first step, the distributed representation of the text optimizes on the fly towards an attribute function. At the second step, a text span is masked and another new one is proposed conditioned on the optimized representation. The empirical experiments on two typical and important text revision tasks, text formalization and text simplification, show the effectiveness of our approach. It achieves competitive and even better performance than state-of-the-art supervised methods on text simplification, and gains better performance than strong unsupervised methods on text formalization \footnote{Code and model are available at \url{https://github.com/jingjingli01/OREO}}.
Lossless Speedup of Autoregressive Translation with Generalized Aggressive Decoding
Apr 02, 2022In this paper, we propose Generalized Aggressive Decoding (GAD) -- a novel decoding paradigm for speeding up autoregressive translation without quality loss, through the collaboration of autoregressive and non-autoregressive translation (NAT) of the Transformer. At each decoding iteration, GAD aggressively decodes a number of tokens in parallel as a draft with NAT and then verifies them in the autoregressive manner, where only the tokens that pass the verification are kept as decoded tokens. GAD can achieve the same performance as autoregressive translation but much more efficiently because both NAT drafting and autoregressive verification are fast due to parallel computing. We conduct experiments in the WMT14 English-German translation task and confirm that the vanilla GAD yields exactly the same results as greedy decoding with an around 3x speedup, and that its variant (GAD++) with an advanced verification strategy not only outperforms the greedy translation and even achieves the comparable translation quality with the beam search result, but also further improves the decoding speed, resulting in an around 5x speedup over autoregressive translation. Our models and codes are available at https://github.com/hemingkx/Generalized-Aggressive-Decoding.
EdgeFormer: A Parameter-Efficient Transformer for On-Device Seq2seq Generation
Feb 16, 2022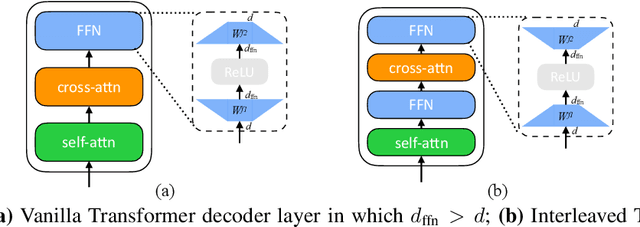
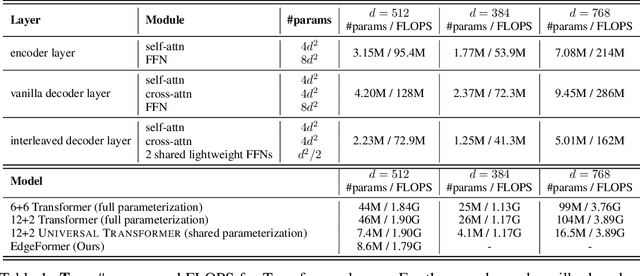
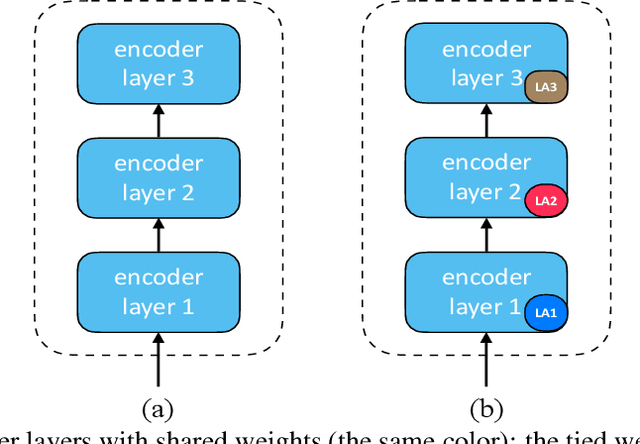
