 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch for Coverage: Learning Coverage-Aware Retrieval with Augmented Sub-Question Answerability
May 27, 2026Long-form Retrieval-Augmented Generation (RAG) brings the challenge of coverage-based ranking, because ranking methods must ensure the inclusion of comprehensive relevant nuggets (i.e., facts), which can thereby be synthesized into a comprehensive output. In this work, we propose CoveR (Our code is available at https://github.com/DylanJoo/CoveR ) a dense retrieval method optimized for coverage-aware retrieval scenarios. CoveR is a bi-encoder trained with the coverage-based contrastive and distillation objectives, which enables CoveR to capture diverse aspects of information needs. To train CoveR, we create the SCOPE dataset, (Our training data is available at https://huggingface.co/datasets/DylanJHJ/scope ) which comprises 90K training pairs from Researchy Questions with synthetic coverage signals augmented from sub-question answerability judgments generated by LLMs. Our empirical experiments show that CoveR enhances nugget coverage by 10\% over strong dense retrieval baselines without sacrificing its relevance-based retrieval capability. Further ablation studies validate the importance of our proposed learning method, showing that CoveR achieves a superior trade-off between relevance- and coverage-based ranking, which is essential for long-form RAG.
LANCER: LLM Reranking for Nugget Coverage
Jan 29, 2026Unlike short-form retrieval-augmented generation (RAG), such as factoid question answering, long-form RAG requires retrieval to provide documents covering a wide range of relevant information. Automated report generation exemplifies this setting: it requires not only relevant information but also a more elaborate response with comprehensive information. Yet, existing retrieval methods are primarily optimized for relevance ranking rather than information coverage. To address this limitation, we propose LANCER, an LLM-based reranking method for nugget coverage. LANCER predicts what sub-questions should be answered to satisfy an information need, predicts which documents answer these sub-questions, and reranks documents in order to provide a ranked list covering as many information nuggets as possible. Our empirical results show that LANCER enhances the quality of retrieval as measured by nugget coverage metrics, achieving higher $α$-nDCG and information coverage than other LLM-based reranking methods. Our oracle analysis further reveals that sub-question generation plays an essential role.
To Case or Not to Case: An Empirical Study in Learned Sparse Retrieval
Jan 24, 2026Learned Sparse Retrieval (LSR) methods construct sparse lexical representations of queries and documents that can be efficiently searched using inverted indexes. Existing LSR approaches have relied almost exclusively on uncased backbone models, whose vocabularies exclude case-sensitive distinctions, thereby reducing vocabulary mismatch. However, the most recent state-of-the-art language models are only available in cased versions. Despite this shift, the impact of backbone model casing on LSR has not been studied, potentially posing a risk to the viability of the method going forward. To fill this gap, we systematically evaluate paired cased and uncased versions of the same backbone models across multiple datasets to assess their suitability for LSR. Our findings show that LSR models with cased backbone models by default perform substantially worse than their uncased counterparts; however, this gap can be eliminated by pre-processing the text to lowercase. Moreover, our token-level analysis reveals that, under lowercasing, cased models almost entirely suppress cased vocabulary items and behave effectively as uncased models, explaining their restored performance. This result broadens the applicability of recent cased models to the LSR setting and facilitates the integration of stronger backbone architectures into sparse retrieval. The complete code and implementation for this project are available at: https://github.com/lionisakis/Uncased-vs-cased-models-in-LSR
Incorporating Q&A Nuggets into Retrieval-Augmented Generation
Jan 19, 2026RAGE systems integrate ideas from automatic evaluation (E) into Retrieval-augmented Generation (RAG). As one such example, we present Crucible, a Nugget-Augmented Generation System that preserves explicit citation provenance by constructing a bank of Q&A nuggets from retrieved documents and uses them to guide extraction, selection, and report generation. Reasoning on nuggets avoids repeated information through clear and interpretable Q&A semantics - instead of opaque cluster abstractions - while maintaining citation provenance throughout the entire generation process. Evaluated on the TREC NeuCLIR 2024 collection, our Crucible system substantially outperforms Ginger, a recent nugget-based RAG system, in nugget recall, density, and citation grounding.
