 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality over Precision: Exploring the Influence of Human-Likeness on ChatGPT Use for Search
Nov 09, 2025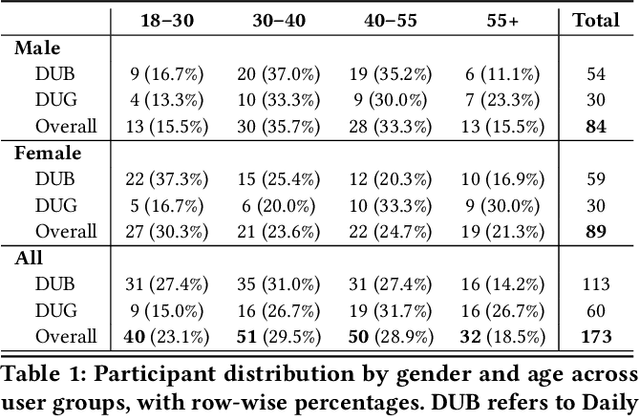
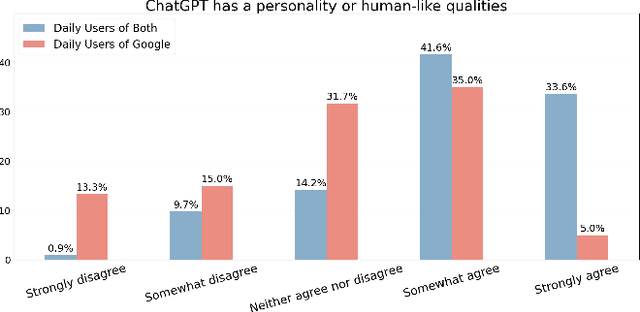
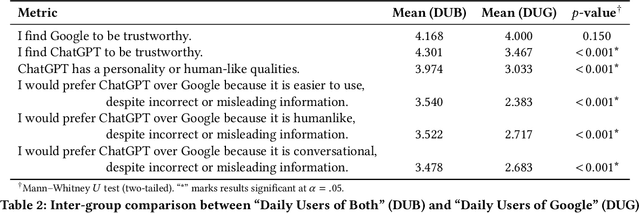
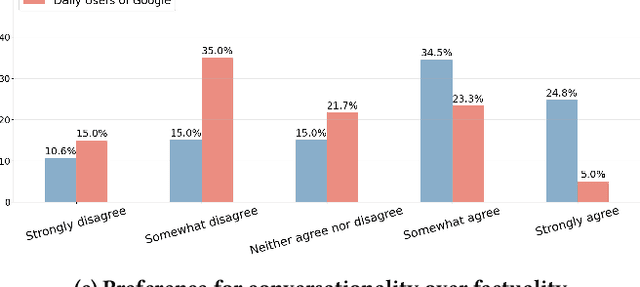
Conversational search interfaces, like ChatGPT, offer an interactive, personalized, and engaging user experience compared to traditional search. On the downside, they are prone to cause overtrust issues where users rely on their responses even when they are incorrect. What aspects of the conversational interaction paradigm drive people to adopt it, and how it creates personalized experiences that lead to overtrust, is not clear. To understand the factors influencing the adoption of conversational interfaces, we conducted a survey with 173 participants. We examined user perceptions regarding trust, human-likeness (anthropomorphism), and design preferences between ChatGPT and Google. To better understand the overtrust phenomenon, we asked users about their willingness to trade off factuality for constructs like ease of use or human-likeness. Our analysis identified two distinct user groups: those who use both ChatGPT and Google daily (DUB), and those who primarily rely on Google (DUG). The DUB group exhibited higher trust in ChatGPT, perceiving it as more human-like, and expressed greater willingness to trade factual accuracy for enhanced personalization and conversational flow. Conversely, the DUG group showed lower trust toward ChatGPT but still appreciated aspects like ad-free experiences and responsive interactions. Demographic analysis further revealed nuanced patterns, with middle-aged adults using ChatGPT less frequently yet trusting it more, suggesting potential vulnerability to misinformation. Our findings contribute to understanding user segmentation, emphasizing the critical roles of personalization and human-likeness in conversational IR systems, and reveal important implications regarding users' willingness to compromise factual accuracy for more engaging interactions.
The Impact of Quantization on Retrieval-Augmented Generation: An Analysis of Small LLMs
Jun 10, 2024



Post-training quantization reduces the computational demand of Large Language Models (LLMs) but can weaken some of their capabilities. Since LLM abilities emerge with scale, smaller LLMs are more sensitive to quantization. In this paper, we explore how quantization affects smaller LLMs' ability to perform retrieval-augmented generation (RAG), specifically in longer contexts. We chose personalization for evaluation because it is a challenging domain to perform using RAG as it requires long-context reasoning over multiple documents. We compare the original FP16 and the quantized INT4 performance of multiple 7B and 8B LLMs on two tasks while progressively increasing the number of retrieved documents to test how quantized models fare against longer contexts. To better understand the effect of retrieval, we evaluate three retrieval models in our experiments. Our findings reveal that if a 7B LLM performs the task well, quantization does not impair its performance and long-context reasoning capabilities. We conclude that it is possible to utilize RAG with quantized smaller LLMs.