 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolo-Dex: Teaching Dexterity with Immersive Mixed Reality
Oct 12, 2022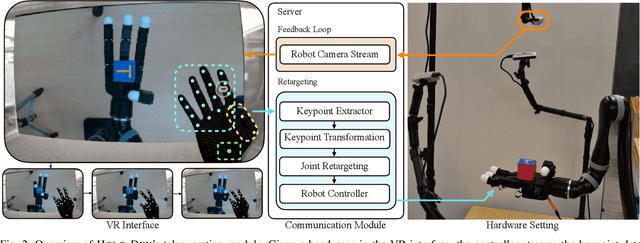



A fundamental challenge in teaching robots is to provide an effective interface for human teachers to demonstrate useful skills to a robot. This challenge is exacerbated in dexterous manipulation, where teaching high-dimensional, contact-rich behaviors often require esoteric teleoperation tools. In this work, we present Holo-Dex, a framework for dexterous manipulation that places a teacher in an immersive mixed reality through commodity VR headsets. The high-fidelity hand pose estimator onboard the headset is used to teleoperate the robot and collect demonstrations for a variety of general-purpose dexterous tasks. Given these demonstrations, we use powerful feature learning combined with non-parametric imitation to train dexterous skills. Our experiments on six common dexterous tasks, including in-hand rotation, spinning, and bottle opening, indicate that Holo-Dex can both collect high-quality demonstration data and train skills in a matter of hours. Finally, we find that our trained skills can exhibit generalization on objects not seen in training. Videos of Holo-Dex are available at https://holo-dex.github.io.