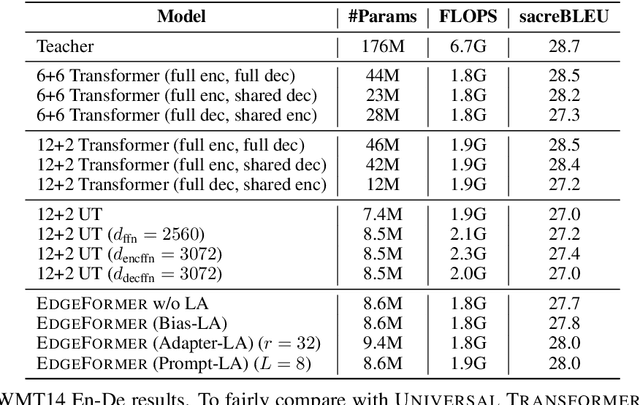
We propose EdgeFormer -- a parameter-efficient Transformer of the encoder-decoder architecture for on-device seq2seq generation, which is customized under the strict computation and memory constraints. EdgeFormer proposes two novel principles for cost-effective parameterization and further enhance the model with efficient layer adaptation. We conduct extensive experiments on two practical on-device seq2seq tasks: Machine Translation and Grammatical Error Correction, and show that EdgeFormer can effectively outperform previous parameter-efficient Transformer baselines and achieve very competitive results with knowledge distillation under both the computation and memory constraints.
A Metal Artifact Reduction Scheme For Accurate Iterative Dual-Energy CT Algorithms
Jan 31, 2022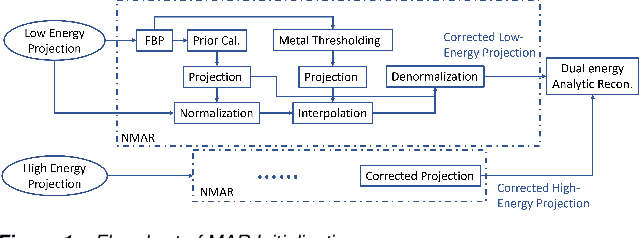
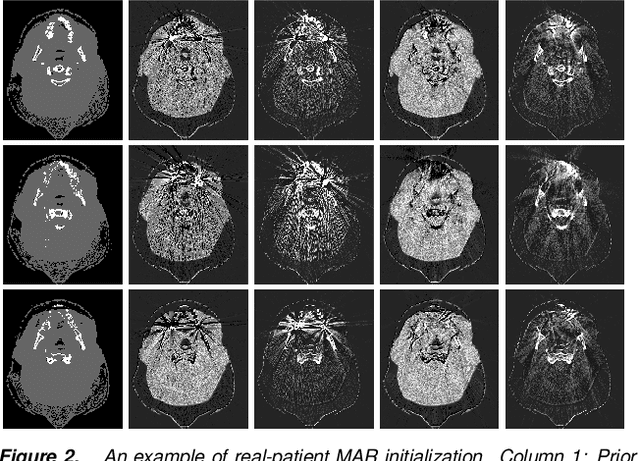

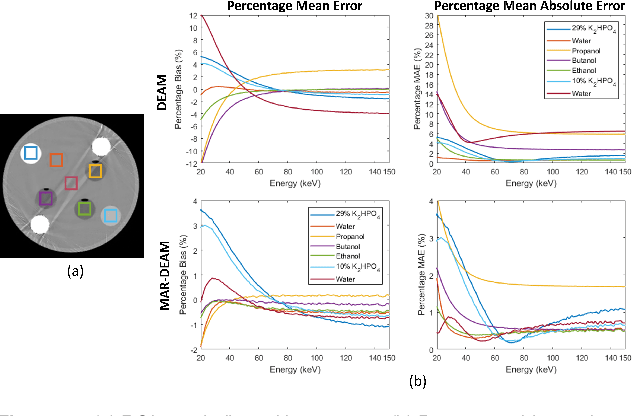
CT images have been used to generate radiation therapy treatment plans for more than two decades. Dual-energy CT (DECT) has shown high accuracy in estimating electronic density or proton stopping-power maps used in treatment planning. However, the presence of metal implants introduces severe streaking artifacts in the reconstructed images, affecting the diagnostic accuracy and treatment performance. In order to reduce the metal artifacts in DECT, we introduce a metal-artifact reduction scheme for iterative DECT algorithms. An estimate is substituted for the corrupt data in each iteration. We utilize normalized metal-artifact reduction (NMAR) composed with image-domain decomposition to initialize the algorithm and speed up the convergence. A fully 3D joint statistical DECT algorithm, dual-energy alternating minimization (DEAM), with the proposed scheme is tested on experimental and clinical helical data acquired on a Philips Brilliance Big Bore scanner. We compared DEAM with the proposed method to the original DEAM and vendor reconstructions with and without metal-artifact reduction for orthopedic implants (O-MAR). The visualization and quantitative analysis show that DEAM with the proposed method has the best performance in reducing streaking artifacts caused by metallic objects.
