 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersaGNN: a Versatile accelerator for Graph neural networks
May 04, 2021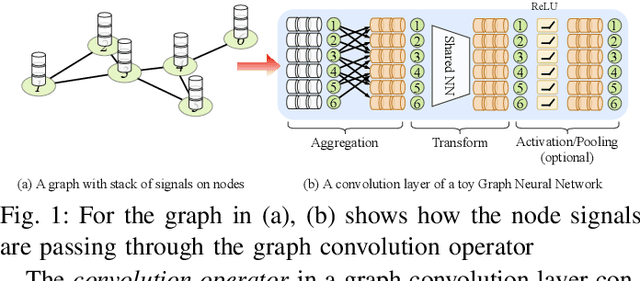
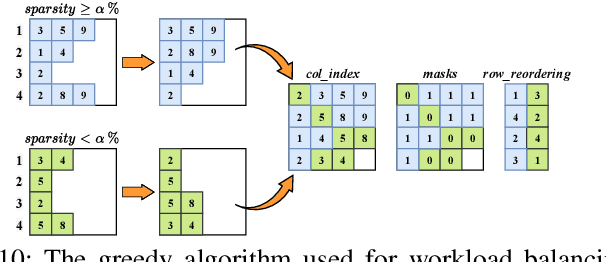
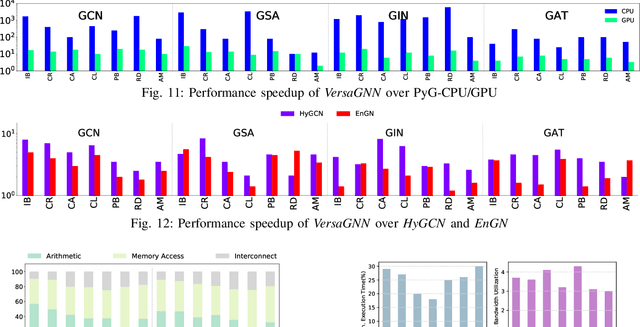
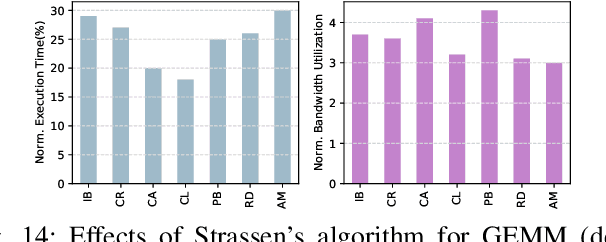
\textit{Graph Neural Network} (GNN) is a promising approach for analyzing graph-structured data that tactfully captures their dependency information via node-level message passing. It has achieved state-of-the-art performances in many tasks, such as node classification, graph matching, clustering, and graph generation. As GNNs operate on non-Euclidean data, their irregular data access patterns cause considerable computational costs and overhead on conventional architectures, such as GPU and CPU. Our analysis shows that GNN adopts a hybrid computing model. The \textit{Aggregation} (or \textit{Message Passing}) phase performs vector additions where vectors are fetched with irregular strides. The \textit{Transformation} (or \textit{Node Embedding}) phase can be either dense or sparse-dense matrix multiplication. In this work, We propose \textit{VersaGNN}, an ultra-efficient, systolic-array-based versatile hardware accelerator that unifies dense and sparse matrix multiplication. By applying this single optimized systolic array to both aggregation and transformation phases, we have significantly reduced chip sizes and energy consumption. We then divide the computing engine into blocked systolic arrays to support the \textit{Strassen}'s algorithm for dense matrix multiplication, dramatically scaling down the number of multiplications and enabling high-throughput computation of GNNs. To balance the workload of sparse-dense matrix multiplication, we also introduced a greedy algorithm to combine sparse sub-matrices of compressed format into condensed ones to reduce computational cycles. Compared with current state-of-the-art GNN software frameworks, \textit{VersaGNN} achieves on average 3712$\times$ speedup with 1301.25$\times$ energy reduction on CPU, and 35.4$\times$ speedup with 17.66$\times$ energy reduction on GPU.
