 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSRN: an Efficient Deep Network for Image Relighting
Feb 18, 2021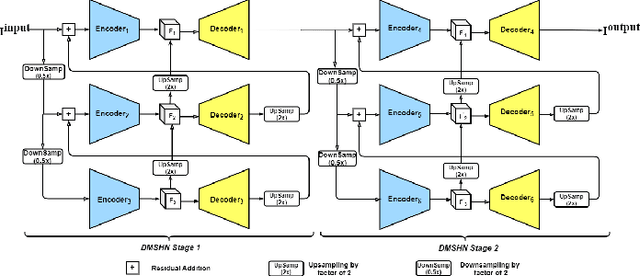
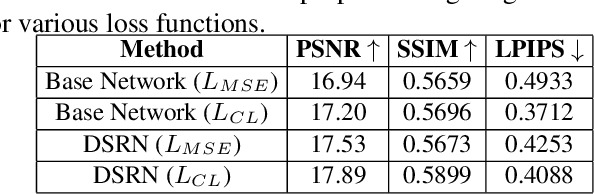
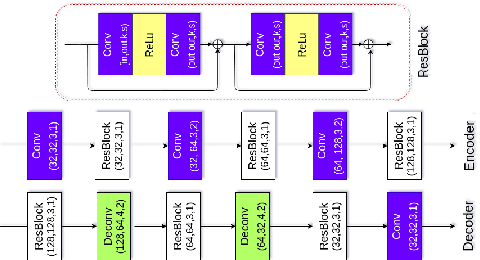
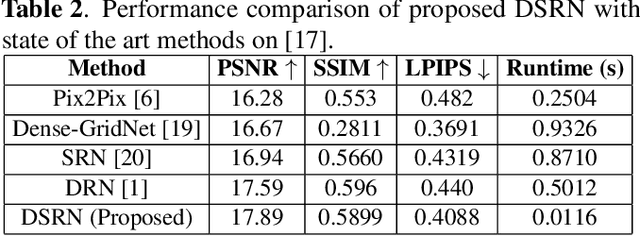
Custom and natural lighting conditions can be emulated in images of the scene during post-editing. Extraordinary capabilities of the deep learning framework can be utilized for such purpose. Deep image relighting allows automatic photo enhancement by illumination-specific retouching. Most of the state-of-the-art methods for relighting are run-time intensive and memory inefficient. In this paper, we propose an efficient, real-time framework Deep Stacked Relighting Network (DSRN) for image relighting by utilizing the aggregated features from input image at different scales. Our model is very lightweight with total size of about 42 MB and has an average inference time of about 0.0116s for image of resolution $1024 \times 1024$ which is faster as compared to other multi-scale models. Our solution is quite robust for translating image color temperature from input image to target image and also performs moderately for light gradient generation with respect to the target image. Additionally, we show that if images illuminated from opposite directions are used as input, the qualitative results improve over using a single input image.