A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-Lingual Language Model
Jan 26, 2022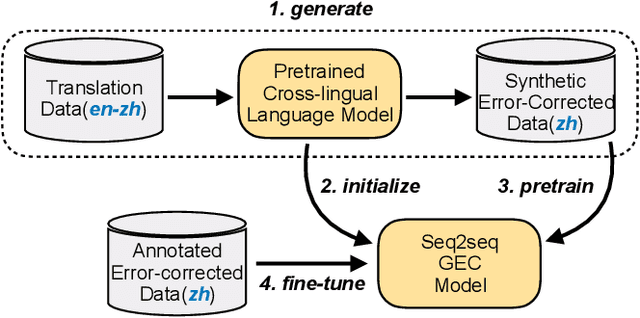

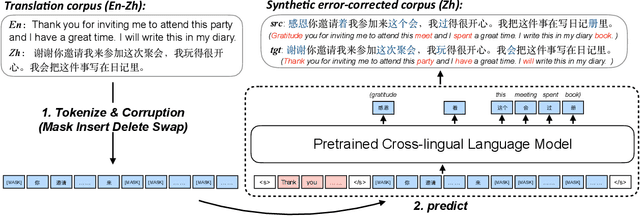
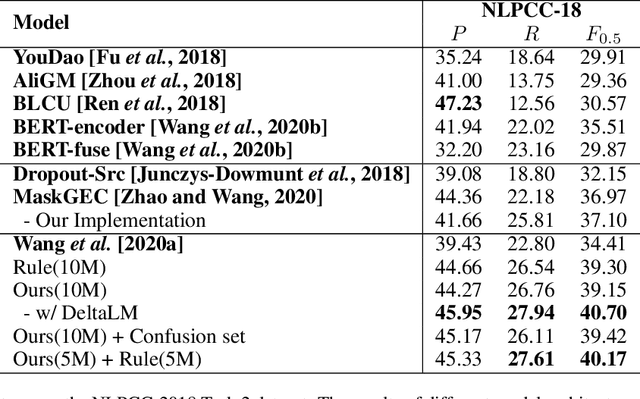
Synthetic data construction of Grammatical Error Correction (GEC) for non-English languages relies heavily on human-designed and language-specific rules, which produce limited error-corrected patterns. In this paper, we propose a generic and language-independent strategy for multilingual GEC, which can train a GEC system effectively for a new non-English language with only two easy-to-access resources: 1) a pretrained cross-lingual language model (PXLM) and 2) parallel translation data between English and the language. Our approach creates diverse parallel GEC data without any language-specific operations by taking the non-autoregressive translation generated by PXLM and the gold translation as error-corrected sentence pairs. Then, we reuse PXLM to initialize the GEC model and pretrain it with the synthetic data generated by itself, which yields further improvement. We evaluate our approach on three public benchmarks of GEC in different languages. It achieves the state-of-the-art results on the NLPCC 2018 Task 2 dataset (Chinese) and obtains competitive performance on Falko-Merlin (German) and RULEC-GEC (Russian). Further analysis demonstrates that our data construction method is complementary to rule-based approaches.