Synthesizing Diverse and Physically Stable Grasps with Arbitrary Hand Structures by Differentiable Force Closure Estimation
Apr 19, 2021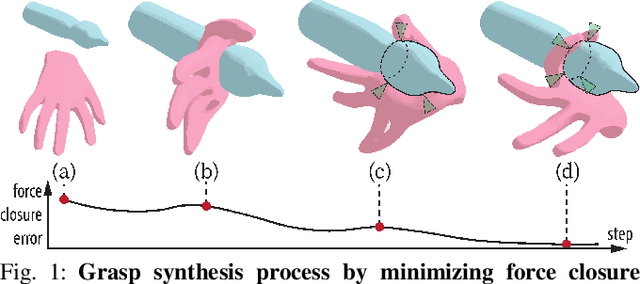

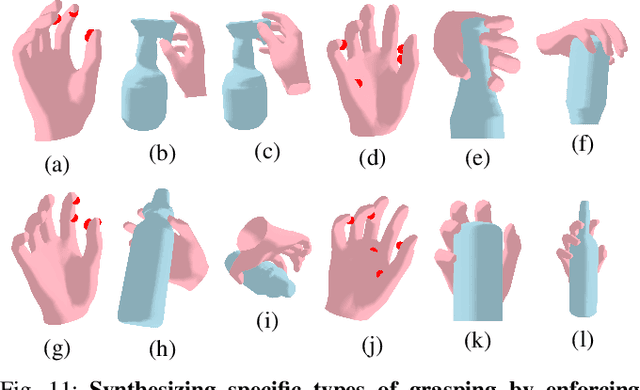
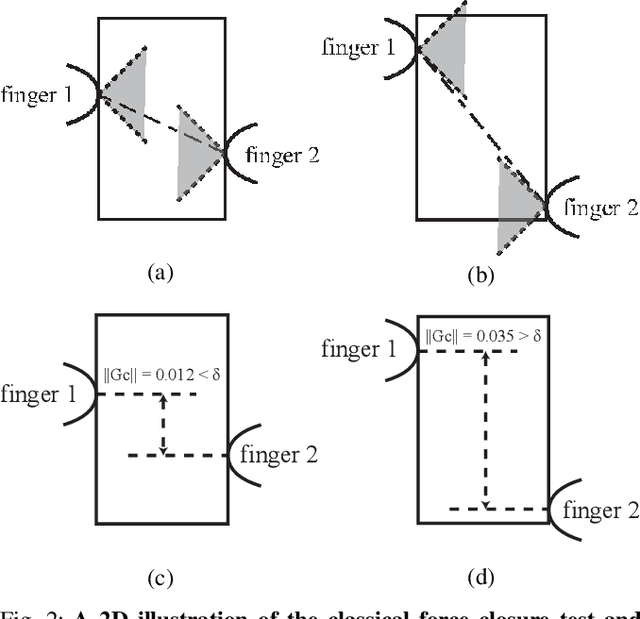
Existing grasp synthesis methods are either analytical or data-driven. The former one is oftentimes limited to specific application scope. The latter one depends heavily on demonstrations, thus suffers from generalization issues; e.g., models trained with human grasp data would be difficult to transfer to 3-finger grippers. To tackle these deficiencies, we formulate a fast and differentiable force closure estimation method, capable of producing diverse and physically stable grasps with arbitrary hand structures, without any training data. Although force closure has commonly served as a measure of grasp quality, it has not been widely adopted as an optimization objective for grasp synthesis primarily due to its high computational complexity; in comparison, the proposed differentiable method can test a force closure within 4ms. In experiments, we validate the proposed method's efficacy in 8 different settings.
