 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Instruction Learning
Feb 28, 2023



Instruction learning of Large Language Models (LLMs) has enabled zero-shot task generalization. However, instruction learning has been predominantly approached as a fine-tuning problem, including instruction tuning and reinforcement learning from human feedback, where LLMs are multi-task fine-tuned on various tasks with instructions. In this paper, we present a surprising finding that applying in-context learning to instruction learning, referred to as In-Context Instruction Learning (ICIL), significantly improves the zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. One of the core advantages of ICIL is that it uses a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. In particular, we demonstrate that the most powerful instruction-fine-tuned baseline (text-davinci-003) also benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Contextualized Generative Retrieval
Oct 07, 2022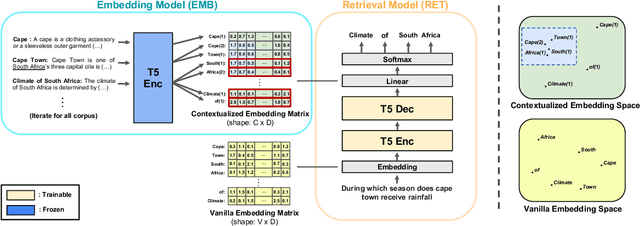
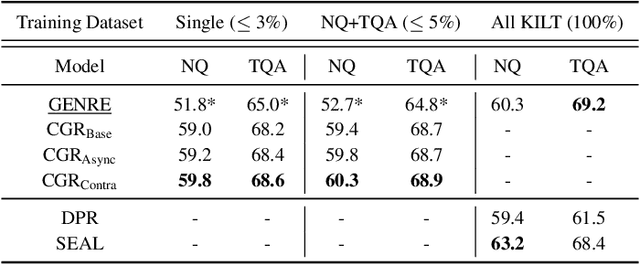
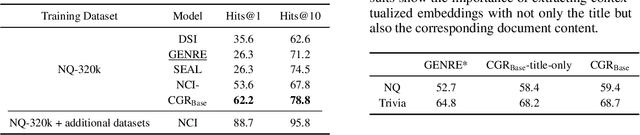
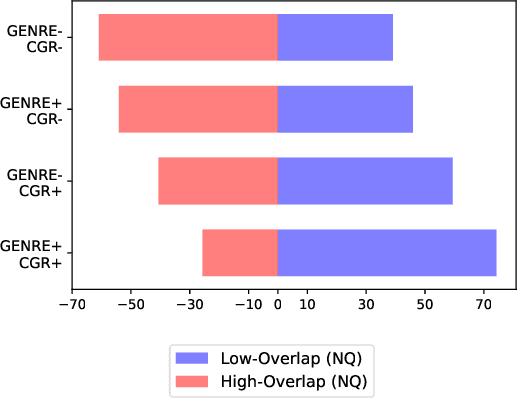
The text retrieval task is mainly performed in two ways: the bi-encoder approach and the generative approach. The bi-encoder approach maps the document and query embeddings to common vector space and performs a nearest neighbor search. It stably shows high performance and efficiency across different domains but has an embedding space bottleneck as it interacts in L2 or inner product space. The generative retrieval model retrieves by generating a target sequence and overcomes the embedding space bottleneck by interacting in the parametric space. However, it fails to retrieve the information it has not seen during the training process as it depends solely on the information encoded in its own model parameters. To leverage the advantages of both approaches, we propose Contextualized Generative Retrieval model, which uses contextualized embeddings (output embeddings of a language model encoder) as vocab embeddings at the decoding step of generative retrieval. The model uses information encoded in both the non-parametric space of contextualized token embeddings and the parametric space of the generative retrieval model. Our approach of generative retrieval with contextualized vocab embeddings shows higher performance than generative retrieval with only vanilla vocab embeddings in the document retrieval task, an average of 6% higher performance in KILT (NQ, TQA) and 2X higher in NQ-320k, suggesting the benefits of using contextualized embedding in generative retrieval models.