Milco: Learned Sparse Retrieval Across Languages via a Multilingual Connector
Oct 01, 2025Learned Sparse Retrieval (LSR) combines the efficiency of bi-encoders with the transparency of lexical matching, but existing approaches struggle to scale beyond English. We introduce MILCO, an LSR architecture that maps queries and documents from different languages into a shared English lexical space via a multilingual connector. MILCO is trained with a specialized two-stage regime that combines Sparse Alignment Pretraining with contrastive training to provide representation transparency and effectiveness while mitigating semantic collapse. Motivated by the observation that uncommon entities are often lost when projected into English, we propose a new LexEcho head, which enhances robustness by augmenting the English lexical representation with a source-language view obtained through a special [ECHO] token. MILCO achieves state-of-the-art multilingual and cross-lingual LSR performance, outperforming leading dense, sparse, and multi-vector baselines such as BGE-M3 and Qwen3-Embed on standard multilingual benchmarks, while supporting dynamic efficiency through post-hoc pruning. Notably, when using mass-based pruning to reduce document representations to only 30 active dimensions on average, MILCO 560M outperforms the similarly-sized Qwen3-Embed 0.6B with 1024 dimensions.
SERVAL: Surprisingly Effective Zero-Shot Visual Document Retrieval Powered by Large Vision and Language Models
Sep 18, 2025Visual Document Retrieval (VDR) typically operates as text-to-image retrieval using specialized bi-encoders trained to directly embed document images. We revisit a zero-shot generate-and-encode pipeline: a vision-language model first produces a detailed textual description of each document image, which is then embedded by a standard text encoder. On the ViDoRe-v2 benchmark, the method reaches 63.4% nDCG@5, surpassing the strongest specialised multi-vector visual document encoder. It also scales better to large collections and offers broader multilingual coverage. Analysis shows that modern vision-language models capture complex textual and visual cues with sufficient granularity to act as a reusable semantic proxy. By offloading modality alignment to pretrained vision-language models, our approach removes the need for computationally intensive text-image contrastive training and establishes a strong zero-shot baseline for future VDR systems.
* Accepted
Reproducibility, Replicability, and Insights into Visual Document Retrieval with Late Interaction
May 12, 2025Visual Document Retrieval (VDR) is an emerging research area that focuses on encoding and retrieving document images directly, bypassing the dependence on Optical Character Recognition (OCR) for document search. A recent advance in VDR was introduced by ColPali, which significantly improved retrieval effectiveness through a late interaction mechanism. ColPali's approach demonstrated substantial performance gains over existing baselines that do not use late interaction on an established benchmark. In this study, we investigate the reproducibility and replicability of VDR methods with and without late interaction mechanisms by systematically evaluating their performance across multiple pre-trained vision-language models. Our findings confirm that late interaction yields considerable improvements in retrieval effectiveness; however, it also introduces computational inefficiencies during inference. Additionally, we examine the adaptability of VDR models to textual inputs and assess their robustness across text-intensive datasets within the proposed benchmark, particularly when scaling the indexing mechanism. Furthermore, our research investigates the specific contributions of late interaction by looking into query-patch matching in the context of visual document retrieval. We find that although query tokens cannot explicitly match image patches as in the text retrieval scenario, they tend to match the patch contains visually similar tokens or their surrounding patches.
On the Reproducibility of Learned Sparse Retrieval Adaptations for Long Documents
Mar 31, 2025Document retrieval is one of the most challenging tasks in Information Retrieval. It requires handling longer contexts, often resulting in higher query latency and increased computational overhead. Recently, Learned Sparse Retrieval (LSR) has emerged as a promising approach to address these challenges. Some have proposed adapting the LSR approach to longer documents by aggregating segmented document using different post-hoc methods, including n-grams and proximity scores, adjusting representations, and learning to ensemble all signals. In this study, we aim to reproduce and examine the mechanisms of adapting LSR for long documents. Our reproducibility experiments confirmed the importance of specific segments, with the first segment consistently dominating document retrieval performance. Furthermore, We re-evaluate recently proposed methods -- ExactSDM and SoftSDM -- across varying document lengths, from short (up to 2 segments) to longer (3+ segments). We also designed multiple analyses to probe the reproduced methods and shed light on the impact of global information on adapting LSR to longer contexts. The complete code and implementation for this project is available at: https://github.com/lionisakis/Reproducibilitiy-lsr-long.
