 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Fault Localization Context for LLM-Based Program Repair
Apr 07, 2026Fault Localization (FL) is a key component of Large Language Model (LLM)-based Automated Program Repair (APR), yet its impact remains underexplored. In particular, it is unclear how much localization is needed, whether additional context beyond the predicted buggy location is beneficial, and how such context should be retrieved. We conduct a large-scale empirical study on 500 SWE-bench Verified instances using GPT-5-mini, evaluating 61 configurations that vary file-level, element-level, and line-level context. Our results show that more context does not consistently improve repair performance. File-level localization is the dominant factor, yielding a 15-17x improvement over a no-file baseline. Expanding file context is often associated with improved performance, with successful repairs most commonly observed in configurations with approximately 6-10 relevant files. Element-level context expansion provides conditional gains that depend strongly on the file context quality, while line-level context expansion frequently degrades performance due to noise amplification. LLM-based retrieval generally outperforms structural heuristics while using fewer files and tokens. Overall, the most effective FL context strategy typically combines a broad semantic understanding at higher abstraction levels with precise line-level localization. These findings challenge our assumption that increasing the localization context uniformly improves APR, and provide practical guidance for designing LLM-based FL strategies.
Enhancing LLM-Based Code Generation with Complexity Metrics: A Feedback-Driven Approach
May 29, 2025Automatic code generation has gained significant momentum with the advent of Large Language Models (LLMs) such as GPT-4. Although many studies focus on improving the effectiveness of LLMs for code generation, very limited work tries to understand the generated code's characteristics and leverage that to improve failed cases. In this paper, as the most straightforward characteristic of code, we investigate the relationship between code complexity and the success of LLM generated code. Using a large set of standard complexity metrics, we first conduct an empirical analysis to explore their correlation with LLM's performance on code generation (i.e., Pass@1). Using logistic regression models, we identify which complexity metrics are most predictive of code correctness. Building on these findings, we propose an iterative feedback method, where LLMs are prompted to generate correct code based on complexity metrics from previous failed outputs. We validate our approach across multiple benchmarks (i.e., HumanEval, MBPP, LeetCode, and BigCodeBench) and various LLMs (i.e., GPT-4o, GPT-3.5 Turbo, Llama 3.1, and GPT-o3 mini), comparing the results with two baseline methods: (a) zero-shot generation, and (b) iterative execution-based feedback without our code complexity insights. Experiment results show that our approach makes notable improvements, particularly with a smaller LLM (GPT3.5 Turbo), where, e.g., Pass@1 increased by 35.71% compared to the baseline's improvement of 12.5% on the HumanEval dataset. The study expands experiments to BigCodeBench and integrates the method with the Reflexion code generation agent, leading to Pass@1 improvements of 20% (GPT-4o) and 23.07% (GPT-o3 mini). The results highlight that complexity-aware feedback enhances both direct LLM prompting and agent-based workflows.
Deep-Bench: Deep Learning Benchmark Dataset for Code Generation
Feb 26, 2025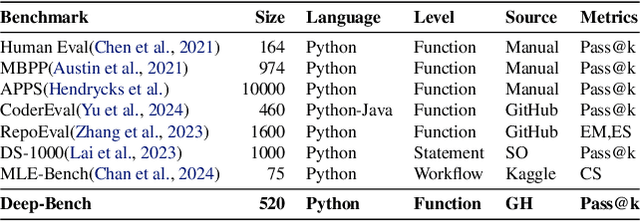
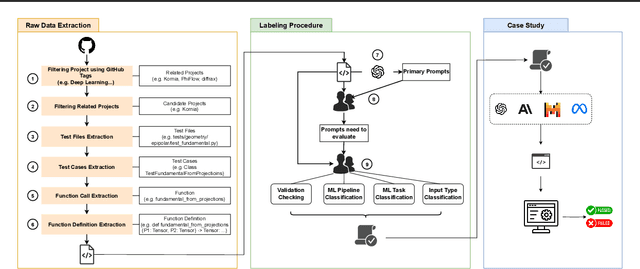

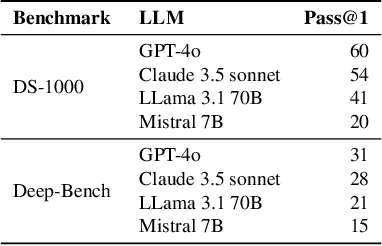
Deep learning (DL) has revolutionized areas such as computer vision, natural language processing, and more. However, developing DL systems is challenging due to the complexity of DL workflows. Large Language Models (LLMs), such as GPT, Claude, Llama, Mistral, etc., have emerged as promising tools to assist in DL code generation, offering potential solutions to these challenges. Despite this, existing benchmarks such as DS-1000 are limited, as they primarily focus on small DL code snippets related to pre/post-processing tasks and lack a comprehensive coverage of the full DL pipeline, including different DL phases and input data types. To address this, we introduce DeepBench, a novel benchmark dataset designed for function-level DL code generation. DeepBench categorizes DL problems based on three key aspects: phases such as pre-processing, model construction, and training; tasks, including classification, regression, and recommendation; and input data types such as tabular, image, and text. GPT-4o -- the state-of-the-art LLM -- achieved 31% accuracy on DeepBench, significantly lower than its 60% on DS-1000. We observed similar difficulty for other LLMs (e.g., 28% vs. 54% for Claude, 21% vs. 41% for LLaMA, and 15% vs. 20% for Mistral). This result underscores DeepBench's greater complexity. We also construct a taxonomy of issues and bugs found in LLM-generated DL code, which highlights the distinct challenges that LLMs face when generating DL code compared to general code. Furthermore, our analysis also reveals substantial performance variations across categories, with differences of up to 7% among phases and 37% among tasks. These disparities suggest that DeepBench offers valuable insights into the LLMs' performance and areas for potential improvement in the DL domain.