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Oct 04, 2022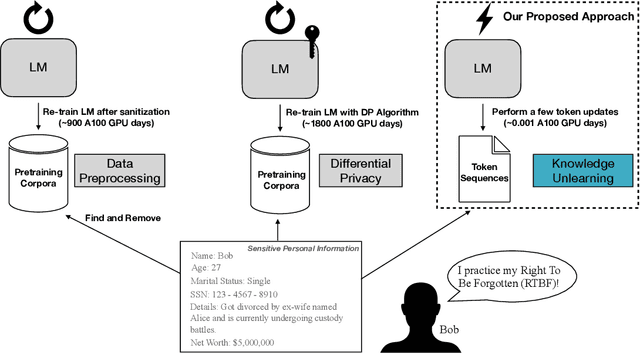
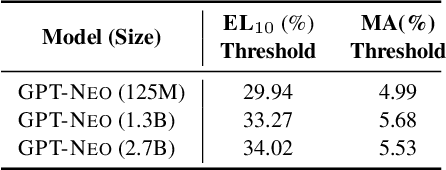
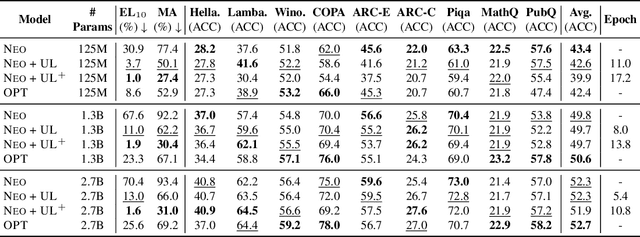
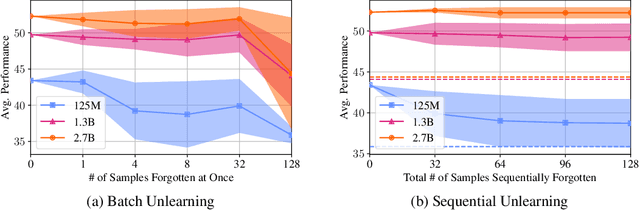
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly focused on data preprocessing and differential privacy methods, both requiring re-training the underlying LM. We propose knowledge unlearning as an alternative method to reduce privacy risks for LMs post hoc. We show that simply applying the unlikelihood training objective to target token sequences is effective at forgetting them with little to no degradation of general language modeling performances; it sometimes even substantially improves the underlying LM with just a few iterations. We also find that sequential unlearning is better than trying to unlearn all the data at once and that unlearning is highly dependent on which kind of data (domain) is forgotten. By showing comparisons with a previous data preprocessing method known to mitigate privacy risks for LMs, we show that unlearning can give a stronger empirical privacy guarantee in scenarios where the data vulnerable to extraction attacks are known a priori while being orders of magnitude more computationally efficient. We release the code and dataset needed to replicate our results at https://github.com/joeljang/knowledge-unlearning .
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models
Apr 29, 2022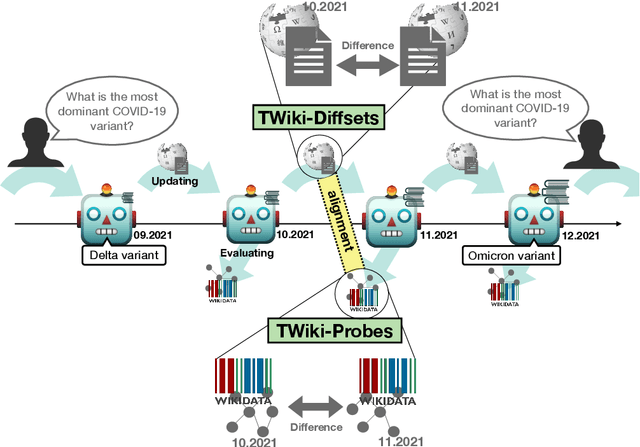
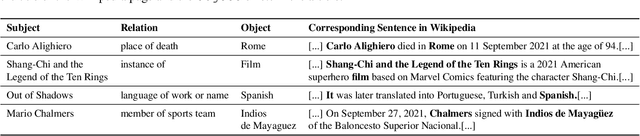

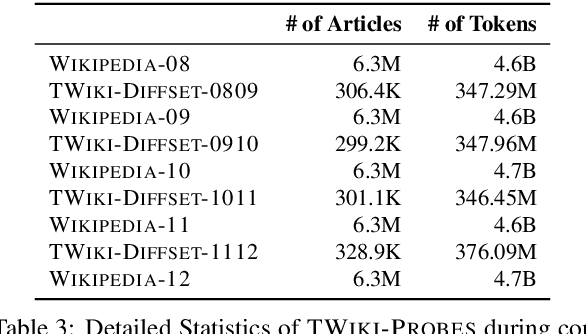
Language Models (LMs) become outdated as the world changes; they often fail to perform tasks requiring recent factual information which was absent or different during training, a phenomenon called temporal misalignment. This is especially a challenging problem because the research community still lacks a coherent dataset for assessing the adaptability of LMs to frequently-updated knowledge corpus such as Wikipedia. To this end, we introduce TemporalWiki, a lifelong benchmark for ever-evolving LMs that utilizes the difference between consecutive snapshots of English Wikipedia and English Wikidata for training and evaluation, respectively. The benchmark hence allows researchers to periodically track an LM's ability to retain previous knowledge and acquire updated/new knowledge at each point in time. We also find that training an LM on the diff data through continual learning methods achieves similar or better perplexity than on the entire snapshot in our benchmark with 12 times less computational cost, which verifies that factual knowledge in LMs can be safely updated with minimal training data via continual learning. The dataset and the code are available at https://github.com/joeljang/temporalwiki .
