 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenterNet: Keypoint Triplets for Object Detection
Apr 19, 2019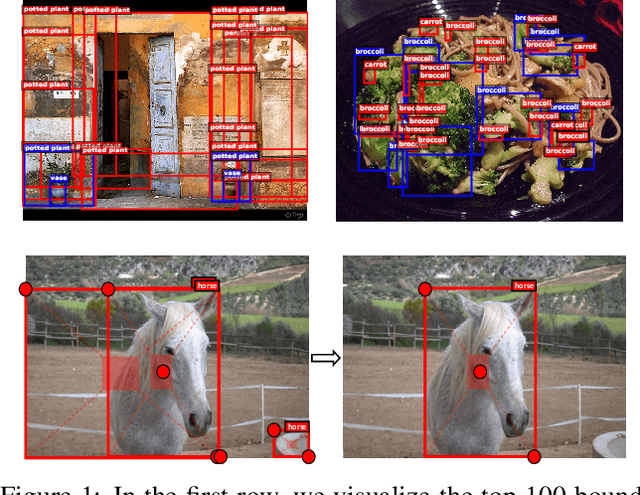
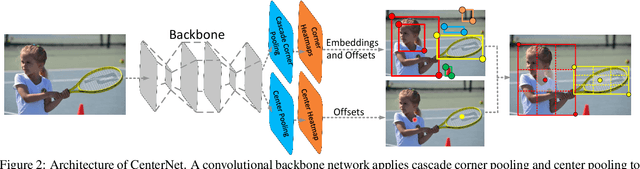
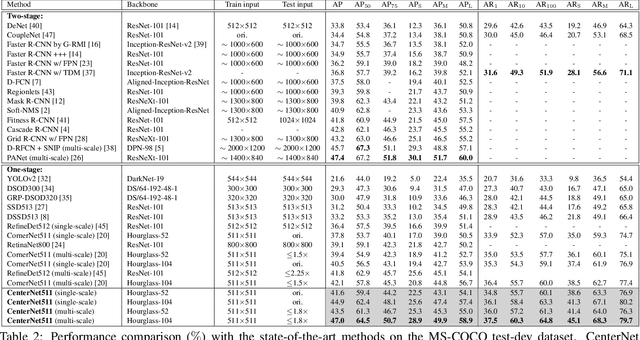
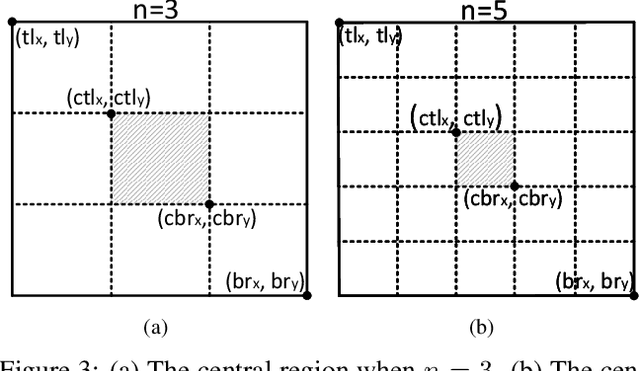
In object detection, keypoint-based approaches often suffer a large number of incorrect object bounding boxes, arguably due to the lack of an additional look into the cropped regions. This paper presents an efficient solution which explores the visual patterns within each cropped region with minimal costs. We build our framework upon a representative one-stage keypoint-based detector named CornerNet. Our approach, named CenterNet, detects each object as a triplet, rather than a pair, of keypoints, which improves both precision and recall. Accordingly, we design two customized modules named cascade corner pooling and center pooling, which play the roles of enriching information collected by both top-left and bottom-right corners and providing more recognizable information at the central regions, respectively. On the MS-COCO dataset, CenterNet achieves an AP of 47.0%, which outperforms all existing one-stage detectors by at least 4.9%. Meanwhile, with a faster inference speed, CenterNet demonstrates quite comparable performance to the top-ranked two-stage detectors. Code is available at https://github.com/Duankaiwen/CenterNet.