Beyond Preserved Accuracy: Evaluating Loyalty and Robustness of BERT Compression
Sep 07, 2021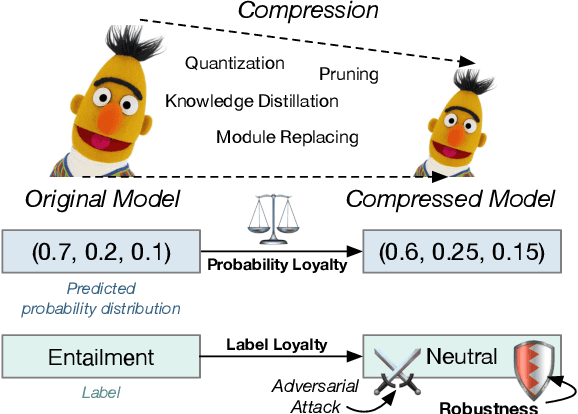
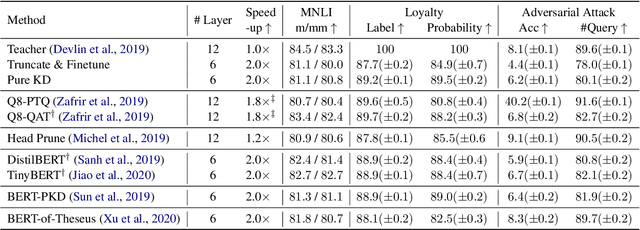
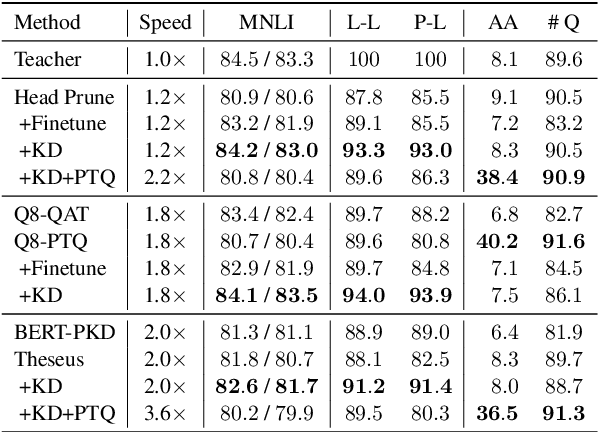
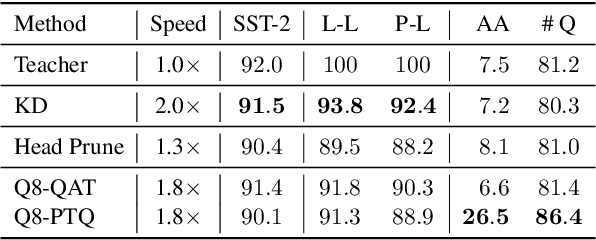
Recent studies on compression of pretrained language models (e.g., BERT) usually use preserved accuracy as the metric for evaluation. In this paper, we propose two new metrics, label loyalty and probability loyalty that measure how closely a compressed model (i.e., student) mimics the original model (i.e., teacher). We also explore the effect of compression with regard to robustness under adversarial attacks. We benchmark quantization, pruning, knowledge distillation and progressive module replacing with loyalty and robustness. By combining multiple compression techniques, we provide a practical strategy to achieve better accuracy, loyalty and robustness.