Generative Retrieval for Long Sequences
Apr 27, 2022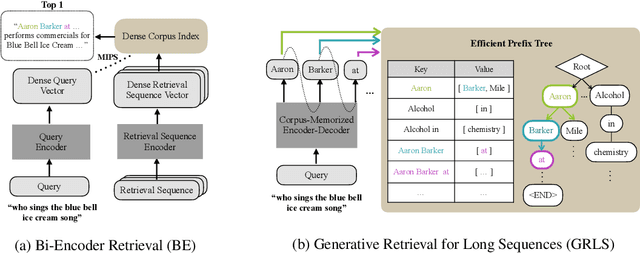
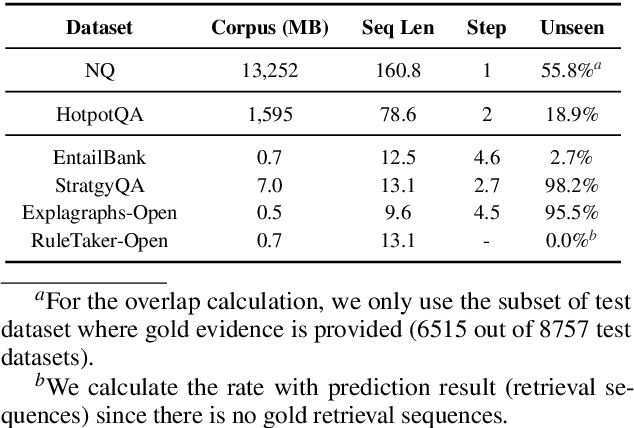
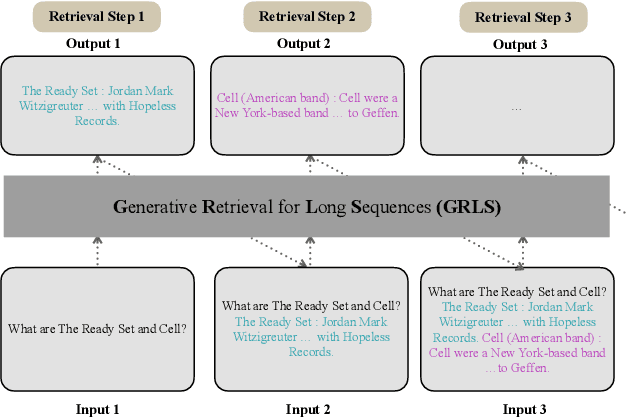
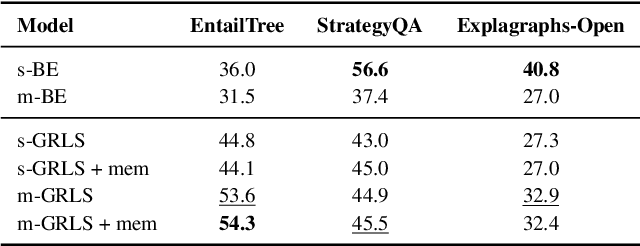
Text retrieval is often formulated as mapping the query and the target items (e.g., passages) to the same vector space and finding the item whose embedding is closest to that of the query. In this paper, we explore a generative approach as an alternative, where we use an encoder-decoder model to memorize the target corpus in a generative manner and then finetune it on query-to-passage generation. As GENRE(Cao et al., 2021) has shown that entities can be retrieved in a generative way, our work can be considered as its generalization to longer text. We show that it consistently achieves comparable performance to traditional bi-encoder retrieval on diverse datasets and is especially strong at retrieving highly structured items, such as reasoning chains and graph relations, while demonstrating superior GPU memory and time complexity. We also conjecture that generative retrieval is complementary to traditional retrieval, as we find that an ensemble of both outperforms homogeneous ensembles.