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 15, 2021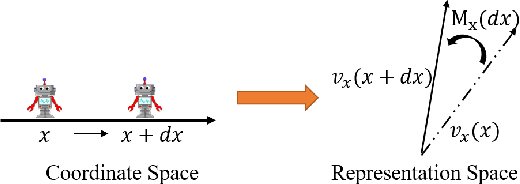
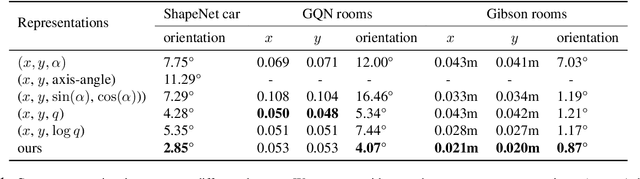
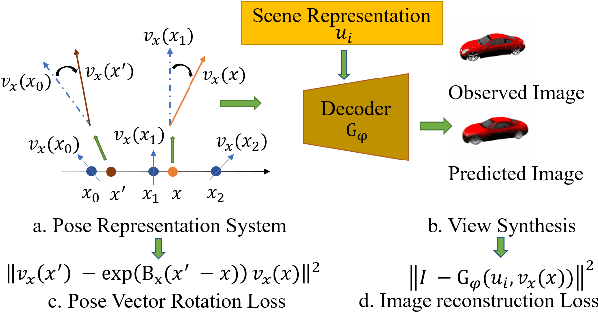
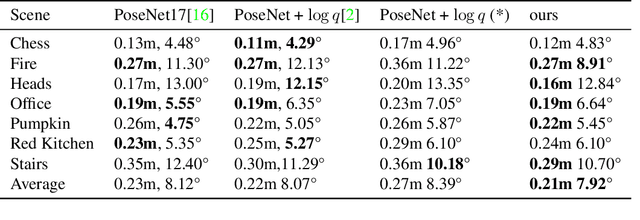
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.
Learning Triadic Belief Dynamics in Nonverbal Communication from Videos
Apr 07, 2021

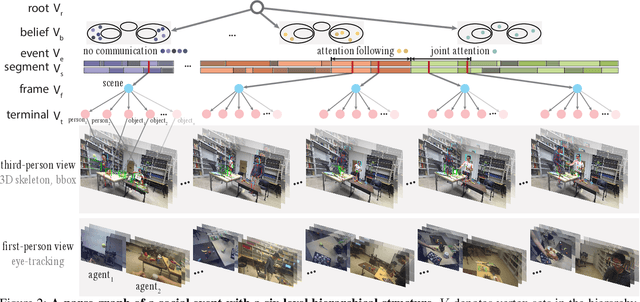
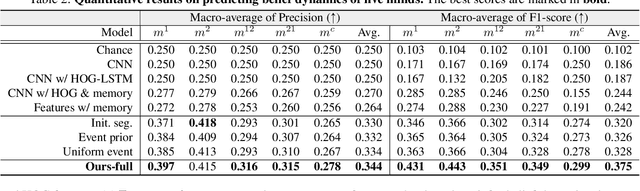
Humans possess a unique social cognition capability; nonverbal communication can convey rich social information among agents. In contrast, such crucial social characteristics are mostly missing in the existing scene understanding literature. In this paper, we incorporate different nonverbal communication cues (e.g., gaze, human poses, and gestures) to represent, model, learn, and infer agents' mental states from pure visual inputs. Crucially, such a mental representation takes the agent's belief into account so that it represents what the true world state is and infers the beliefs in each agent's mental state, which may differ from the