Prior-aware Neural Network for Partially-Supervised Multi-Organ Segmentation
Apr 12, 2019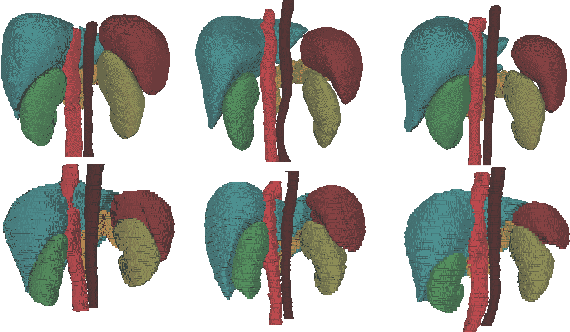
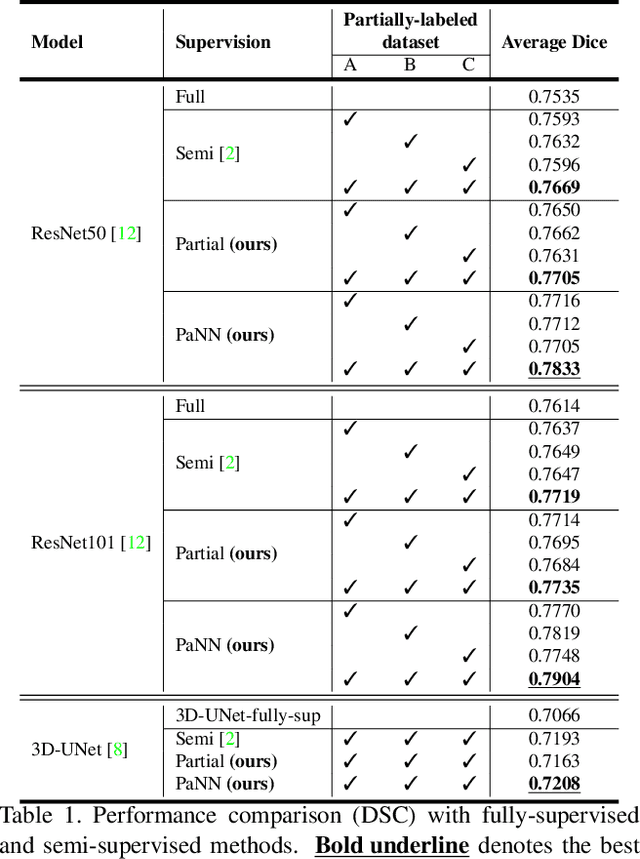
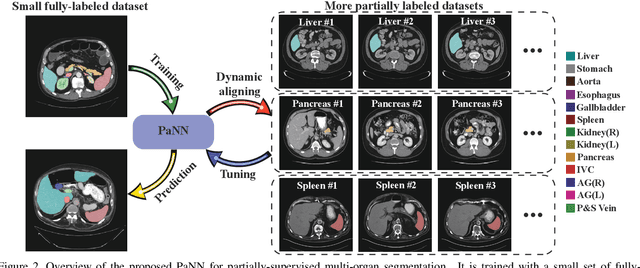
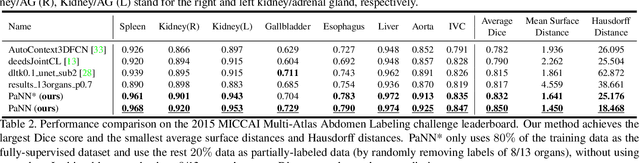
Accurate multi-organ abdominal CT segmentation is essential to many clinical applications such as computer-aided intervention. As data annotation requires massive human labor from experienced radiologists, it is common that training data are partially labeled, e.g., pancreas datasets only have the pancreas labeled while leaving the rest marked as background. However, these background labels can be misleading in multi-organ segmentation since the "background" usually contains some other organs of interest. To address the background ambiguity in these partially-labeled datasets, we propose Prior-aware Neural Network (PaNN) via explicitly incorporating anatomical priors on abdominal organ sizes, guiding the training process with domain-specific knowledge. More specifically, PaNN assumes that the average organ size distributions in the abdomen should approximate their empirical distributions, a prior statistics obtained from the fully-labeled dataset. As our training objective is difficult to be directly optimized using stochastic gradient descent [20], we propose to reformulate it in a min-max form and optimize it via the stochastic primal-dual gradient algorithm. PaNN achieves state-of-the-art performance on the MICCAI2015 challenge "Multi-Atlas Labeling Beyond the Cranial Vault", a competition on organ segmentation in the abdomen. We report an average Dice score of 84.97%, surpassing the prior art by a large margin of 3.27%.