Towards Continual Knowledge Learning of Language Models
Oct 26, 2021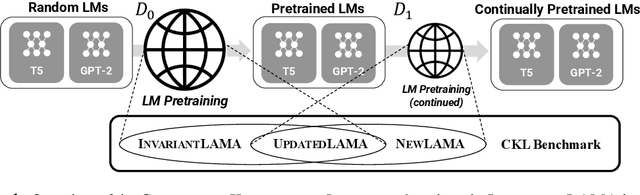

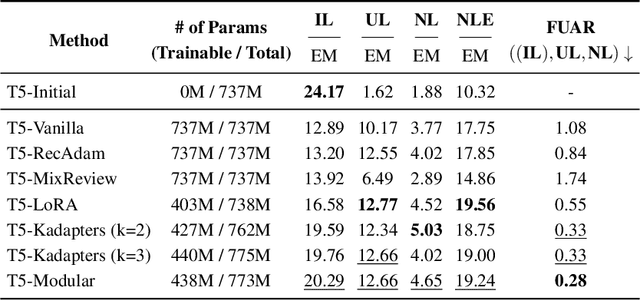
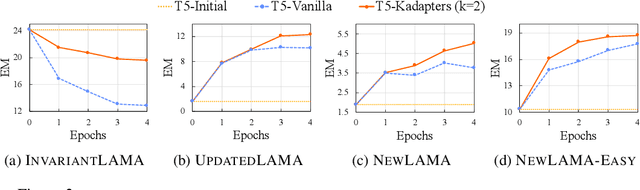
Large Language Models (LMs) are known to encode world knowledge in their parameters as they pretrain on a vast amount of web corpus, which is often utilized for performing knowledge-dependent downstream tasks such as question answering, fact-checking, and open dialogue. In real-world scenarios, the world knowledge stored in the LMs can quickly become outdated as the world changes, but it is non-trivial to avoid catastrophic forgetting and reliably acquire new knowledge while preserving invariant knowledge. To push the community towards better maintenance of ever-changing LMs, we formulate a new continual learning (CL) problem called Continual Knowledge Learning (CKL). We construct a new benchmark and metric to quantify the retention of time-invariant world knowledge, the update of outdated knowledge, and the acquisition of new knowledge. We adopt applicable recent methods from literature to create several strong baselines. Through extensive experiments, we find that CKL exhibits unique challenges that are not addressed in previous CL setups, where parameter expansion is necessary to reliably retain and learn knowledge simultaneously. By highlighting the critical causes of knowledge forgetting, we show that CKL is a challenging and important problem that helps us better understand and train ever-changing LMs. The benchmark datasets, evaluation script, and baseline code to reproduce our results are available at https://github.com/joeljang/continual-knowledge-learning.