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
Oct 11, 2022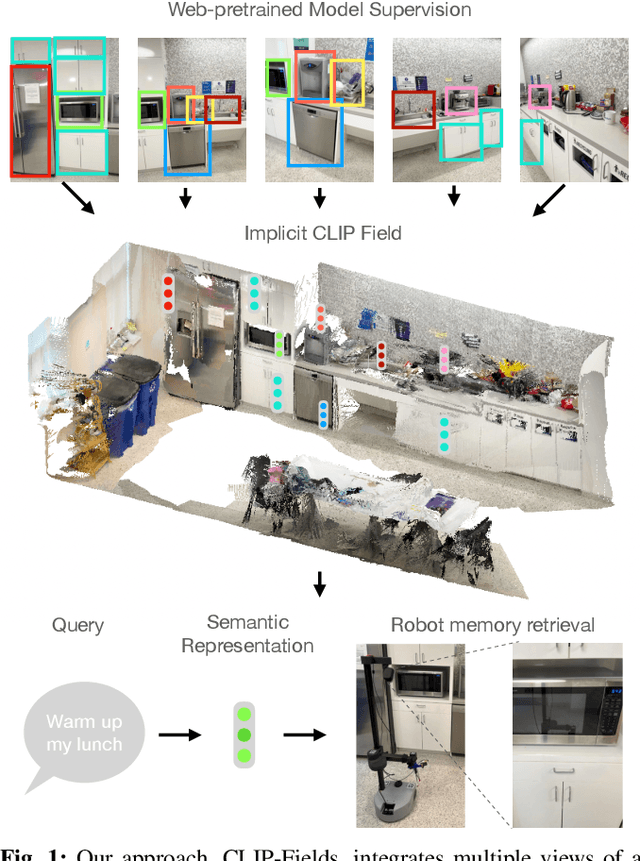
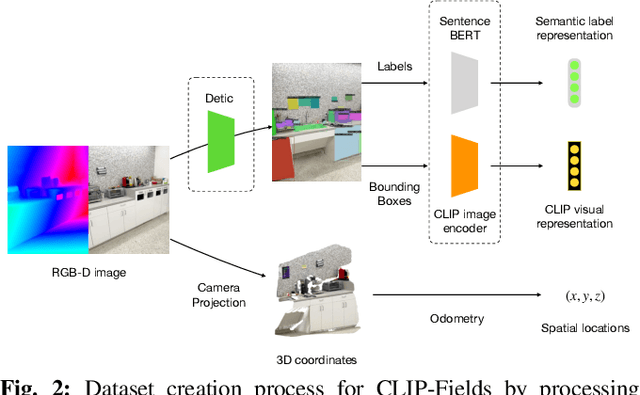
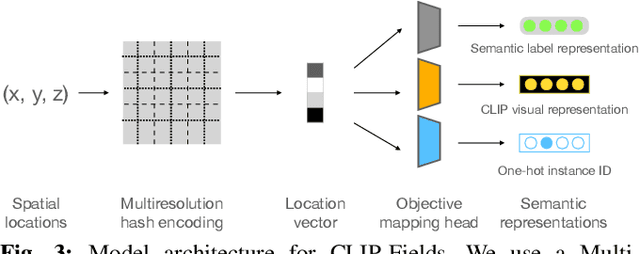
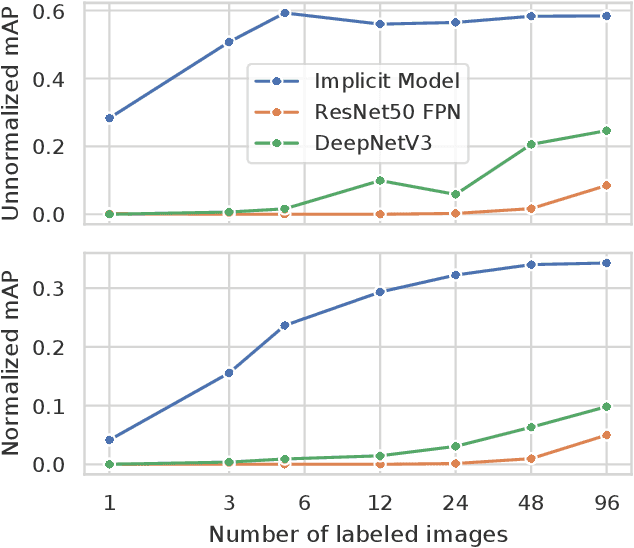
We propose CLIP-Fields, an implicit scene model that can be trained with no direct human supervision. This model learns a mapping from spatial locations to semantic embedding vectors. The mapping can then be used for a variety of tasks, such as segmentation, instance identification, semantic search over space, and view localization. Most importantly, the mapping can be trained with supervision coming only from web-image and web-text trained models such as CLIP, Detic, and Sentence-BERT. When compared to baselines like Mask-RCNN, our method outperforms on few-shot instance identification or semantic segmentation on the HM3D dataset with only a fraction of the examples. Finally, we show that using CLIP-Fields as a scene memory, robots can perform semantic navigation in real-world environments. Our code and demonstrations are available here: https://mahis.life/clip-fields/
TorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021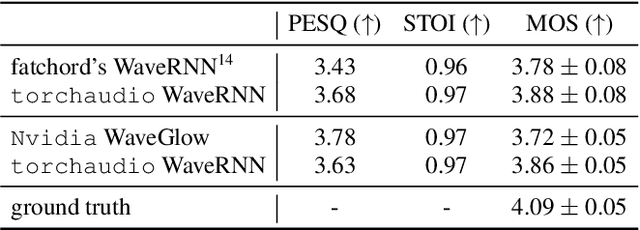