Regional Homogeneity: Towards Learning Transferable Universal Adversarial Perturbations Against Defenses
Apr 01, 2019

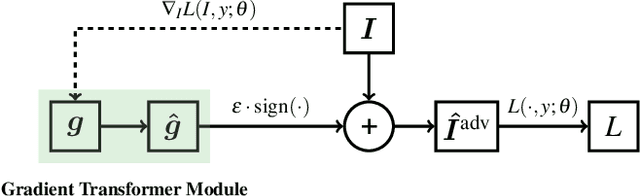
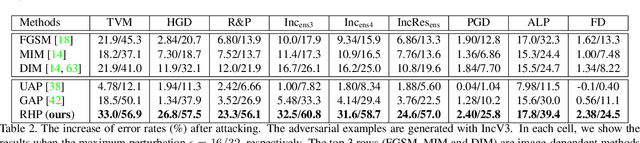
This paper focuses on learning transferable adversarial examples specifically against defense models (models to defense adversarial attacks). In particular, we show that a simple universal perturbation can fool a series of state-of-the-art defenses. Adversarial examples generated by existing attacks are generally hard to transfer to defense models. We observe the property of regional homogeneity in adversarial perturbations and suggest that the defenses are less robust to regionally homogeneous perturbations. Therefore, we propose an effective transforming paradigm and a customized gradient transformer module to transform existing perturbations into regionally homogeneous ones. Without explicitly forcing the perturbations to be universal, we observe that a well-trained gradient transformer module tends to output input-independent gradients (hence universal) benefiting from the under-fitting phenomenon. Thorough experiments demonstrate that our work significantly outperforms the prior art attacking algorithms (either image-dependent or universal ones) by an average improvement of 14.0% when attacking 9 defenses in the black-box setting. In addition to the cross-model transferability, we also verify that regionally homogeneous perturbations can well transfer across different vision tasks (attacking with the semantic segmentation task and testing on the object detection task).
Metric Attack and Defense for Person Re-identification
Mar 23, 2019
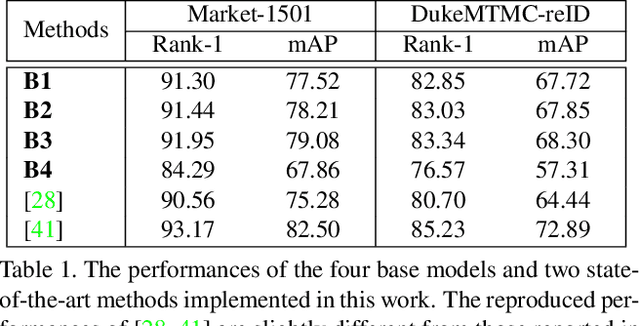

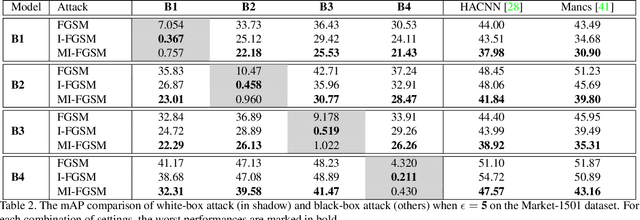
Person re-identification (re-ID) has attracted much attention recently due to its great importance in video surveillance. In general, distance metrics used to identify two person images are expected to be robust under various appearance changes. However, our work observes the extreme vulnerability of existing distance metrics to adversarial examples, generated by simply adding human-imperceptible perturbations to person images. Hence, the security danger is dramatically increased when deploying commercial re-ID systems in video surveillance. Although adversarial examples have been extensively applied for classification analysis, it is rarely studied in metric analysis like person re-identification. The most likely reason is the natural gap between the training and testing of re-ID networks, that is, the predictions of a re-ID network cannot be directly used during testing without an effective metric. In this work, we bridge the gap by proposing Adversarial Metric Attack, a parallel methodology to adversarial classification attacks. Comprehensive experiments clearly reveal the adversarial effects in re-ID systems. Meanwhile, we also present an early attempt of training a metric-preserving network, thereby defending the metric against adversarial attacks. At last, by benchmarking various adversarial settings, we expect that our work can facilitate the development of adversarial attack and defense in metric-based applications.