Designing a Minimal Retrieve-and-Read System for Open-Domain Question Answering
Apr 15, 2021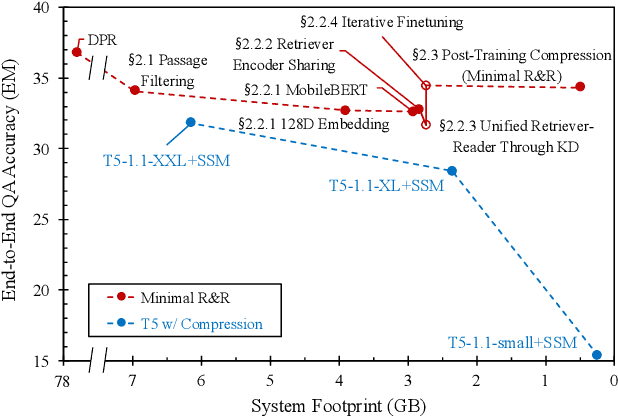
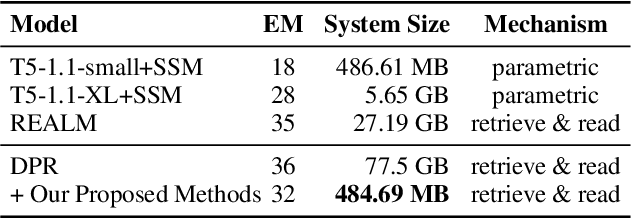
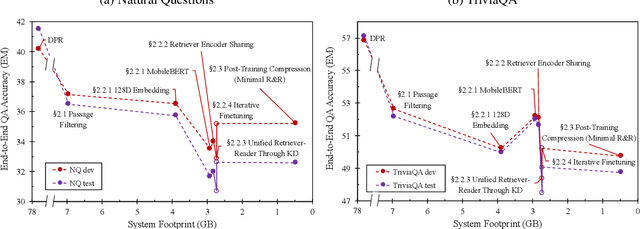
In open-domain question answering (QA), retrieve-and-read mechanism has the inherent benefit of interpretability and the easiness of adding, removing, or editing knowledge compared to the parametric approaches of closed-book QA models. However, it is also known to suffer from its large storage footprint due to its document corpus and index. Here, we discuss several orthogonal strategies to drastically reduce the footprint of a retrieve-and-read open-domain QA system by up to 160x. Our results indicate that retrieve-and-read can be a viable option even in a highly constrained serving environment such as edge devices, as we show that it can achieve better accuracy than a purely parametric model with comparable docker-level system size.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021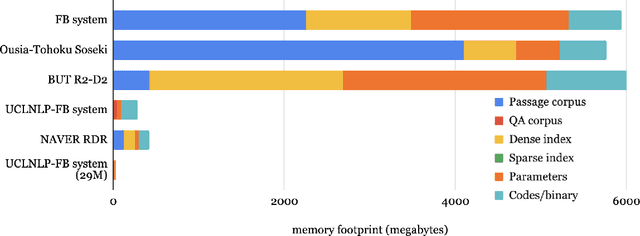
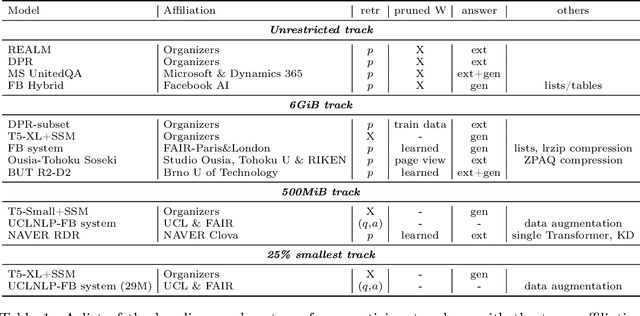
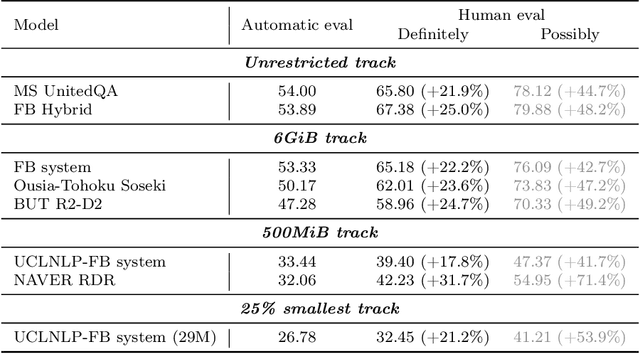
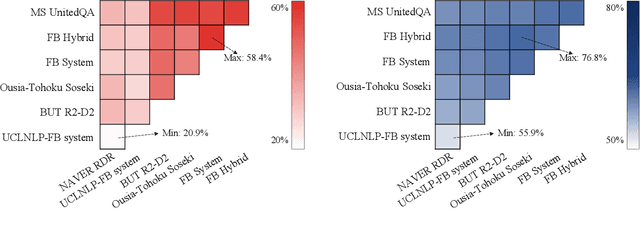
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Is Retriever Merely an Approximator of Reader?
