 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards
May 30, 2025



We introduce Reasoning Gym (RG), a library of reasoning environments for reinforcement learning with verifiable rewards. It provides over 100 data generators and verifiers spanning multiple domains including algebra, arithmetic, computation, cognition, geometry, graph theory, logic, and various common games. Its key innovation is the ability to generate virtually infinite training data with adjustable complexity, unlike most previous reasoning datasets, which are typically fixed. This procedural generation approach allows for continuous evaluation across varying difficulty levels. Our experimental results demonstrate the efficacy of RG in both evaluating and reinforcement learning of reasoning models.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023



Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
Apr 14, 2023



Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees, in 35 different languages, annotated with 461,292 quality ratings. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. To demonstrate the OpenAssistant Conversations dataset's effectiveness, we present OpenAssistant, the first fully open-source large-scale instruction-tuned model to be trained on human data. A preference study revealed that OpenAssistant replies are comparably preferred to GPT-3.5-turbo (ChatGPT) with a relative winrate of 48.3% vs. 51.7% respectively. We release our code and data under fully permissive licenses.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019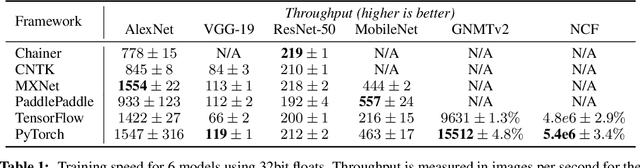

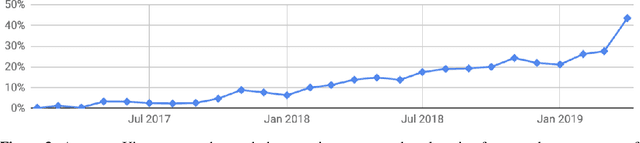
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.