Hypergraph Convolution and Hypergraph Attention
Jan 23, 2019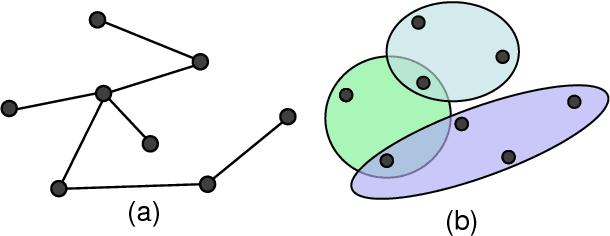
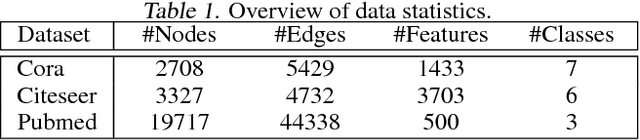
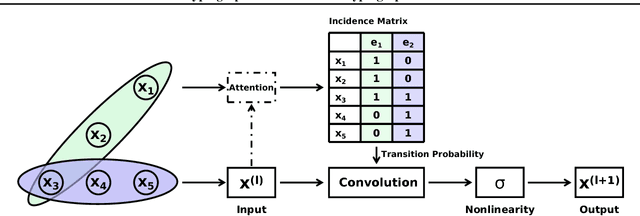
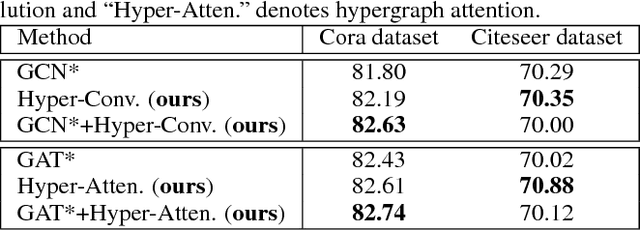
Recently, graph neural networks have attracted great attention and achieved prominent performance in various research fields. Most of those algorithms have assumed pairwise relationships of objects of interest. However, in many real applications, the relationships between objects are in higher-order, beyond a pairwise formulation. To efficiently learn deep embeddings on the high-order graph-structured data, we introduce two end-to-end trainable operators to the family of graph neural networks, i.e., hypergraph convolution and hypergraph attention. Whilst hypergraph convolution defines the basic formulation of performing convolution on a hypergraph, hypergraph attention further enhances the capacity of representation learning by leveraging an attention module. With the two operators, a graph neural network is readily extended to a more flexible model and applied to diverse applications where non-pairwise relationships are observed. Extensive experimental results with semi-supervised node classification demonstrate the effectiveness of hypergraph convolution and hypergraph attention.
