 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Hybrid Rule and Neural Network Based Semantic Tagger using Silver Standard Data: the PyMUSAS framework for Multilingual Semantic Annotation
Jan 14, 2026Word Sense Disambiguation (WSD) has been widely evaluated using the semantic frameworks of WordNet, BabelNet, and the Oxford Dictionary of English. However, for the UCREL Semantic Analysis System (USAS) framework, no open extensive evaluation has been performed beyond lexical coverage or single language evaluation. In this work, we perform the largest semantic tagging evaluation of the rule based system that uses the lexical resources in the USAS framework covering five different languages using four existing datasets and one novel Chinese dataset. We create a new silver labelled English dataset, to overcome the lack of manually tagged training data, that we train and evaluate various mono and multilingual neural models in both mono and cross-lingual evaluation setups with comparisons to their rule based counterparts, and show how a rule based system can be enhanced with a neural network model. The resulting neural network models, including the data they were trained on, the Chinese evaluation dataset, and all of the code have been released as open resources.
HealthcareNLP: where are we and what is next?
Dec 09, 2025

This proposed tutorial focuses on Healthcare Domain Applications of NLP, what we have achieved around HealthcareNLP, and the challenges that lie ahead for the future. Existing reviews in this domain either overlook some important tasks, such as synthetic data generation for addressing privacy concerns, or explainable clinical NLP for improved integration and implementation, or fail to mention important methodologies, including retrieval augmented generation and the neural symbolic integration of LLMs and KGs. In light of this, the goal of this tutorial is to provide an introductory overview of the most important sub-areas of a patient- and resource-oriented HealthcareNLP, with three layers of hierarchy: data/resource layer: annotation guidelines, ethical approvals, governance, synthetic data; NLP-Eval layer: NLP tasks such as NER, RE, sentiment analysis, and linking/coding with categorised methods, leading to explainable HealthAI; patients layer: Patient Public Involvement and Engagement (PPIE), health literacy, translation, simplification, and summarisation (also NLP tasks), and shared decision-making support. A hands-on session will be included in the tutorial for the audience to use HealthcareNLP applications. The target audience includes NLP practitioners in the healthcare application domain, NLP researchers who are interested in domain applications, healthcare researchers, and students from NLP fields. The type of tutorial is "Introductory to CL/NLP topics (HealthcareNLP)" and the audience does not need prior knowledge to attend this. Tutorial materials: https://github.com/4dpicture/HealthNLP
Multi-task Learning of Negation and Speculation for Targeted Sentiment Classification
Oct 16, 2020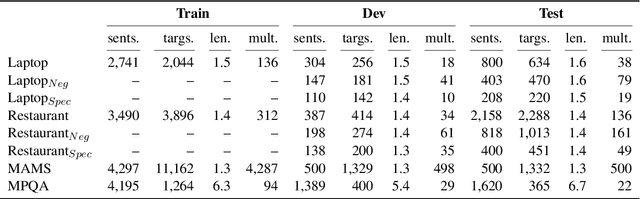
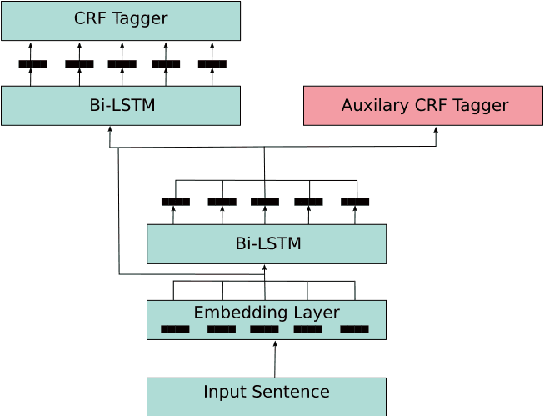

The majority of work in targeted sentiment analysis has concentrated on finding better methods to improve the overall results. Within this paper we show that these models are not robust to linguistic phenomena, specifically negation and speculation. In this paper, we propose a multi-task learning method to incorporate information from syntactic and semantic auxiliary tasks, including negation and speculation scope detection, to create models that are more robust to these phenomena. Further we create two challenge datasets to evaluate model performance on negated and speculative samples. We find that multi-task models and transfer learning from a language model can improve performance on these challenge datasets. However the results indicate that there is still much room for improvement in making our models more robust to linguistic phenomena such as negation and speculation.