true world states. By aggregating different beliefs and true world states, our model essentially forms "five minds" during the interactions between two agents. This "five minds" model differs from prior works that infer beliefs in an infinite recursion; instead, agents' beliefs are converged into a "common mind". Based on this representation, we further devise a hierarchical energy-based model that jointly tracks and predicts all five minds. From this new perspective, a social event is interpreted by a series of nonverbal communication and belief dynamics, which transcends the classic keyframe video summary. In the experiments, we demonstrate that using such a social account provides a better video summary on videos with rich social interactions compared with state-of-the-art keyframe video summary methods.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021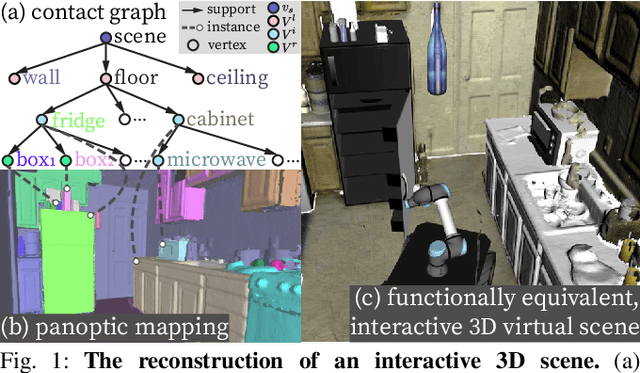
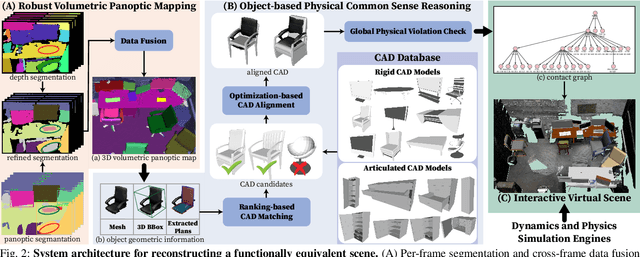
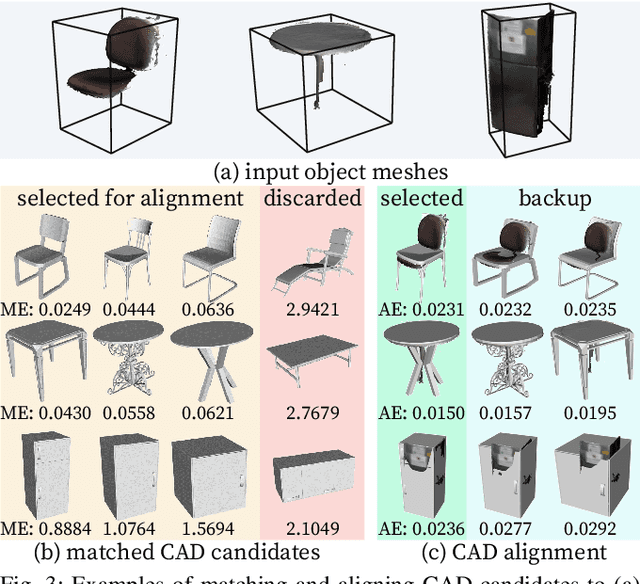
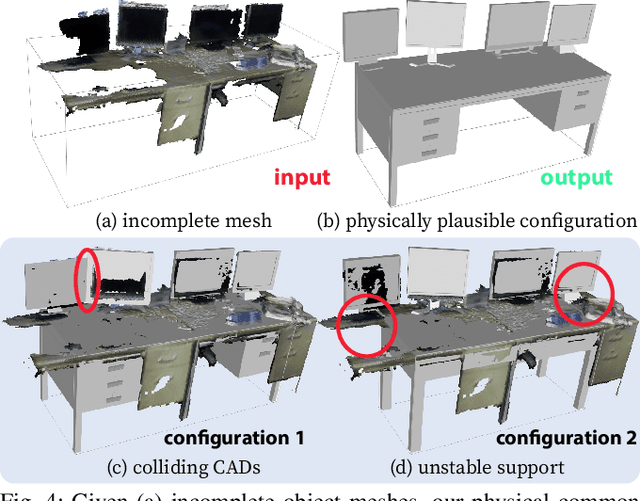
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.