Learn to Interpret Atari Agents
Dec 29, 2018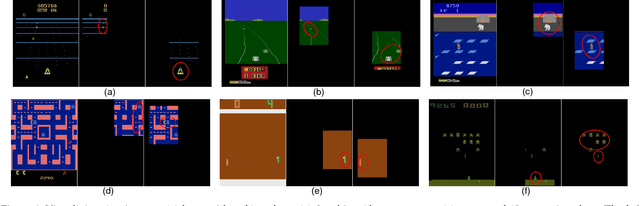
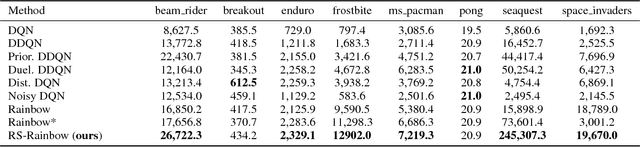
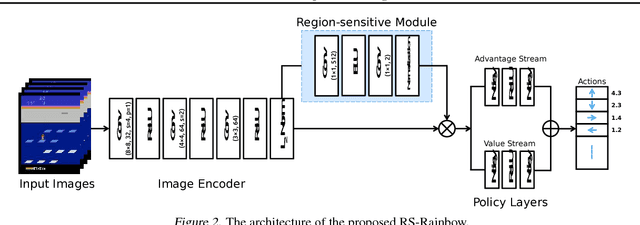

Deep Reinforcement Learning (DeepRL) models surpass human-level performance in a multitude of tasks. Standing in stark contrast to the stellar performance is the obscure nature of the learned policies. The direct mapping from states to actions makes it hard to interpret the rationale behind the decision making of agents. In contrast to previous a-posteriori methods of visualising DeepRL policies, we propose an end-to-end trainable framework based on Rainbow, a representative Deep Q-Network (DQN) agent. Our method automatically detects important regions in the input domain, which enables characterization of general strategy and explanation for non-intuitive behaviors. Hence, we call it Region Sensitive Rainbow (RS-Rainbow). RS-Rainbow utilises a simple yet effective mechanism to incorporate innate visualisation ability into the learning model, not only improving the interpretability, but enabling the agent to leverage enhanced state representations for improved performance. Without extra supervision, specialised feature detectors focusing on distinct aspects of gameplay can be learned. Extensive experiments on the challenging platform of Atari 2600 demonstrates the superiority of RS-Rainbow. In particular, our agent achieves state of the art at just 25% of the training frames without massive large-scale parallel training.
Learning Transferable Adversarial Examples via Ghost Networks
Dec 09, 2018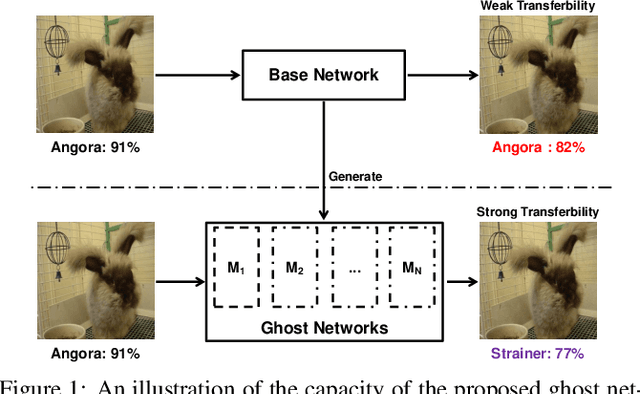


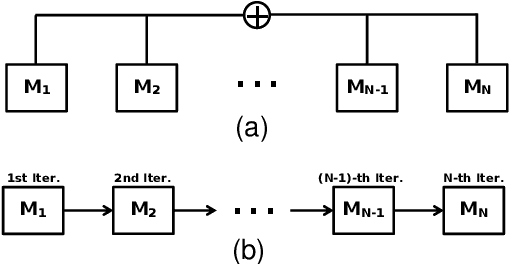
The recent development of adversarial attack has proven that ensemble-based methods can perform black-box attack better than the traditional, non-ensemble ones. However, those methods generally suffer from high complexity. They require a family of diverse models, and ensembling them afterward, both of which are computationally expensive. In this paper, we propose Ghost Networks to efficiently learn transferable adversarial examples. The key principle of ghost networks is to perturb an existing model, which potentially generates a huge set of diverse models. Those models are subsequently fused by longitudinal ensemble. Both steps almost require no extra time and space consumption. Extensive experimental results suggest that the number of networks is essential for improving the transferability of adversarial examples, but it is less necessary to independently train different networks and then ensemble them in an intensive aggregation way. Instead, our work can be a computationally cheap plug-in, which can be easily applied to improve adversarial approaches both in single-model attack and multi-model attack, compatible with both residual and non-residual networks. In particular, by re-producing the NIPS 2017 adversarial competition, our work outperforms the No.1 attack submission by a large margin, which demonstrates its effectiveness and efficiency.