A Machine-learning Based Initialization for Joint Statistical Iterative Dual-energy CT with Application to Proton Therapy
Jul 30, 2021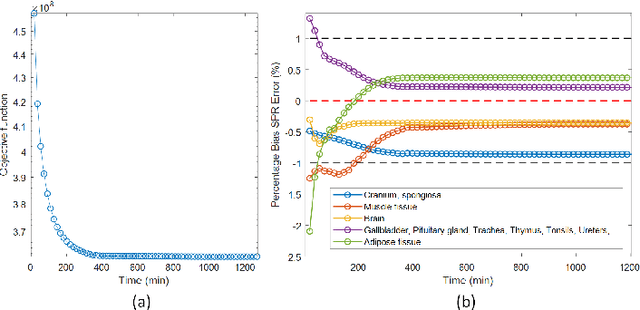
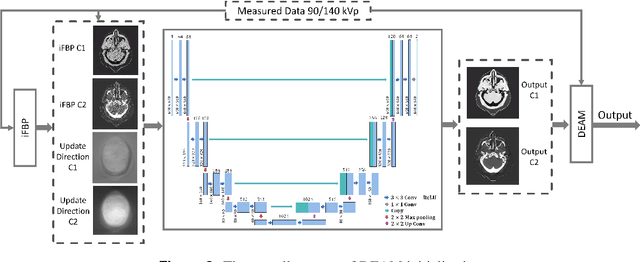
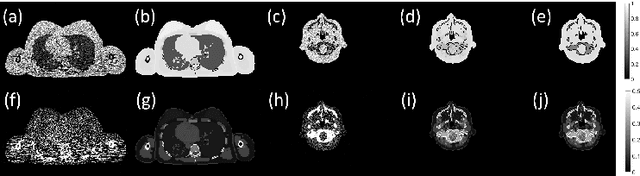
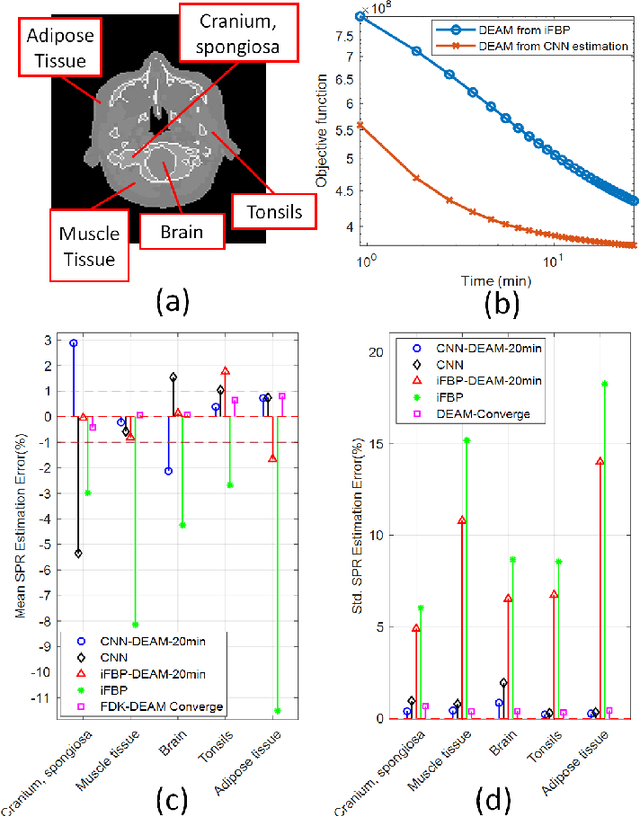
Dual-energy CT (DECT) has been widely investigated to generate more informative and more accurate images in the past decades. For example, Dual-Energy Alternating Minimization (DEAM) algorithm achieves sub-percentage uncertainty in estimating proton stopping-power mappings from experimental 3-mm collimated phantom data. However, elapsed time of iterative DECT algorithms is not clinically acceptable, due to their low convergence rate and the tremendous geometry of modern helical CT scanners. A CNN-based initialization method is introduced to reduce the computational time of iterative DECT algorithms. DEAM is used as an example of iterative DECT algorithms in this work. The simulation results show that our method generates denoised images with greatly improved estimation accuracy for adipose, tonsils, and muscle tissue. Also, it reduces elapsed time by approximately 5-fold for DEAM to reach the same objective function value for both simulated and real data.