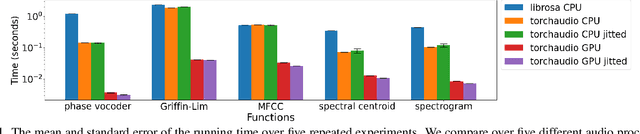


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.
droidlet: modular, heterogenous, multi-modal agents
Jan 25, 2021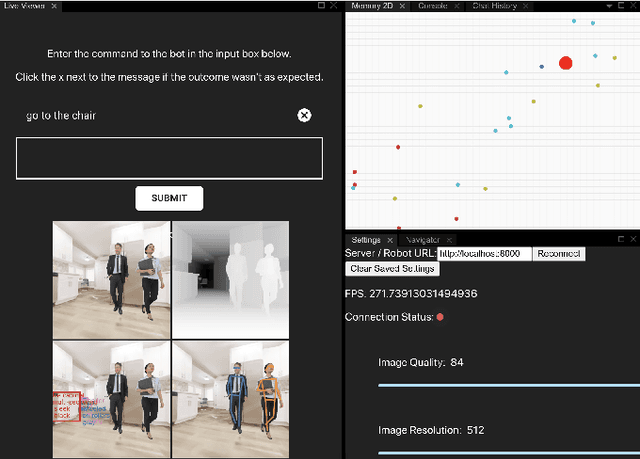
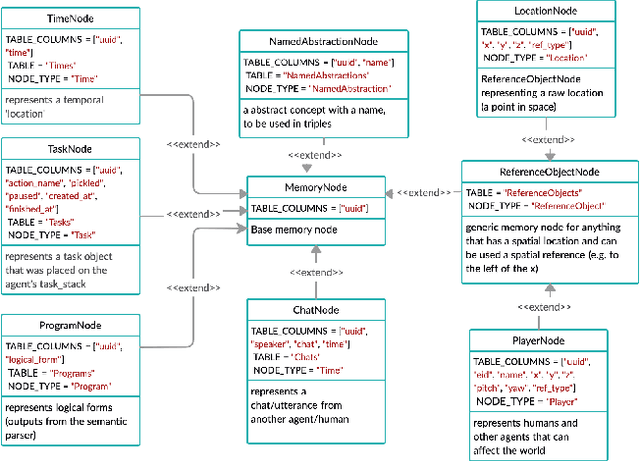
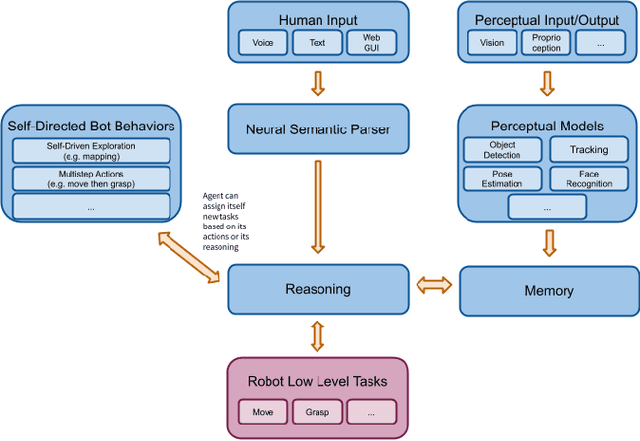
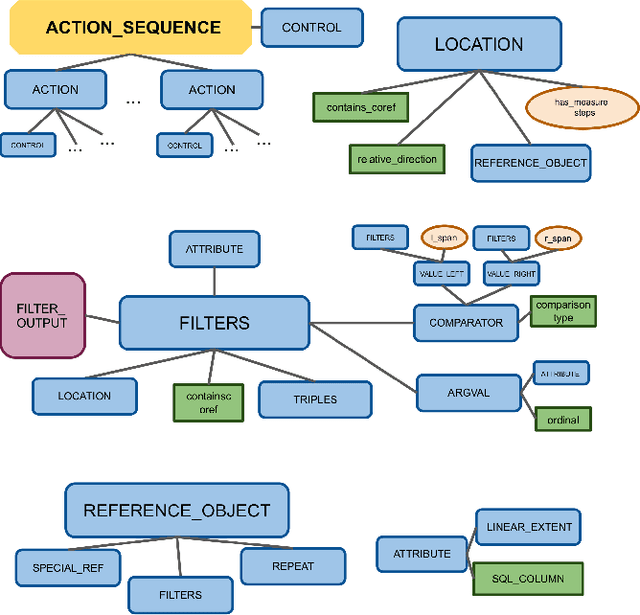
In recent years, there have been significant advances in building end-to-end Machine Learning (ML) systems that learn at scale. But most of these systems are: (a) isolated (perception, speech, or language only); (b) trained on static datasets. On the other hand, in the field of robotics, large-scale learning has always been difficult. Supervision is hard to gather and real world physical interactions are expensive. In this work we introduce and open-source droidlet, a modular, heterogeneous agent architecture and platform. It allows us to exploit both large-scale static datasets in perception and language and sophisticated heuristics often used in robotics; and provides tools for interactive annotation. Furthermore, it brings together perception, language and action onto one platform, providing a path towards agents that learn from the richness of real world interactions.