ACRE: Abstract Causal REasoning Beyond Covariation
Mar 26, 2021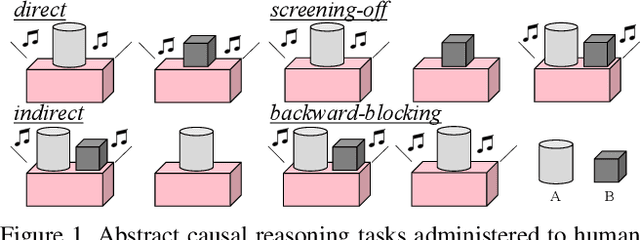


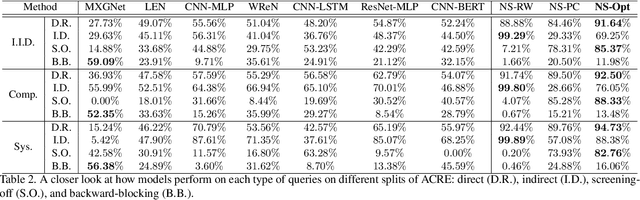
Causal induction, i.e., identifying unobservable mechanisms that lead to the observable relations among variables, has played a pivotal role in modern scientific discovery, especially in scenarios with only sparse and limited data. Humans, even young toddlers, can induce causal relationships surprisingly well in various settings despite its notorious difficulty. However, in contrast to the commonplace trait of human cognition is the lack of a diagnostic benchmark to measure causal induction for modern Artificial Intelligence (AI) systems. Therefore, in this work, we introduce the Abstract Causal REasoning (ACRE) dataset for systematic evaluation of current vision systems in causal induction. Motivated by the stream of research on causal discovery in Blicket experiments, we query a visual reasoning system with the following four types of questions in either an independent scenario or an interventional scenario: direct, indirect, screening-off, and backward-blocking, intentionally going beyond the simple strategy of inducing causal relationships by covariation. By analyzing visual reasoning architectures on this testbed, we notice that pure neural models tend towards an associative strategy under their chance-level performance, whereas neuro-symbolic combinations struggle in backward-blocking reasoning. These deficiencies call for future research in models with a more comprehensive capability of causal induction.
Congestion-aware Multi-agent Trajectory Prediction for Collision Avoidance
Mar 26, 2021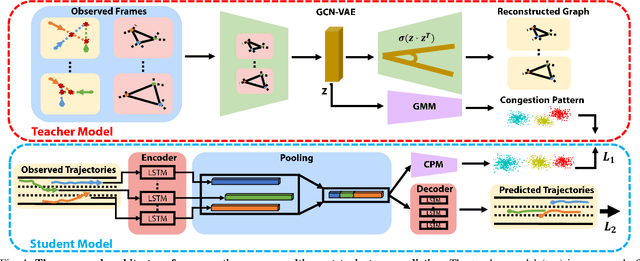
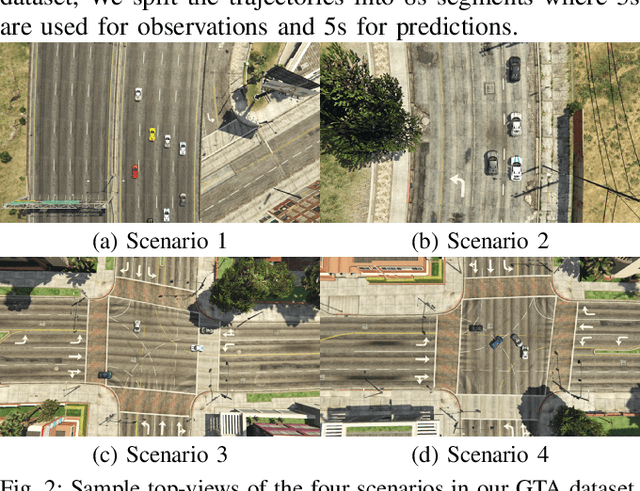
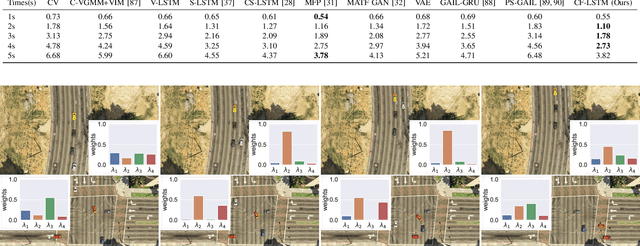
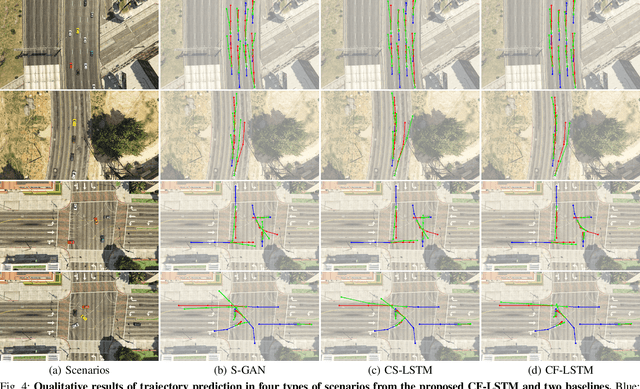