Oct 21, 2020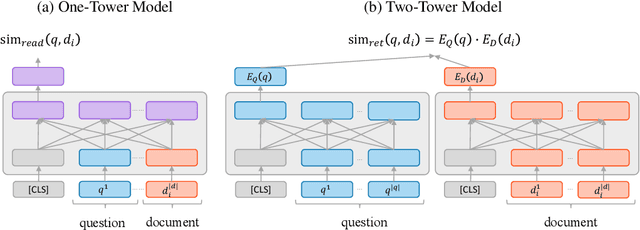
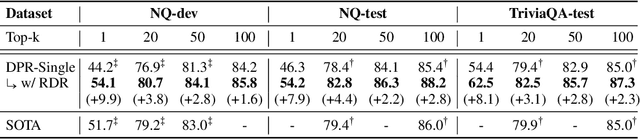
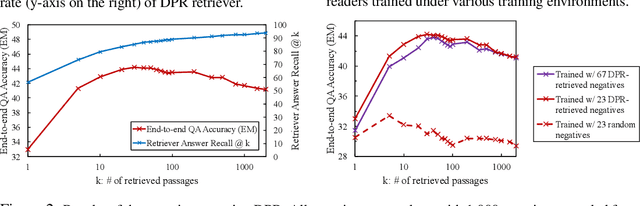
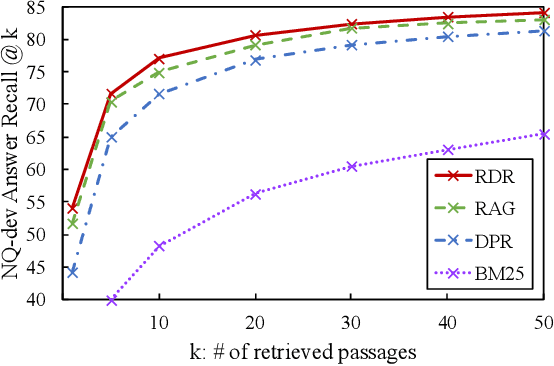
The state of the art in open-domain question answering (QA) relies on an efficient retriever that drastically reduces the search space for the expensive reader. A rather overlooked question in the community is the relationship between the retriever and the reader, and in particular, if the whole purpose of the retriever is just a fast approximation for the reader. Our empirical evidence indicates that the answer is no, and that the reader and the retriever are complementary to each other even in terms of accuracy only. We make a careful conjecture that the architectural constraint of the retriever, which has been originally intended for enabling approximate search, seems to also make the model more robust in large-scale search. We then propose to distill the reader into the retriever so that the retriever absorbs the strength of the reader while keeping its own benefit. Experimental results show that our method can enhance the document recall rate as well as the end-to-end QA accuracy of off-the-shelf retrievers in open-domain QA tasks.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
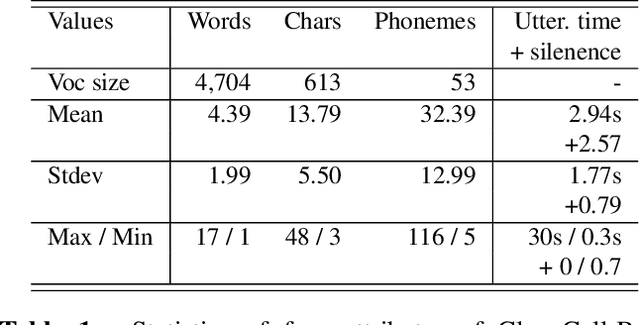
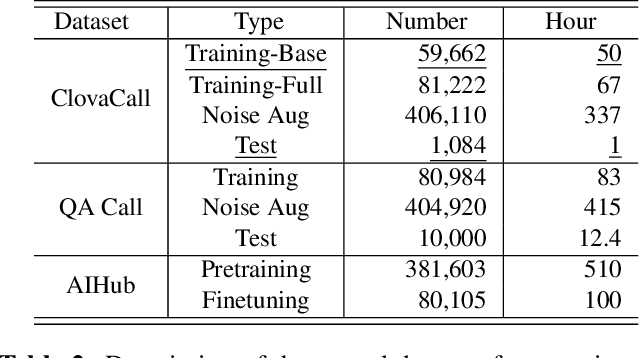
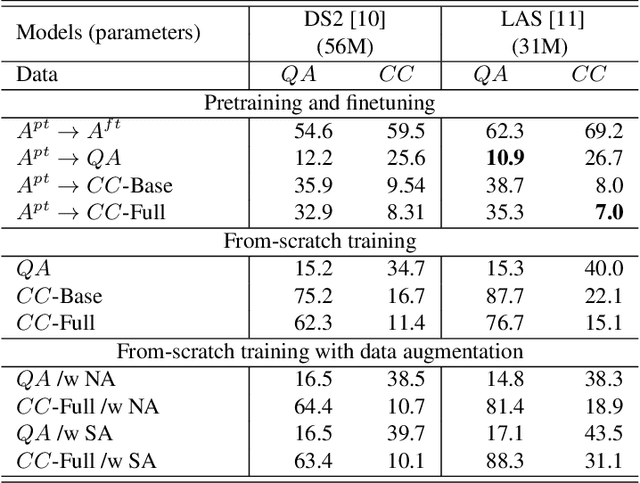
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.