Learning Attraction Field Representation for Robust Line Segment Detection
Dec 05, 2018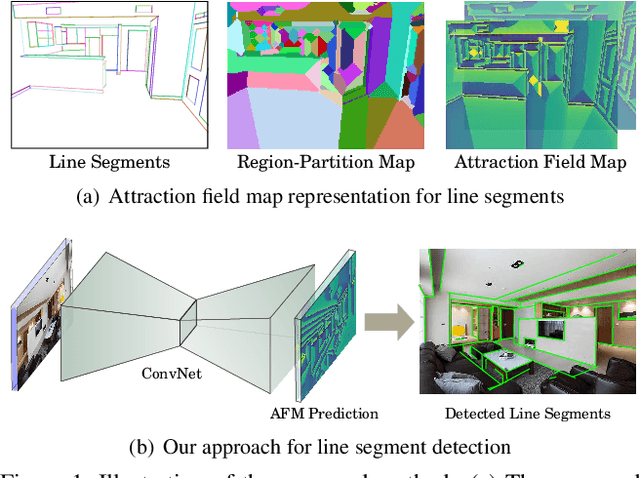

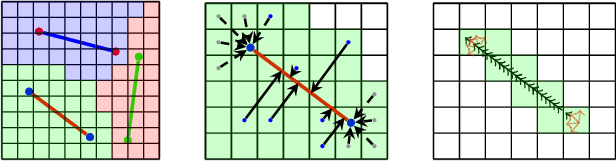
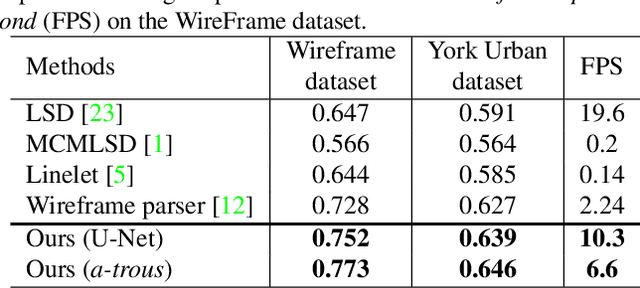
This paper presents a region-partition based attraction field dual representation for line segment maps, and thus poses the problem of line segment detection (LSD) as the region coloring problem. The latter is then addressed by learning deep convolutional neural networks (ConvNets) for accuracy, robustness and efficiency. For a 2D line segment map, our dual representation consists of three components: (i) A region-partition map in which every pixel is assigned to one and only one line segment; (ii) An attraction field map in which every pixel in a partition region is encoded by its 2D projection vector w.r.t. the associated line segment; and (iii) A squeeze module which squashes the attraction field to a line segment map that almost perfectly recovers the input one. By leveraging the duality, we learn ConvNets to compute the attraction field maps for raw in-put images, followed by the squeeze module for LSD, in an end-to-end manner. Our method rigorously addresses several challenges in LSD such as local ambiguity and class imbalance. Our method also harnesses the best practices developed in ConvNets based semantic segmentation methods such as the encoder-decoder architecture and the a-trous convolution. In experiments, our method is tested on the WireFrame dataset and the YorkUrban dataset with state-of-the-art performance obtained. Especially, we advance the performance by 4.5 percents on the WireFrame dataset. Our method is also fast with 6.6~10.4 FPS, outperforming most of existing line segment detectors.