Predicting agents' future trajectories plays a crucial role in modern AI systems, yet it is challenging due to intricate interactions exhibited in multi-agent systems, especially when it comes to collision avoidance. To address this challenge, we propose to learn congestion patterns as contextual cues explicitly and devise a novel "Sense--Learn--Reason--Predict" framework by exploiting advantages of three different doctrines of thought, which yields the following desirable benefits: (i) Representing congestion as contextual cues via latent factors subsumes the concept of social force commonly used in physics-based approaches and implicitly encodes the distance as a cost, similar to the way a planning-based method models the environment. (ii) By decomposing the learning phases into two stages, a "student" can learn contextual cues from a "teacher" while generating collision-free trajectories. To make the framework computationally tractable, we formulate it as an optimization problem and derive an upper bound by leveraging the variational parametrization. In experiments, we demonstrate that the proposed model is able to generate collision-free trajectory predictions in a synthetic dataset designed for collision avoidance evaluation and remains competitive on the commonly used NGSIM US-101 highway dataset.
Abstract Spatial-Temporal Reasoning via Probabilistic Abduction and Execution
Mar 26, 2021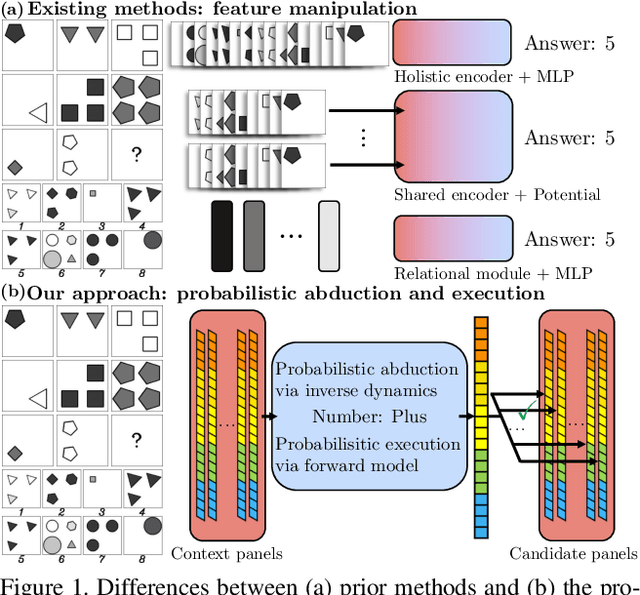
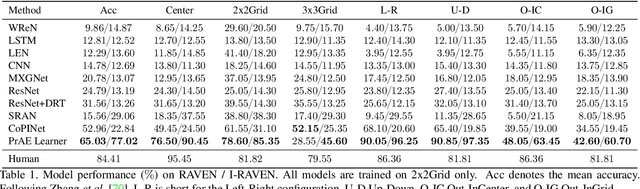
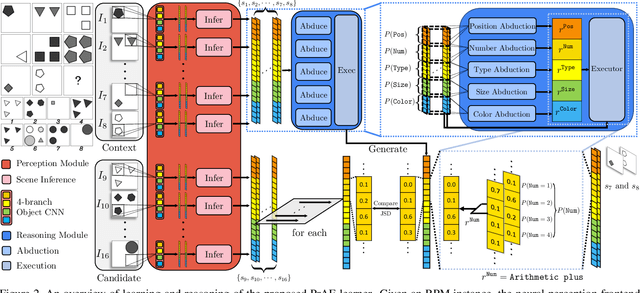

Spatial-temporal reasoning is a challenging task in Artificial Intelligence (AI) due to its demanding but unique nature: a theoretic requirement on representing and reasoning based on spatial-temporal knowledge in mind, and an applied requirement on a high-level cognitive system capable of navigating and acting in space and time. Recent works have focused on an abstract reasoning task of this kind -- Raven's Progressive Matrices (RPM). Despite the encouraging progress on RPM that achieves human-level performance in terms of accuracy, modern approaches have neither a treatment of human-like reasoning on generalization, nor a potential to generate answers. To