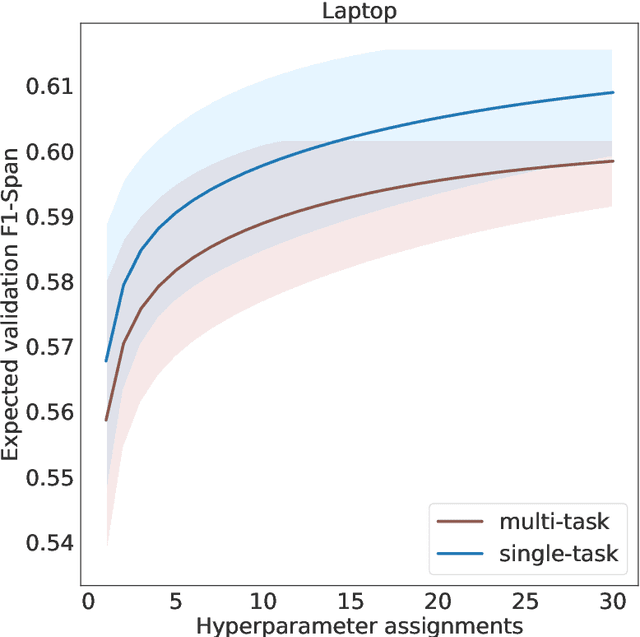
FIESTA: Fast IdEntification of State-of-The-Art models using adaptive bandit algorithms
Jun 28, 2019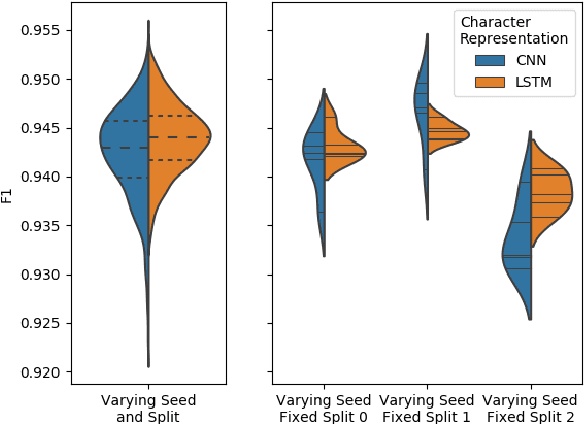

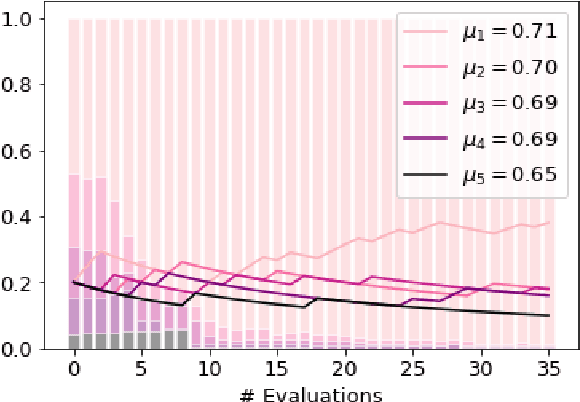
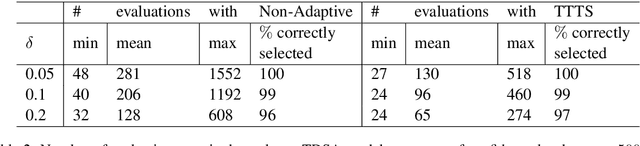
We present FIESTA, a model selection approach that significantly reduces the computational resources required to reliably identify state-of-the-art performance from large collections of candidate models. Despite being known to produce unreliable comparisons, it is still common practice to compare model evaluations based on single choices of random seeds. We show that reliable model selection also requires evaluations based on multiple train-test splits (contrary to common practice in many shared tasks). Using bandit theory from the statistics literature, we are able to adaptively determine appropriate numbers of data splits and random seeds used to evaluate each model, focusing computational resources on the evaluation of promising models whilst avoiding wasting evaluations on models with lower performance. Furthermore, our user-friendly Python implementation produces confidence guarantees of correctly selecting the optimal model. We evaluate our algorithms by selecting between 8 target-dependent sentiment analysis methods using dramatically fewer model evaluations than current model selection approaches.
