 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA robust and compliant robotic assembly control strategy for batch precision assembly task with uncertain fit types and fit amounts
Aug 17, 2025In some high-precision industrial applications, robots are deployed to perform precision assembly tasks on mass batches of manufactured pegs and holes. If the peg and hole are designed with transition fit, machining errors may lead to either a clearance or an interference fit for a specific pair of components, with uncertain fit amounts. This paper focuses on the robotic batch precision assembly task involving components with uncertain fit types and fit amounts, and proposes an efficient methodology to construct the robust and compliant assembly control strategy. Specifically, the batch precision assembly task is decomposed into multiple deterministic subtasks, and a force-vision fusion controller-driven reinforcement learning method and a multi-task reinforcement learning training method (FVFC-MTRL) are proposed to jointly learn multiple compliance control strategies for these subtasks. Subsequently, the multi-teacher policy distillation approach is designed to integrate multiple trained strategies into a unified student network, thereby establishing a robust control strategy. Real-world experiments demonstrate that the proposed method successfully constructs the robust control strategy for high-precision assembly task with different fit types and fit amounts. Moreover, the MTRL framework significantly improves training efficiency, and the final developed control strategy achieves superior force compliance and higher success rate compared with many existing methods.
Complex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
A Multi-Stage Large Language Model Framework for Extracting Suicide-Related Social Determinants of Health
Aug 07, 2025Background: Understanding social determinants of health (SDoH) factors contributing to suicide incidents is crucial for early intervention and prevention. However, data-driven approaches to this goal face challenges such as long-tailed factor distributions, analyzing pivotal stressors preceding suicide incidents, and limited model explainability. Methods: We present a multi-stage large language model framework to enhance SDoH factor extraction from unstructured text. Our approach was compared to other state-of-the-art language models (i.e., pre-trained BioBERT and GPT-3.5-turbo) and reasoning models (i.e., DeepSeek-R1). We also evaluated how the model's explanations help people annotate SDoH factors more quickly and accurately. The analysis included both automated comparisons and a pilot user study. Results: We show that our proposed framework demonstrated performance boosts in the overarching task of extracting SDoH factors and in the finer-grained tasks of retrieving relevant context. Additionally, we show that fine-tuning a smaller, task-specific model achieves comparable or better performance with reduced inference costs. The multi-stage design not only enhances extraction but also provides intermediate explanations, improving model explainability. Conclusions: Our approach improves both the accuracy and transparency of extracting suicide-related SDoH from unstructured texts. These advancements have the potential to support early identification of individuals at risk and inform more effective prevention strategies.
ChineseEEG-2: An EEG Dataset for Multimodal Semantic Alignment and Neural Decoding during Reading and Listening
Aug 06, 2025EEG-based neural decoding requires large-scale benchmark datasets. Paired brain-language data across speaking, listening, and reading modalities are essential for aligning neural activity with the semantic representation of large language models (LLMs). However, such datasets are rare, especially for non-English languages. Here, we present ChineseEEG-2, a high-density EEG dataset designed for benchmarking neural decoding models under real-world language tasks. Building on our previous ChineseEEG dataset, which focused on silent reading, ChineseEEG-2 adds two active modalities: Reading Aloud (RA) and Passive Listening (PL), using the same Chinese corpus. EEG and audio were simultaneously recorded from four participants during ~10.7 hours of reading aloud. These recordings were then played to eight other participants, collecting ~21.6 hours of EEG during listening. This setup enables speech temporal and semantic alignment across the RA and PL modalities. ChineseEEG-2 includes EEG signals, precise audio, aligned semantic embeddings from pre-trained language models, and task labels. Together with ChineseEEG, this dataset supports joint semantic alignment learning across speaking, listening, and reading. It enables benchmarking of neural decoding algorithms and promotes brain-LLM alignment under multimodal language tasks, especially in Chinese. ChineseEEG-2 provides a benchmark dataset for next-generation neural semantic decoding.
Monocular Semantic Scene Completion via Masked Recurrent Networks
Jul 23, 2025Monocular Semantic Scene Completion (MSSC) aims to predict the voxel-wise occupancy and semantic category from a single-view RGB image. Existing methods adopt a single-stage framework that aims to simultaneously achieve visible region segmentation and occluded region hallucination, while also being affected by inaccurate depth estimation. Such methods often achieve suboptimal performance, especially in complex scenes. We propose a novel two-stage framework that decomposes MSSC into coarse MSSC followed by the Masked Recurrent Network. Specifically, we propose the Masked Sparse Gated Recurrent Unit (MS-GRU) which concentrates on the occupied regions by the proposed mask updating mechanism, and a sparse GRU design is proposed to reduce the computation cost. Additionally, we propose the distance attention projection to reduce projection errors by assigning different attention scores according to the distance to the observed surface. Experimental results demonstrate that our proposed unified framework, MonoMRN, effectively supports both indoor and outdoor scenes and achieves state-of-the-art performance on the NYUv2 and SemanticKITTI datasets. Furthermore, we conduct robustness analysis under various disturbances, highlighting the role of the Masked Recurrent Network in enhancing the model's resilience to such challenges. The source code is publicly available.