* This is a preprint of our paper accepted at ECIR 2025
Improving Conversational Passage Re-ranking with View Ensemble
Apr 26, 2023



This paper presents ConvRerank, a conversational passage re-ranker that employs a newly developed pseudo-labeling approach. Our proposed view-ensemble method enhances the quality of pseudo-labeled data, thus improving the fine-tuning of ConvRerank. Our experimental evaluation on benchmark datasets shows that combining ConvRerank with a conversational dense retriever in a cascaded manner achieves a good balance between effectiveness and efficiency. Compared to baseline methods, our cascaded pipeline demonstrates lower latency and higher top-ranking effectiveness. Furthermore, the in-depth analysis confirms the potential of our approach to improving the effectiveness of conversational search.
Text-to-Text Multi-view Learning for Passage Re-ranking
Apr 29, 2021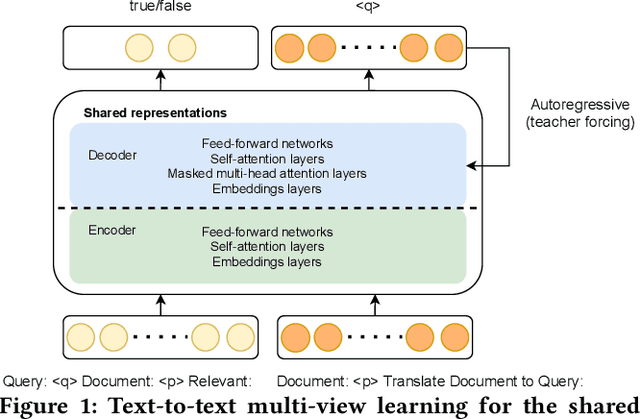
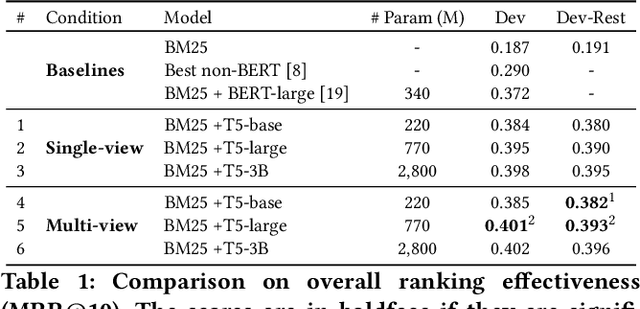
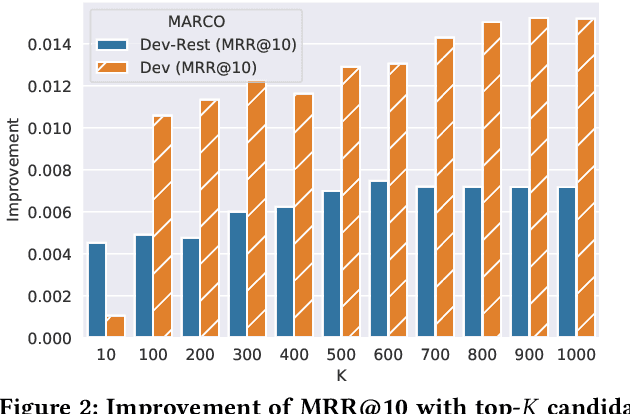
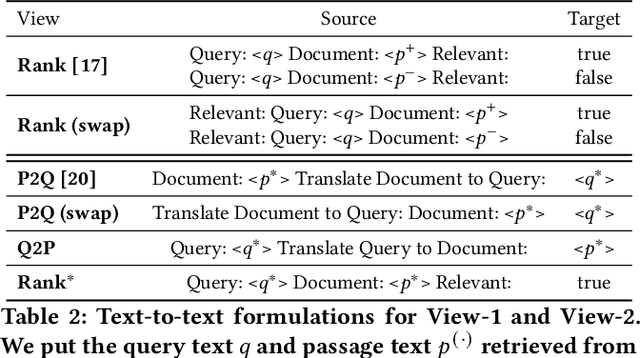
Recently, much progress in natural language processing has been driven by deep contextualized representations pretrained on large corpora. Typically, the fine-tuning on these pretrained models for a specific downstream task is based on single-view learning, which is however inadequate as a sentence can be interpreted differently from different perspectives. Therefore, in this work, we propose a text-to-text multi-view learning framework by incorporating an additional view -- the text generation view -- into a typical single-view passage ranking model. Empirically, the proposed approach is of help to the ranking performance compared to its single-view counterpart. Ablation studies are also reported in the paper.