Bringing replication and reproduction together with generalisability in NLP: Three reproduction studies for Target Dependent Sentiment Analysis
Aug 06, 2018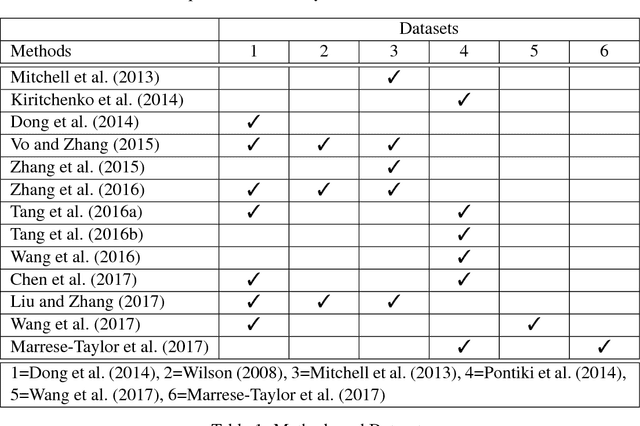
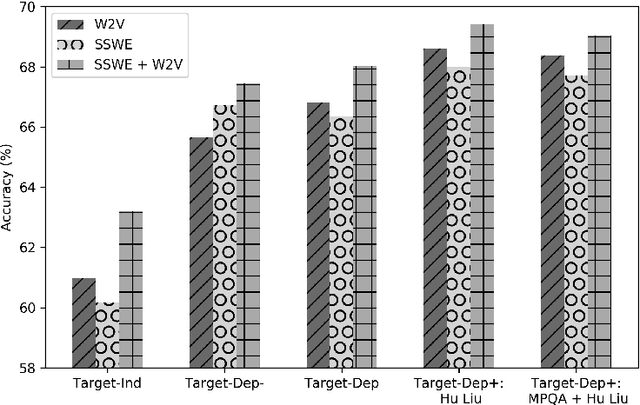
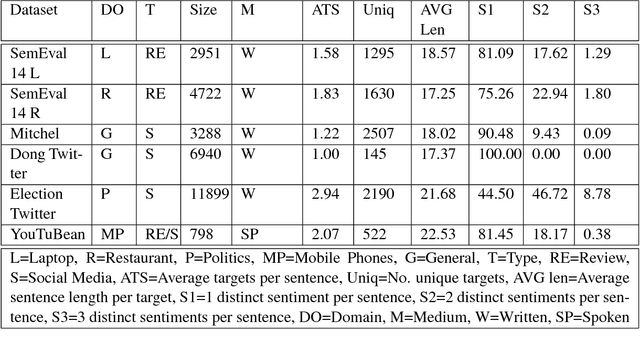
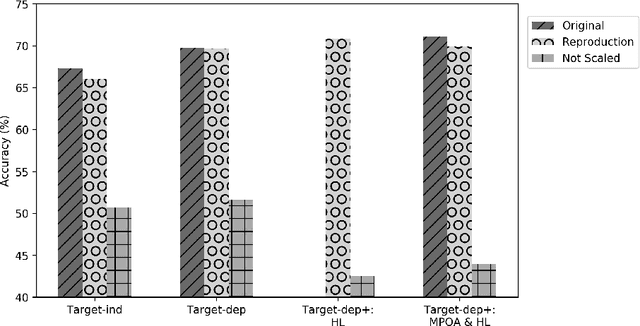
Lack of repeatability and generalisability are two significant threats to continuing scientific development in Natural Language Processing. Language models and learning methods are so complex that scientific conference papers no longer contain enough space for the technical depth required for replication or reproduction. Taking Target Dependent Sentiment Analysis as a case study, we show how recent work in the field has not consistently released code, or described settings for learning methods in enough detail, and lacks comparability and generalisability in train, test or validation data. To investigate generalisability and to enable state of the art comparative evaluations, we carry out the first reproduction studies of three groups of complementary methods and perform the first large-scale mass evaluation on six different English datasets. Reflecting on our experiences, we recommend that future replication or reproduction experiments should always consider a variety of datasets alongside documenting and releasing their methods and published code in order to minimise the barriers to both repeatability and generalisability. We have released our code with a model zoo on GitHub with Jupyter Notebooks to aid understanding and full documentation, and we recommend that others do the same with their papers at submission time through an anonymised GitHub account.