A Heuristic-driven Ensemble Framework for COVID-19 Fake News Detection
Jan 10, 2021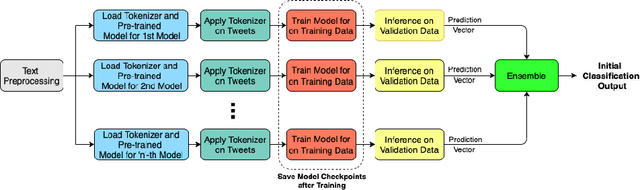
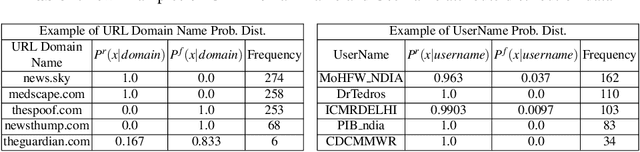
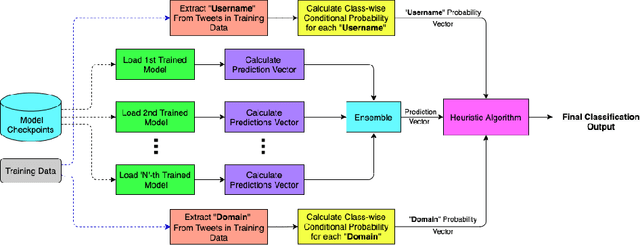
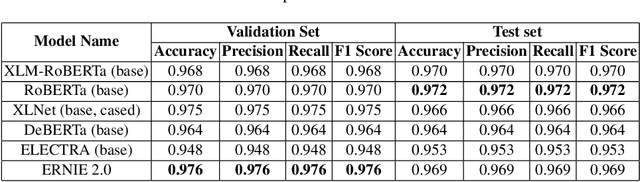
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world stay connected. With the COVID-19 pandemic raging, social media has become more relevant and widely used than ever before, and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe our Fake News Detection system that automatically identifies whether a tweet related to COVID-19 is "real" or "fake", as a part of CONSTRAINT COVID19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models that has helped us achieve a joint 8th position on the leader board. We have achieved an F1-score of 0.9831 against a top score of 0.9869. Post completion of the competition, we have been able to drastically improve our system by incorporating a novel heuristic algorithm based on username handles and link domains in tweets fetching an F1-score of 0.9883 and achieving state-of-the art results on the given dataset.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020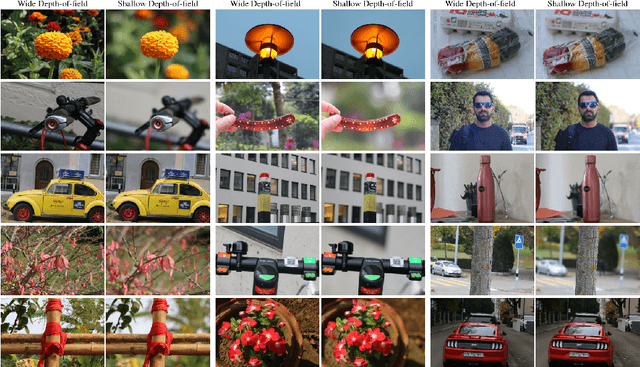


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020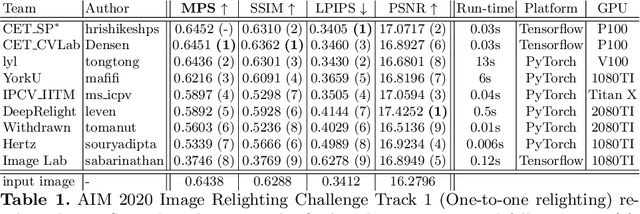

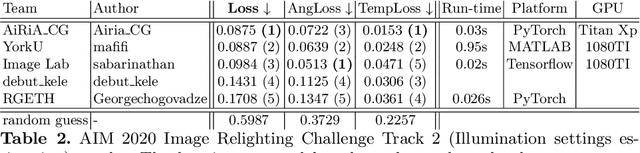

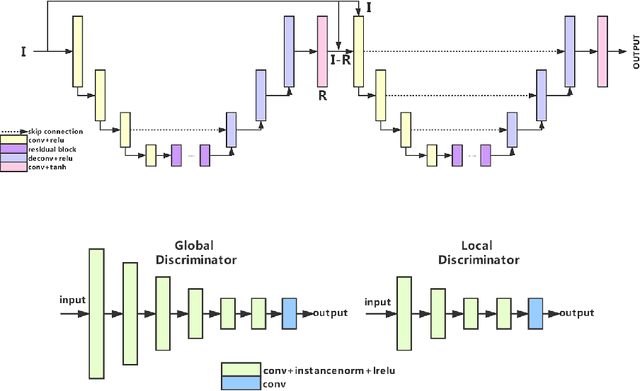
We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