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Jun 28, 2020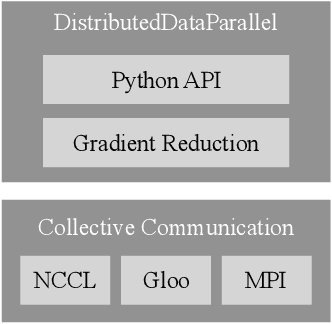
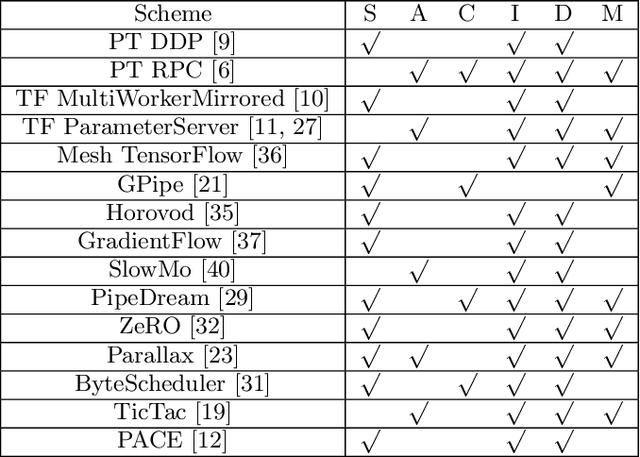
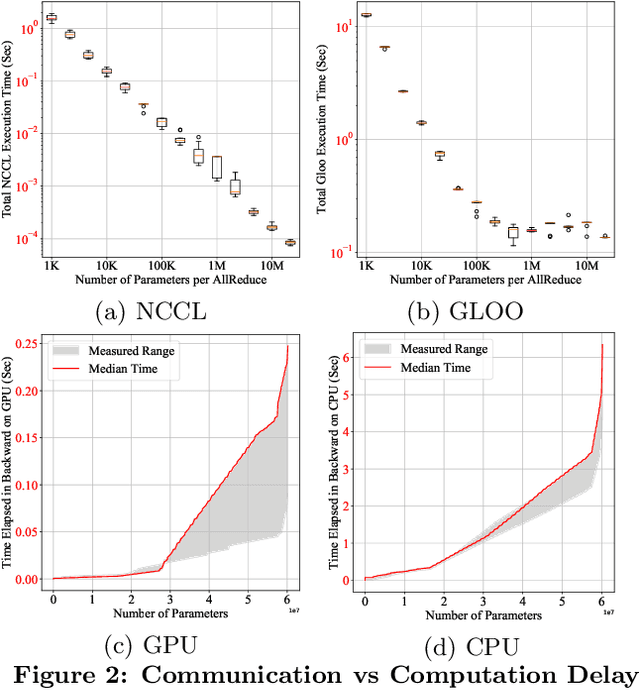
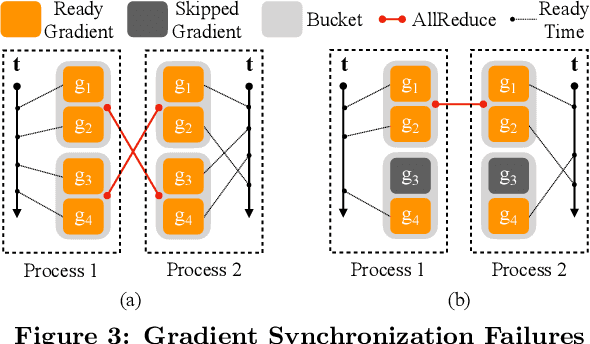
This paper presents the design, implementation, and evaluation of the PyTorch distributed data parallel module. PyTorch is a widely-adopted scientific computing package used in deep learning research and applications. Recent advances in deep learning argue for the value of large datasets and large models, which necessitates the ability to scale out model training to more computational resources. Data parallelism has emerged as a popular solution for distributed training thanks to its straightforward principle and broad applicability. In general, the technique of distributed data parallelism replicates the model on every computational resource to generate gradients independently and then communicates those gradients at each iteration to keep model replicas consistent. Despite the conceptual simplicity of the technique, the subtle dependencies between computation and communication make it non-trivial to optimize the distributed training efficiency. As of v1.5, PyTorch natively provides several techniques to accelerate distributed data parallel, including bucketing gradients, overlapping computation with communication, and skipping gradient synchronization. Evaluations show that, when configured appropriately, the PyTorch distributed data parallel module attains near-linear scalability using 256 GPUs.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019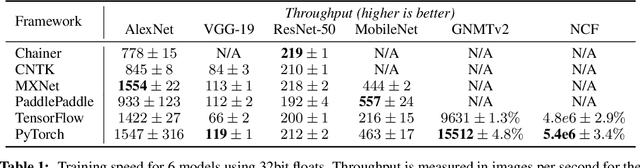

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
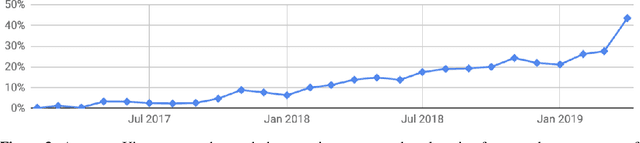
Generalized Inner Loop Meta-Learning
Oct 07, 2019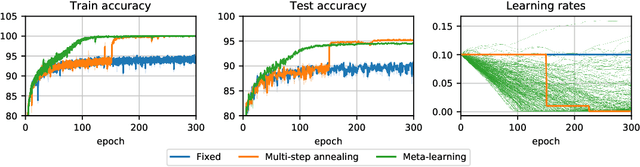

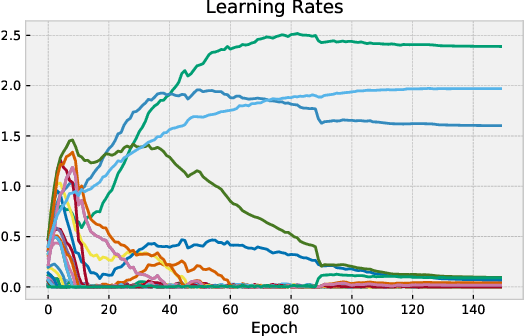
Many (but not all) approaches self-qualifying as "meta-learning" in deep learning and reinforcement learning fit a common pattern of approximating the solution to a nested optimization problem. In this paper, we give a formalization of this shared pattern, which we call GIMLI, prove its general requirements, and derive a general-purpose algorithm for implementing similar approaches. Based on this analysis and algorithm, we describe a library of our design, higher, which we share with the community to assist and enable future research into these kinds of meta-learning approaches. We end the paper by showcasing the practical applications of this framework and library through illustrative experiments and ablation studies which they facilitate.