Lancaster A at SemEval-2017 Task 5: Evaluation metrics matter: predicting sentiment from financial news headlines
May 01, 2017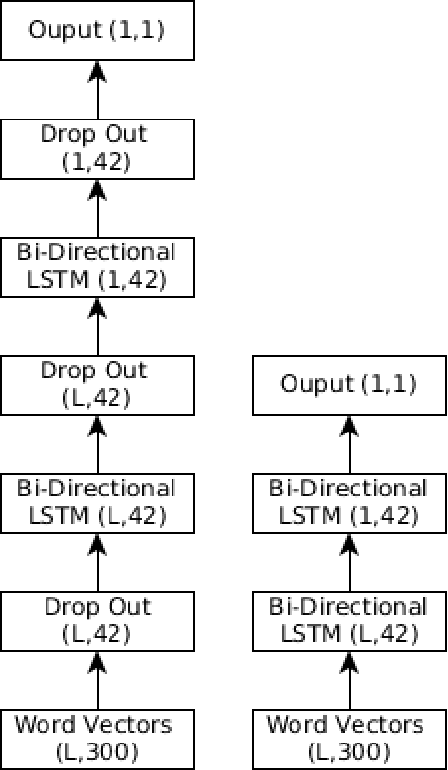
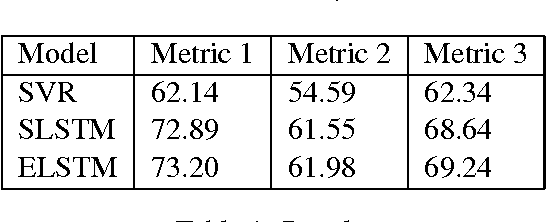
This paper describes our participation in Task 5 track 2 of SemEval 2017 to predict the sentiment of financial news headlines for a specific company on a continuous scale between -1 and 1. We tackled the problem using a number of approaches, utilising a Support Vector Regression (SVR) and a Bidirectional Long Short-Term Memory (BLSTM). We found an improvement of 4-6% using the LSTM model over the SVR and came fourth in the track. We report a number of different evaluations using a finance specific word embedding model and reflect on the effects of using different evaluation metrics.