fill in this gap, we propose a neuro-symbolic Probabilistic Abduction and Execution (PrAE) learner; central to the PrAE learner is the process of probabilistic abduction and execution on a probabilistic scene representation, akin to the mental manipulation of objects. Specifically, we disentangle perception and reasoning from a monolithic model. The neural visual perception frontend predicts objects' attributes, later aggregated by a scene inference engine to produce a probabilistic scene representation. In the symbolic logical reasoning backend, the PrAE learner uses the representation to abduce the hidden rules. An answer is predicted by executing the rules on the probabilistic representation. The entire system is trained end-to-end in an analysis-by-synthesis manner without any visual attribute annotations. Extensive experiments demonstrate that the PrAE learner improves cross-configuration generalization and is capable of rendering an answer, in contrast to prior works that merely make a categorical choice from candidates.
VLGrammar: Grounded Grammar Induction of Vision and Language
Mar 24, 2021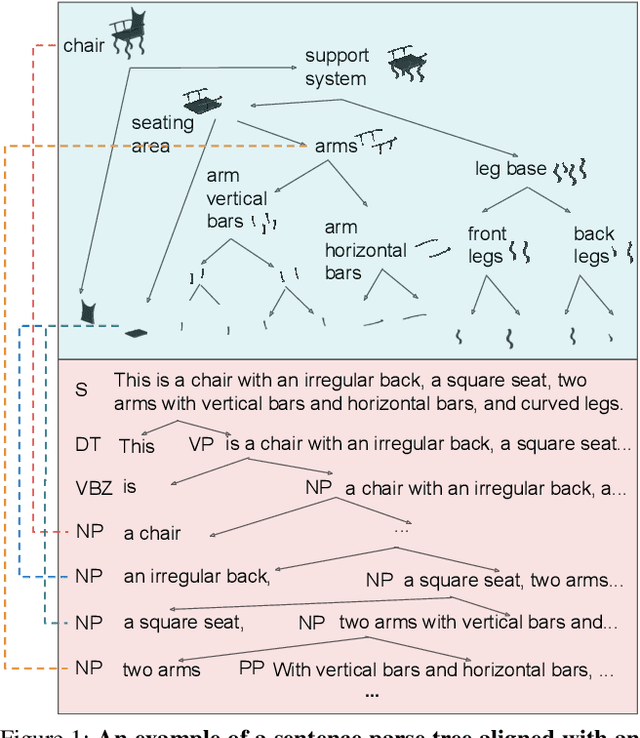
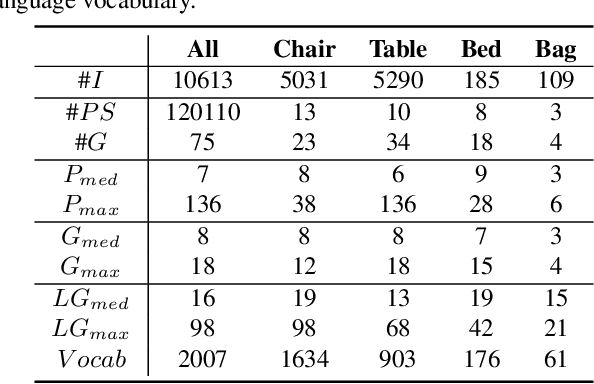

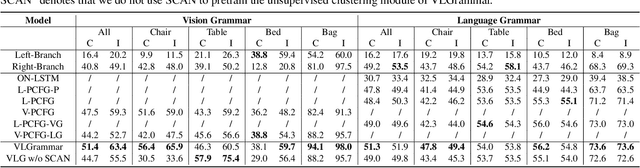
Cognitive grammar suggests that the acquisition of language grammar is grounded within visual structures. While grammar is an essential representation of natural language, it also exists ubiquitously in vision to represent the hierarchical part-whole structure. In this work, we study grounded grammar induction of vision and language in a joint learning framework. Specifically, we present VLGrammar, a method that uses compound probabilistic context-free grammars (compound PCFGs) to induce the language grammar and the image grammar simultaneously. We propose a novel contrastive learning framework to guide the joint learning of both modules. To provide a benchmark for the grounded grammar induction task, we collect a large-scale dataset, \textsc{PartIt}, which