Wasserstein GAN
Dec 06, 2017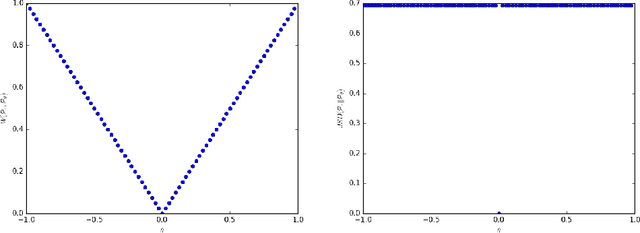
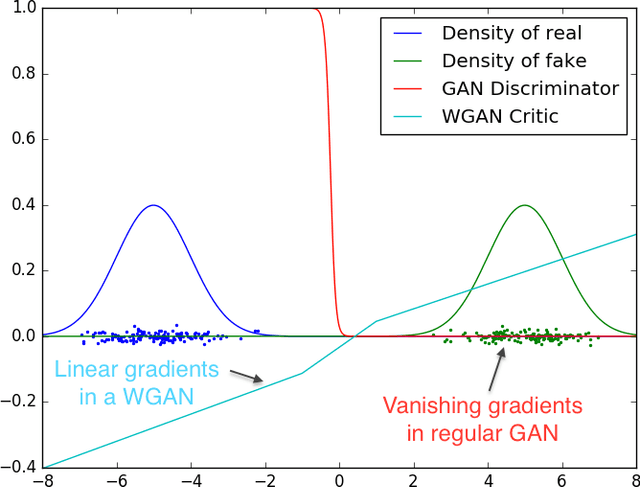
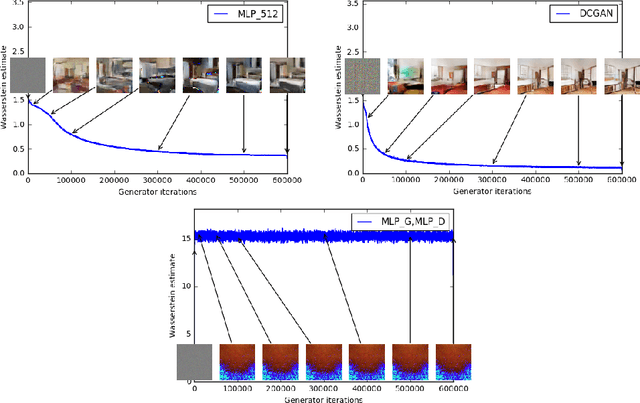
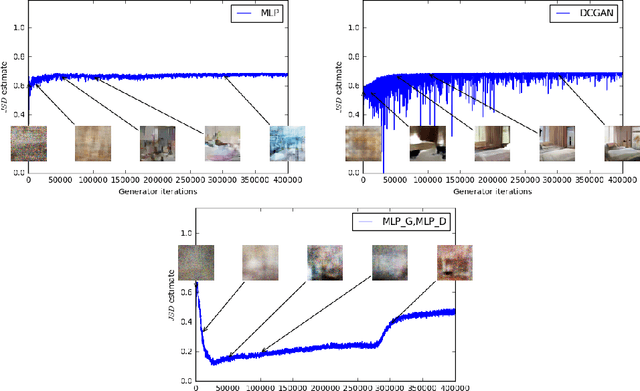
We introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and provide meaningful learning curves useful for debugging and hyperparameter searches. Furthermore, we show that the corresponding optimization problem is sound, and provide extensive theoretical work highlighting the deep connections to other distances between distributions.