The Anchors Hierachy: Using the triangle inequality to survive high dimensional data
Jan 16, 2013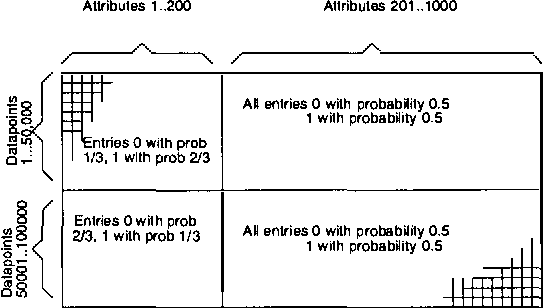

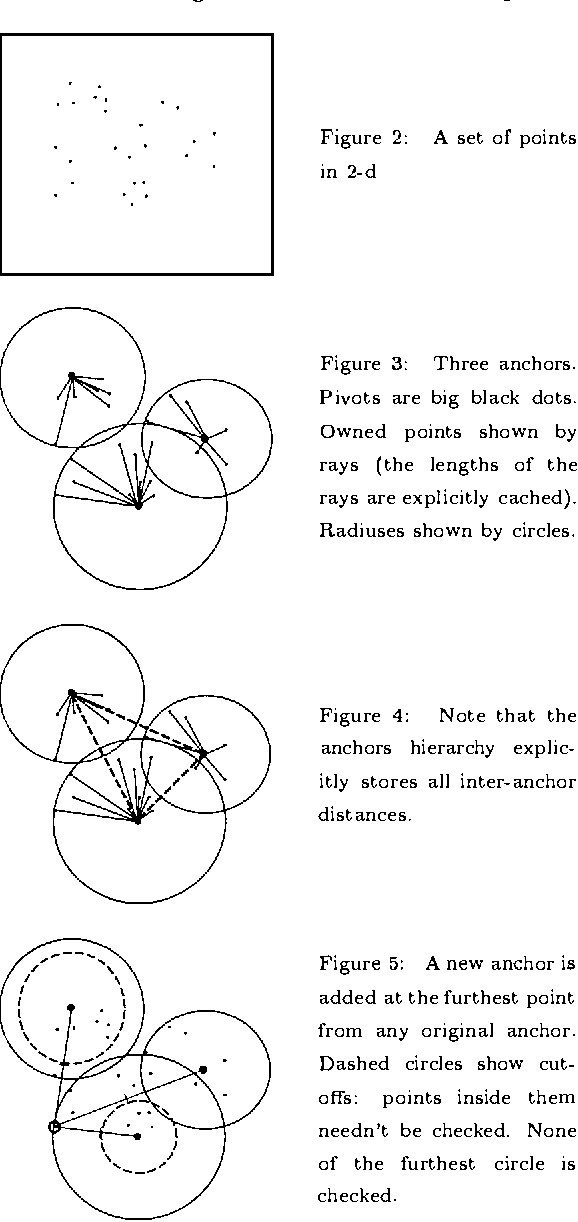
This paper is about metric data structures in high-dimensional or non-Euclidean space that permit cached sufficient statistics accelerations of learning algorithms. It has recently been shown that for less than about 10 dimensions, decorating kd-trees with additional "cached sufficient statistics" such as first and second moments and contingency tables can provide satisfying acceleration for a very wide range of statistical learning tasks such as kernel regression, locally weighted regression, k-means clustering, mixture modeling and Bayes Net learning. In this paper, we begin by defining the anchors hierarchy - a fast data structure and algorithm for localizing data based only on a triangle-inequality-obeying distance metric. We show how this, in its own right, gives a fast and effective clustering of data. But more importantly we show how it can produce a well-balanced structure similar to a Ball-Tree (Omohundro, 1991) or a kind of metric tree (Uhlmann, 1991; Ciaccia, Patella, & Zezula, 1997) in a way that is neither "top-down" nor "bottom-up" but instead "middle-out". We then show how this structure, decorated with cached sufficient statistics, allows a wide variety of statistical learning algorithms to be accelerated even in thousands of dimensions.
Mix-nets: Factored Mixtures of Gaussians in Bayesian Networks With Mixed Continuous And Discrete Variables
Jan 16, 2013
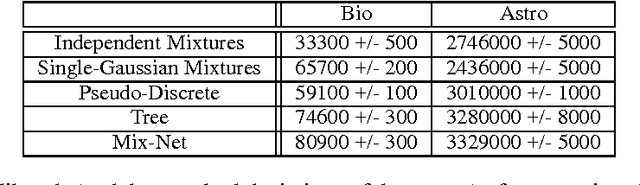
Recently developed techniques have made it possible to quickly learn accurate probability density functions from data in low-dimensional continuous space. In particular, mixtures of Gaussians can be fitted to data very quickly using an accelerated EM algorithm that employs multiresolution kd-trees (Moore, 1999). In this paper, we propose a kind of Bayesian networks in which low-dimensional mixtures of Gaussians over different subsets of the domain's variables are combined into a coherent joint probability model over the entire domain. The network is also capable of modeling complex dependencies between discrete variables and continuous variables without requiring discretization of the continuous variables. We present efficient heuristic algorithms for automatically learning these networks from data, and perform comparative experiments illustrated how well these networks model real scientific data and synthetic data. We also briefly discuss some possible improvements to the networks, as well as possible applications.