PCL: Proposal Cluster Learning for Weakly Supervised Object Detection
Oct 13, 2018

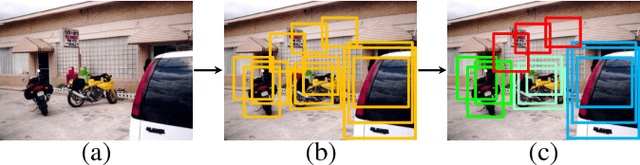

Weakly Supervised Object Detection (WSOD), using only image-level annotations to train object detectors, is of growing importance in object recognition. In this paper, we propose a novel deep network for WSOD. Unlike previous networks that transfer the object detection problem to an image classification problem using Multiple Instance Learning (MIL), our strategy generates proposal clusters to learn refined instance classifiers by an iterative process. The proposals in the same cluster are spatially adjacent and associated with the same object. This prevents the network from concentrating too much on parts of objects instead of whole objects. We first show that instances can be assigned object or background labels directly based on proposal clusters for instance classifier refinement, and then show that treating each cluster as a small new bag yields fewer ambiguities than the directly assigning label method. The iterative instance classifier refinement is implemented online using multiple streams in convolutional neural networks, where the first is an MIL network and the others are for instance classifier refinement supervised by the preceding one. Experiments are conducted on the PASCAL VOC, ImageNet detection, and MS-COCO benchmarks for WSOD. Results show that our method outperforms the previous state of the art significantly.
Hard-Aware Point-to-Set Deep Metric for Person Re-identification
Jul 30, 2018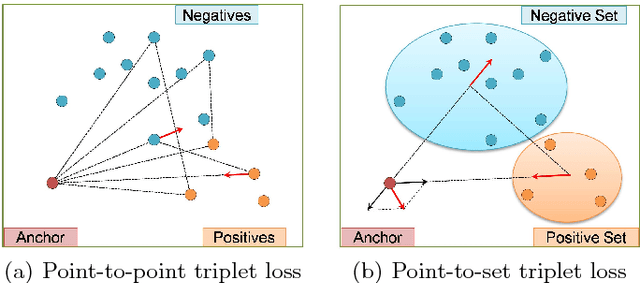
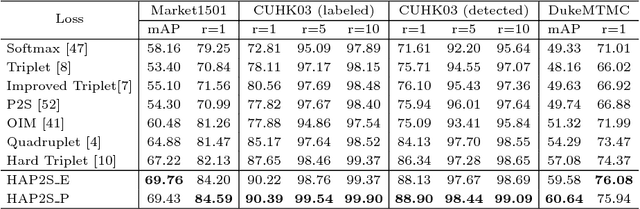
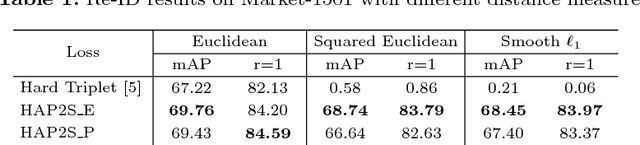
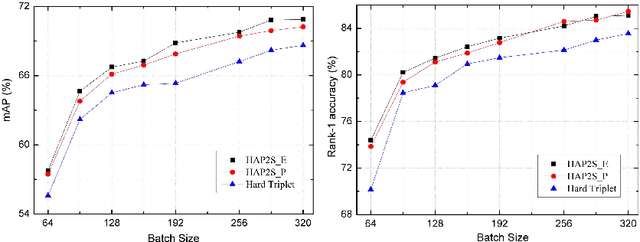
Person re-identification (re-ID) is a highly challenging task due to large variations of pose, viewpoint, illumination, and occlusion. Deep metric learning provides a satisfactory solution to person re-ID by training a deep network under supervision of metric loss, e.g., triplet loss. However, the performance of deep metric learning is greatly limited by traditional sampling methods. To solve this problem, we propose a Hard-Aware Point-to-Set (HAP2S) loss with a soft hard-mining scheme. Based on the point-to-set triplet loss framework, the HAP2S loss adaptively assigns greater weights to harder samples. Several advantageous properties are observed when compared with other state-of-the-art loss functions: 1) Accuracy: HAP2S loss consistently achieves higher re-ID accuracies than other alternatives on three large-scale benchmark datasets; 2) Robustness: HAP2S loss is more robust to outliers than other losses; 3) Flexibility: HAP2S loss does not rely on a specific weight function, i.e., different instantiations of HAP2S loss are equally effective. 4) Generality: In addition to person re-ID, we apply the proposed method to generic deep metric learning benchmarks including CUB-200-2011 and Cars196, and also achieve state-of-the-art results.