SAM4D: Segment Anything in Camera and LiDAR Streams
Jun 26, 2025


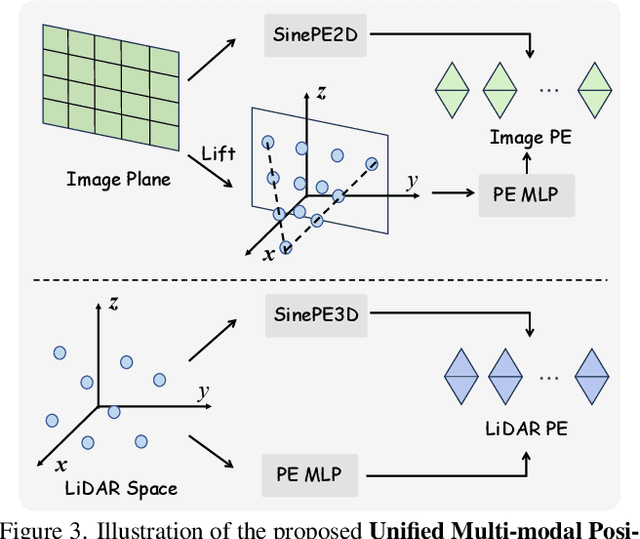
We present SAM4D, a multi-modal and temporal foundation model designed for promptable segmentation across camera and LiDAR streams. Unified Multi-modal Positional Encoding (UMPE) is introduced to align camera and LiDAR features in a shared 3D space, enabling seamless cross-modal prompting and interaction. Additionally, we propose Motion-aware Cross-modal Memory Attention (MCMA), which leverages ego-motion compensation to enhance temporal consistency and long-horizon feature retrieval, ensuring robust segmentation across dynamically changing autonomous driving scenes. To avoid annotation bottlenecks, we develop a multi-modal automated data engine that synergizes VFM-driven video masklets, spatiotemporal 4D reconstruction, and cross-modal masklet fusion. This framework generates camera-LiDAR aligned pseudo-labels at a speed orders of magnitude faster than human annotation while preserving VFM-derived semantic fidelity in point cloud representations. We conduct extensive experiments on the constructed Waymo-4DSeg, which demonstrate the powerful cross-modal segmentation ability and great potential in data annotation of proposed SAM4D.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Enhancing LLM-Based Code Generation with Complexity Metrics: A Feedback-Driven Approach
May 29, 2025Automatic code generation has gained significant momentum with the advent of Large Language Models (LLMs) such as GPT-4. Although many studies focus on improving the effectiveness of LLMs for code generation, very limited work tries to understand the generated code's characteristics and leverage that to improve failed cases. In this paper, as the most straightforward characteristic of code, we investigate the relationship between code complexity and the success of LLM generated code. Using a large set of standard complexity metrics, we first conduct an empirical analysis to explore their correlation with LLM's performance on code generation (i.e., Pass@1). Using logistic regression models, we identify which complexity metrics are most predictive of code correctness. Building on these findings, we propose an iterative feedback method, where LLMs are prompted to generate correct code based on complexity metrics from previous failed outputs. We validate our approach across multiple benchmarks (i.e., HumanEval, MBPP, LeetCode, and BigCodeBench) and various LLMs (i.e., GPT-4o, GPT-3.5 Turbo, Llama 3.1, and GPT-o3 mini), comparing the results with two baseline methods: (a) zero-shot generation, and (b) iterative execution-based feedback without our code complexity insights. Experiment results show that our approach makes notable improvements, particularly with a smaller LLM (GPT3.5 Turbo), where, e.g., Pass@1 increased by 35.71% compared to the baseline's improvement of 12.5% on the HumanEval dataset. The study expands experiments to BigCodeBench and integrates the method with the Reflexion code generation agent, leading to Pass@1 improvements of 20% (GPT-4o) and 23.07% (GPT-o3 mini). The results highlight that complexity-aware feedback enhances both direct LLM prompting and agent-based workflows.
PixelThink: Towards Efficient Chain-of-Pixel Reasoning
May 29, 2025Existing reasoning segmentation approaches typically fine-tune multimodal large language models (MLLMs) using image-text pairs and corresponding mask labels. However, they exhibit limited generalization to out-of-distribution scenarios without an explicit reasoning process. Although recent efforts leverage reinforcement learning through group-relative policy optimization (GRPO) to enhance reasoning ability, they often suffer from overthinking - producing uniformly verbose reasoning chains irrespective of task complexity. This results in elevated computational costs and limited control over reasoning quality. To address this problem, we propose PixelThink, a simple yet effective scheme that integrates externally estimated task difficulty and internally measured model uncertainty to regulate reasoning generation within a reinforcement learning paradigm. The model learns to compress reasoning length in accordance with scene complexity and predictive confidence. To support comprehensive evaluation, we introduce ReasonSeg-Diff, an extended benchmark with annotated reasoning references and difficulty scores, along with a suite of metrics designed to assess segmentation accuracy, reasoning quality, and efficiency jointly. Experimental results demonstrate that the proposed approach improves both reasoning efficiency and overall segmentation performance. Our work contributes novel perspectives towards efficient and interpretable multimodal understanding. The code and model will be publicly available.
Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps
May 24, 2025Multimodal large language models (MLLMs) have recently achieved significant progress in visual tasks, including semantic scene understanding and text-image alignment, with reasoning variants enhancing performance on complex tasks involving mathematics and logic. However, their capacity for reasoning tasks involving fine-grained visual understanding remains insufficiently evaluated. To address this gap, we introduce ReasonMap, a benchmark designed to assess the fine-grained visual understanding and spatial reasoning abilities of MLLMs. ReasonMap encompasses high-resolution transit maps from 30 cities across 13 countries and includes 1,008 question-answer pairs spanning two question types and three templates. Furthermore, we design a two-level evaluation pipeline that properly assesses answer correctness and quality. Comprehensive evaluations of 15 popular MLLMs, including both base and reasoning variants, reveal a counterintuitive pattern: among open-source models, base models outperform reasoning ones, while the opposite trend is observed in closed-source models. Additionally, performance generally degrades when visual inputs are masked, indicating that while MLLMs can leverage prior knowledge to answer some questions, fine-grained visual reasoning tasks still require genuine visual perception for strong performance. Our benchmark study offers new insights into visual reasoning and contributes to investigating the gap between open-source and closed-source models.