Real-valued All-Dimensions search: Low-overhead rapid searching over subsets of attributes
Dec 12, 2012
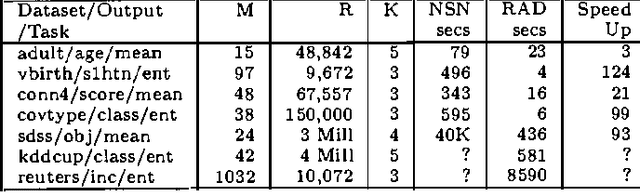
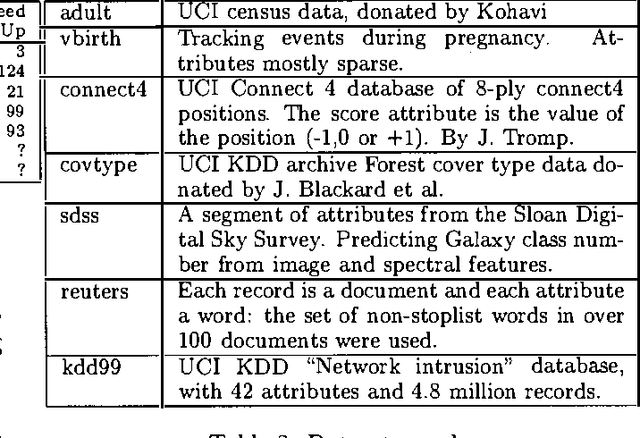
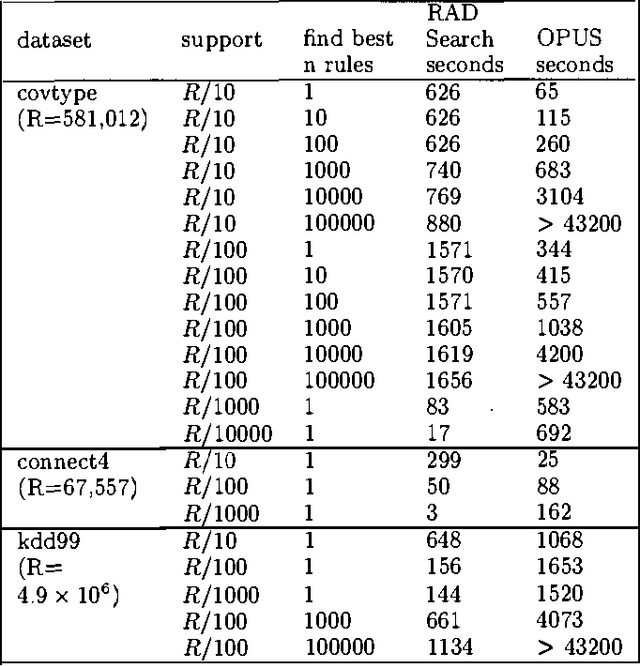
This paper is about searching the combinatorial space of contingency tables during the inner loop of a nonlinear statistical optimization. Examples of this operation in various data analytic communities include searching for nonlinear combinations of attributes that contribute significantly to a regression (Statistics), searching for items to include in a decision list (machine learning) and association rule hunting (Data Mining). This paper investigates a new, efficient approach to this class of problems, called RADSEARCH (Real-valued All-Dimensions-tree Search). RADSEARCH finds the global optimum, and this gives us the opportunity to empirically evaluate the question: apart from algorithmic elegance what does this attention to optimality buy us? We compare RADSEARCH with other recent successful search algorithms such as CN2, PRIM, APriori, OPUS and DenseMiner. Finally, we introduce RADREG, a new regression algorithm for learning real-valued outputs based on RADSEARCHing for high-order interactions.