Semantic Segmentation of Surface from Lidar Point Cloud
Sep 13, 2020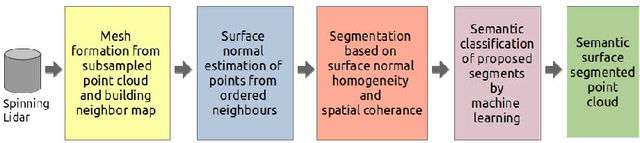
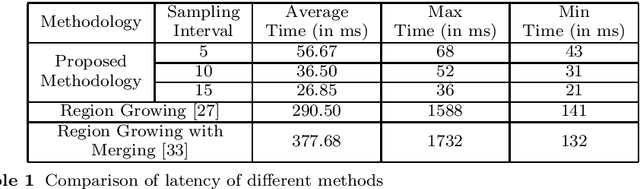
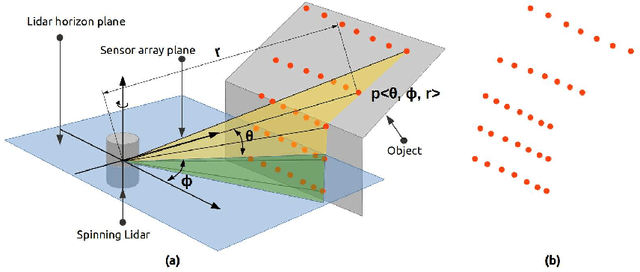
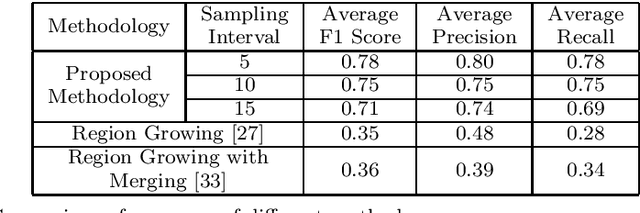
In the field of SLAM (Simultaneous Localization And Mapping) for robot navigation, mapping the environment is an important task. In this regard the Lidar sensor can produce near accurate 3D map of the environment in the format of point cloud, in real time. Though the data is adequate for extracting information related to SLAM, processing millions of points in the point cloud is computationally quite expensive. The methodology presented proposes a fast algorithm that can be used to extract semantically labelled surface segments from the cloud, in real time, for direct navigational use or higher level contextual scene reconstruction. First, a single scan from a spinning Lidar is used to generate a mesh of subsampled cloud points online. The generated mesh is further used for surface normal computation of those points on the basis of which surface segments are estimated. A novel descriptor to represent the surface segments is proposed and utilized to determine the surface class of the segments (semantic label) with the help of classifier. These semantic surface segments can be further utilized for geometric reconstruction of objects in the scene, or can be