contains human-written sentences that describe part-level semantics for 3D objects. Experiments on the \textsc{PartIt} dataset show that VLGrammar outperforms all baselines in image grammar induction and language grammar induction. The learned VLGrammar naturally benefits related downstream tasks. Specifically, it improves the image unsupervised clustering accuracy by 30\%, and performs well in image retrieval and text retrieval. Notably, the induced grammar shows superior generalizability by easily generalizing to unseen categories.
Towards Socially Intelligent Agents with Mental State Transition and Human Utility
Mar 12, 2021

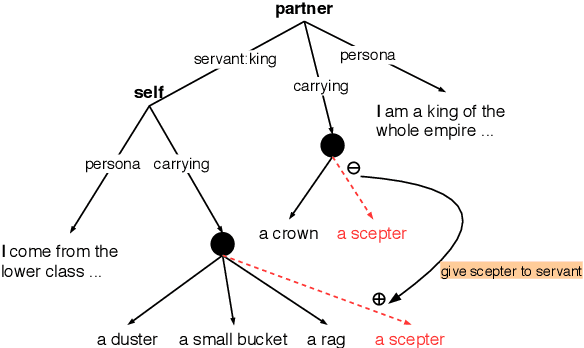
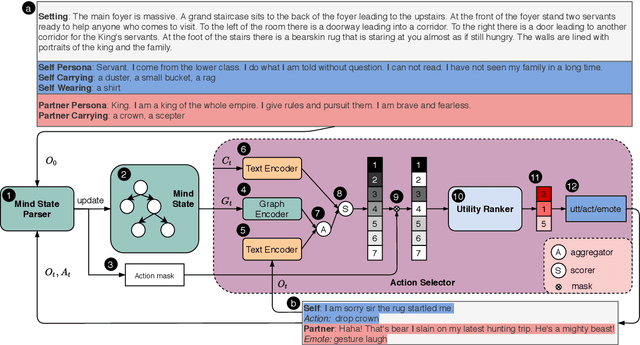
Building a socially intelligent agent involves many challenges, one of which is to track the agent's mental state transition and teach the agent to make rational decisions guided by its utility like a human. Towards this end, we propose to incorporate a mental state parser and utility model into dialogue agents. The hybrid mental state parser extracts information from both the dialogue and event observations and maintains a graphical representation of the agent's mind; Meanwhile, the utility model is a ranking model that learns human preferences from a crowd-sourced social commonsense dataset, Social IQA. Empirical results show that the proposed model attains state-of-the-art performance on the dialogue/action/emotion prediction task in the fantasy text-adventure game dataset, LIGHT. We also show example cases to demonstrate: (\textit{i}) how the proposed mental state parser can assist agent's decision by grounding on the context like locations and objects, and (\textit{ii}) how the utility model can help the agent make reasonable decisions in a dilemma. To the best of our knowledge, we are the first work that builds a socially intelligent agent by incorporating a hybrid mental state parser for both discrete events and continuous dialogues parsing and human-like utility modeling.