Discovering Causal Signals in Images
Oct 31, 2017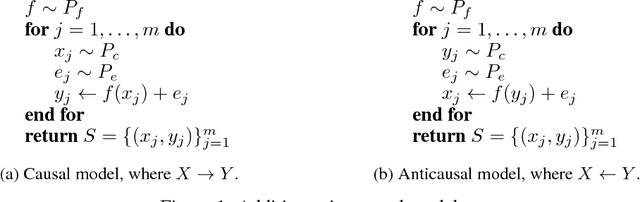
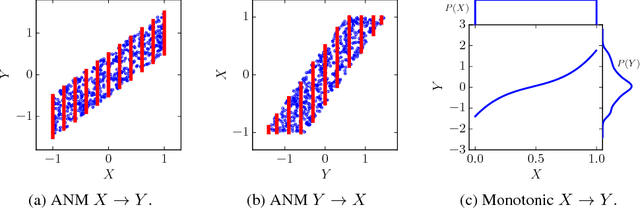
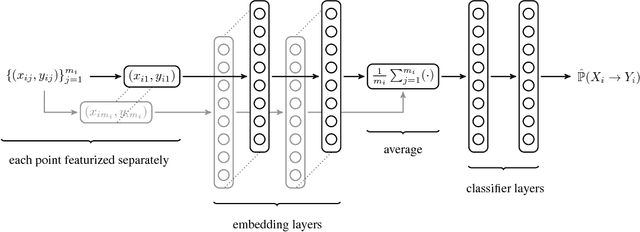

This paper establishes the existence of observable footprints that reveal the "causal dispositions" of the object categories appearing in collections of images. We achieve this goal in two steps. First, we take a learning approach to observational causal discovery, and build a classifier that achieves state-of-the-art performance on finding the causal direction between pairs of random variables, given samples from their joint distribution. Second, we use our causal direction classifier to effectively distinguish between features of objects and features of their contexts in collections of static images. Our experiments demonstrate the existence of a relation between the direction of causality and the difference between objects and their contexts, and by the same token, the existence of observable signals that reveal the causal dispositions of objects.
Transformation-Based Models of Video Sequences
Apr 24, 2017

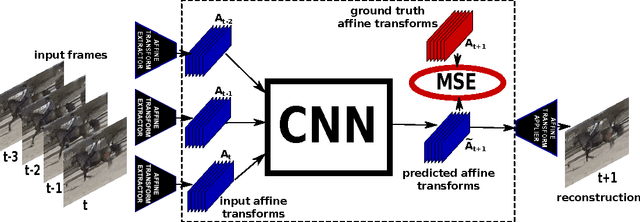
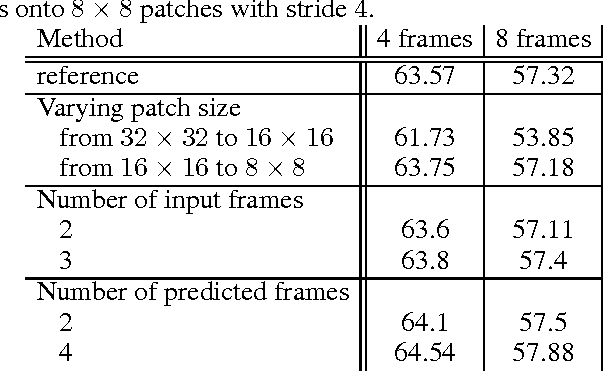
In this work we propose a simple unsupervised approach for next frame prediction in video. Instead of directly predicting the pixels in a frame given past frames, we predict the transformations needed for generating the next frame in a sequence, given the transformations of the past frames. This leads to sharper results, while using a smaller prediction model. In order to enable a fair comparison between different video frame prediction models, we also propose a new evaluation protocol. We use generated frames as input to a classifier trained with ground truth sequences. This criterion guarantees that models scoring high are those producing sequences which preserve discrim- inative features, as opposed to merely penalizing any deviation, plausible or not, from the ground truth. Our proposed approach compares favourably against more sophisticated ones on the UCF-101 data set, while also being more efficient in terms of the number of parameters and computational cost.