used for optimized trajectory planning by a robot. The proposed methodology is compared with number of point cloud segmentation methods and state of the art semantic segmentation methods to emphasize its efficacy in terms of speed and accuracy.
Team Neuro at SemEval-2020 Task 8: Multi-Modal Fine Grain Emotion Classification of Memes using Multitask Learning
May 21, 2020
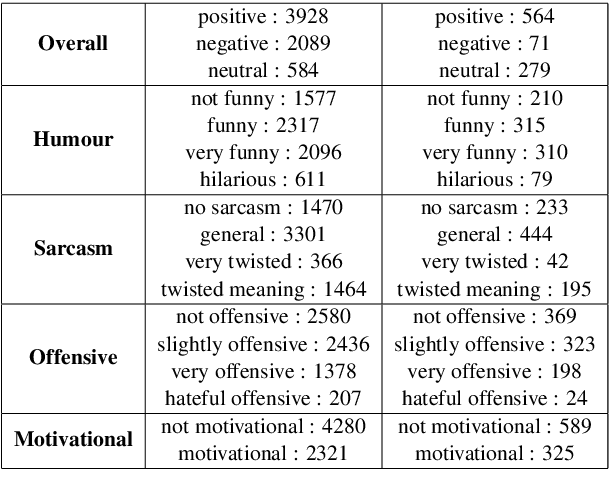
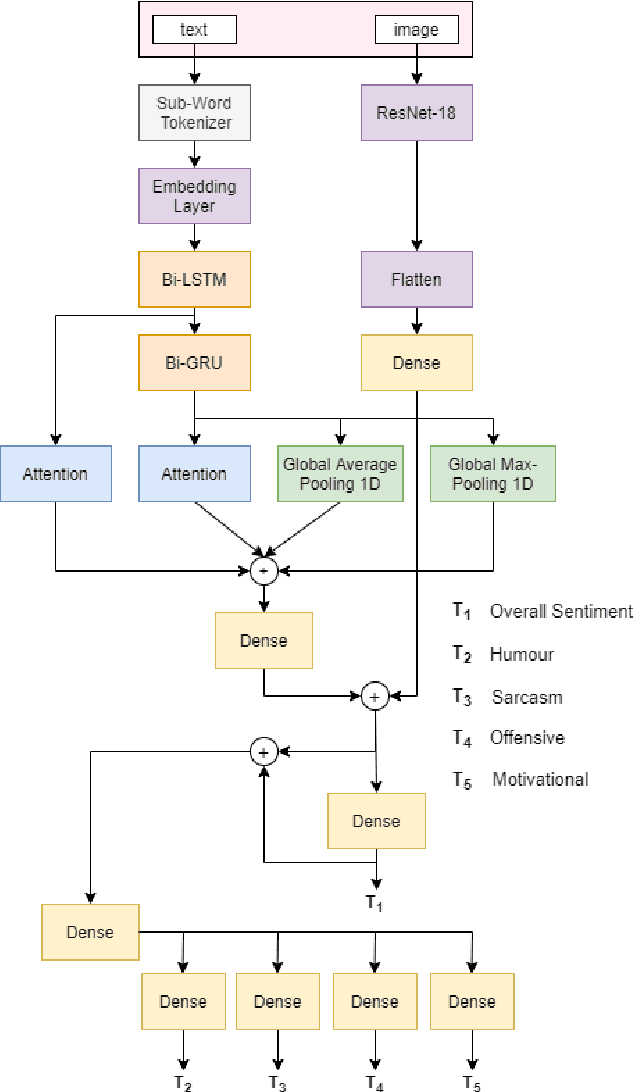
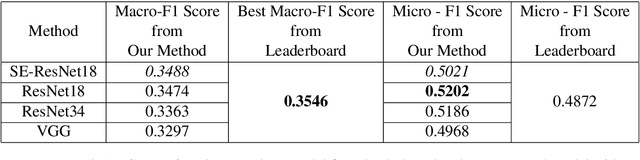
In this article, we describe the system that we used for the memotion analysis challenge, which is Task 8 of SemEval-2020. This challenge had three subtasks where affect based sentiment classification of the memes was required along with intensities. The system we proposed combines the three tasks into a single one by representing it as multi-label hierarchical classification problem.Here,Multi-Task learning or Joint learning Procedure is used to train our model.We have used dual channels to extract text and image based features from separate Deep Neural Network Backbone and aggregate them to create task specific features. These task specific aggregated feature vectors ware then passed on to smaller networks with dense layers, each one assigned for predicting one type of fine grain sentiment label. Our Proposed method show the superiority of this system in few tasks to other best models from the challenge.