Interpolating Conditional Density Trees
Dec 12, 2012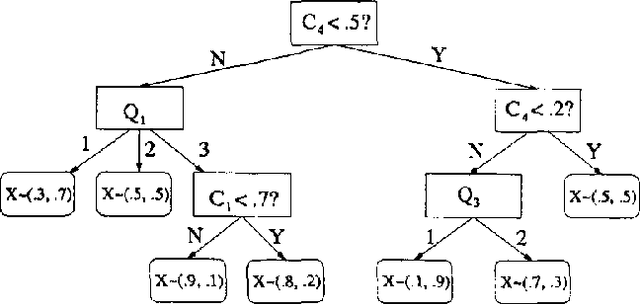
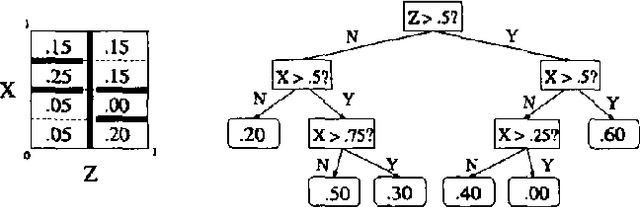
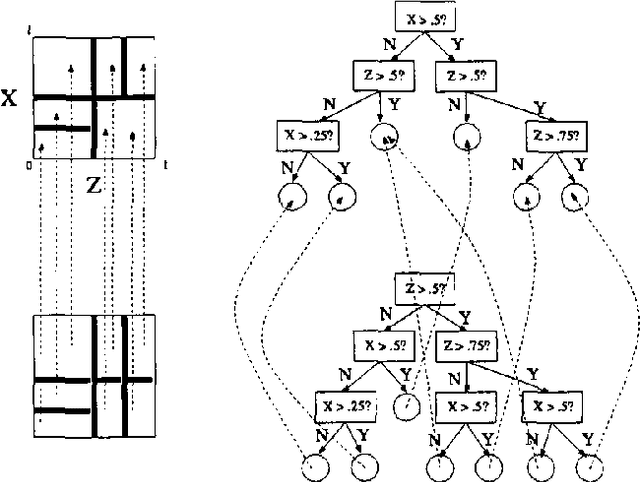
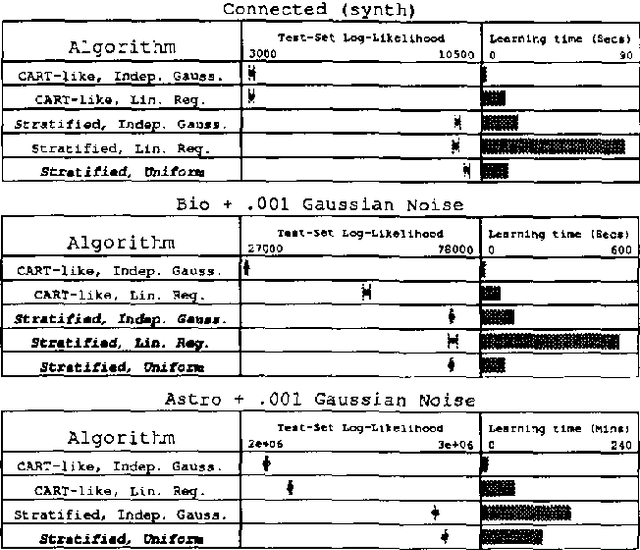
Joint distributions over many variables are frequently modeled by decomposing them into products of simpler, lower-dimensional conditional distributions, such as in sparsely connected Bayesian networks. However, automatically learning such models can be very computationally expensive when there are many datapoints and many continuous variables with complex nonlinear relationships, particularly when no good ways of decomposing the joint distribution are known a priori. In such situations, previous research has generally focused on the use of discretization techniques in which each continuous variable has a single discretization that is used throughout the entire network. \ In this paper, we present and compare a wide variety of tree-based algorithms for learning and evaluating conditional density estimates over continuous variables. These trees can be thought of as discretizations that vary according to the particular interactions being modeled; however, the density within a given leaf of the tree need not be assumed constant, and we show that such nonuniform leaf densities lead to more accurate density estimation. We have developed Bayesian network structure-learning algorithms that employ these tree-based conditional density representations, and we show that they can be used to practically learn complex joint probability models over dozens of continuous variables from thousands of datapoints. We focus on finding models that are simultaneously accurate, fast to learn, and fast to evaluate once they are learned.