Fast Deep Multi-patch Hierarchical Network for Nonhomogeneous Image Dehazing
May 12, 2020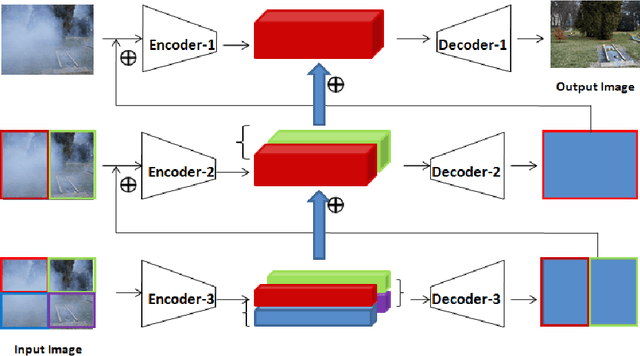
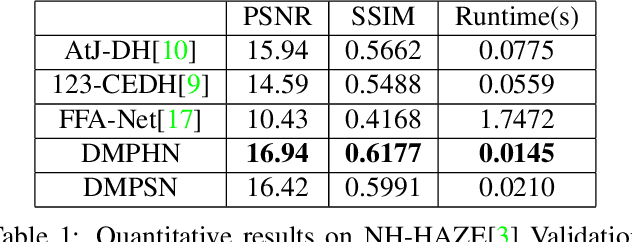
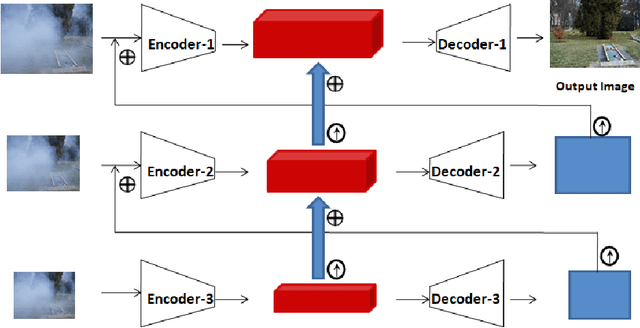
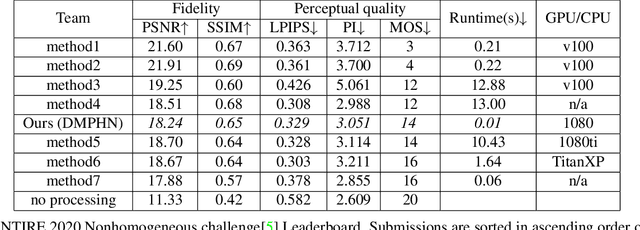
Recently, CNN based end-to-end deep learning methods achieve superiority in Image Dehazing but they tend to fail drastically in Non-homogeneous dehazing. Apart from that, existing popular Multi-scale approaches are runtime intensive and memory inefficient. In this context, we proposed a fast Deep Multi-patch Hierarchical Network to restore Non-homogeneous hazed images by aggregating features from multiple image patches from different spatial sections of the hazed image with fewer number of network parameters. Our proposed method is quite robust for different environments with various density of the haze or fog in the scene and very lightweight as the total size of the model is around 21.7 MB. It also provides faster runtime compared to current multi-scale methods with an average runtime of 0.0145s to process 1200x1600 HD quality image. Finally, we show the superiority of this network on Dense Haze Removal to other state-of-the-art models.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
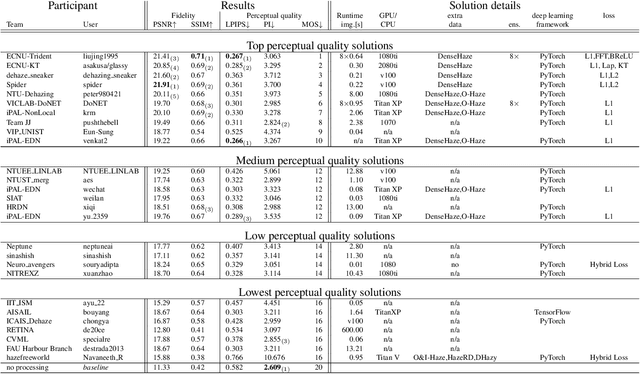
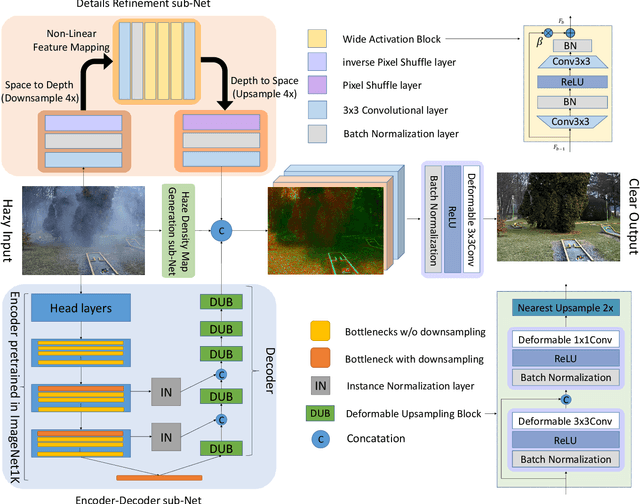
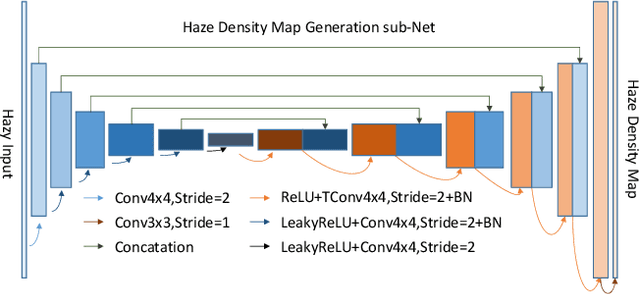
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.
Fast Geometric Surface based Segmentation of Point Cloud from Lidar Data
May 06, 2020
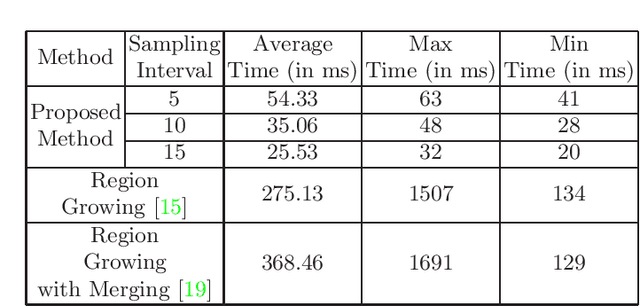
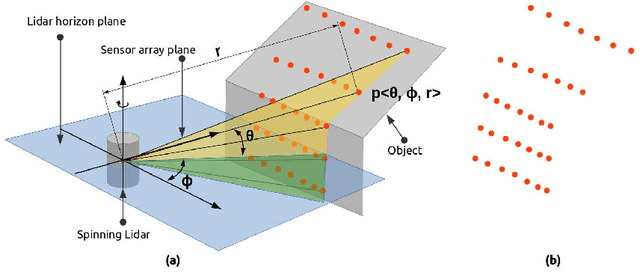
Mapping the environment has been an important task for robot navigation and Simultaneous Localization And Mapping (SLAM). LIDAR provides a fast and accurate 3D point cloud map of the environment which helps in map building. However, processing millions of points in the point cloud becomes a computationally expensive task. In this paper, a methodology is presented to generate the segmented surfaces in real time and these can be used in modeling the 3D objects. At first an algorithm is proposed for efficient map building from single shot data of spinning Lidar. It is based on fast meshing and sub-sampling. It exploits the physical design and the working principle of the spinning Lidar sensor. The generated mesh surfaces are then segmented by estimating the normal and considering their homogeneity. The segmented surfaces can be used as proposals for predicting geometrically accurate model of objects in the robots activity environment. The proposed methodology is compared with some popular point cloud segmentation methods to highlight the efficacy in terms of accuracy and speed.
* Accepted to PReMI 2019( Pattern Recognition and Machine Intelligence 2019 )
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019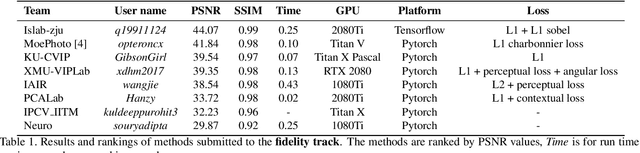
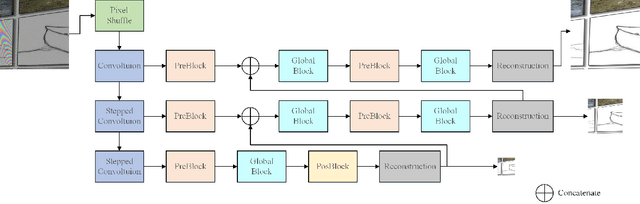
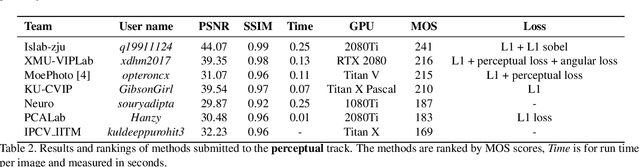
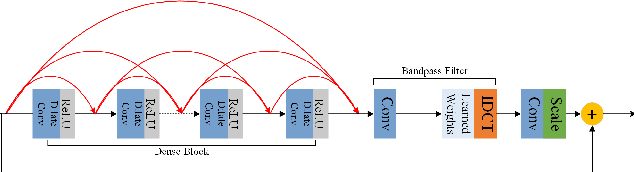
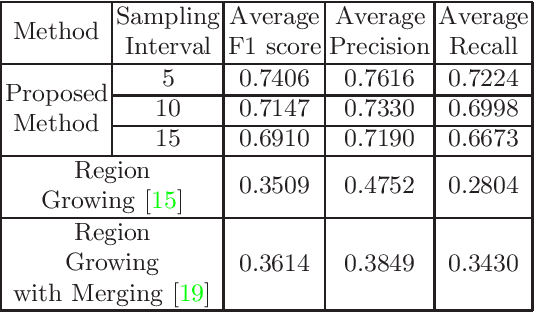
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.