 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Task Symmetry Drives Generalization in Algorithmic Tasks
Mar 02, 2026Grokking, the sudden transition from memorization to generalization, is characterized by the emergence of low-dimensional representations, yet the mechanism underlying this organization remains elusive. We propose that intrinsic task symmetries primarily drive grokking and shape the geometry of the model's representation space. We identify a consistent three-stage training dynamic underlying grokking: (i) memorization, (ii) symmetry acquisition, and (iii) geometric organization. We show that generalization emerges during the symmetry acquisition phase, after which representations reorganize into a structured, task-aligned geometry. We validate this symmetry-driven account across diverse algorithmic domains, including algebraic, structural, and relational reasoning tasks. Building on these findings, we introduce a symmetry-based diagnostic that anticipates the onset of generalization and propose strategies to accelerate it. Together, our results establish intrinsic symmetry as the key factor enabling neural networks to move beyond memorization and achieve robust algorithmic reasoning.
Understanding Human Perception of Music Plagiarism Through a Computational Approach
Jan 05, 2026There is a wide variety of music similarity detection algorithms, while discussions about music plagiarism in the real world are often based on audience perceptions. Therefore, we aim to conduct a study to examine the key criteria of human perception of music plagiarism, focusing on the three commonly used musical features in similarity analysis: melody, rhythm, and chord progression. After identifying the key features and levels of variation humans use in perceiving musical similarity, we propose a LLM-as-a-judge framework that applies a systematic, step-by-step approach, drawing on modules that extract such high-level attributes.
Differential Information: An Information-Theoretic Perspective on Preference Optimization
May 29, 2025



Direct Preference Optimization (DPO) has become a standard technique for aligning language models with human preferences in a supervised manner. Despite its empirical success, the theoretical justification behind its log-ratio reward parameterization remains incomplete. In this work, we address this gap by utilizing the Differential Information Distribution (DID): a distribution over token sequences that captures the information gained during policy updates. First, we show that when preference labels encode the differential information required to transform a reference policy into a target policy, the log-ratio reward in DPO emerges as the uniquely optimal form for learning the target policy via preference optimization. This result naturally yields a closed-form expression for the optimal sampling distribution over rejected responses. Second, we find that the condition for preferences to encode differential information is fundamentally linked to an implicit assumption regarding log-margin ordered policies-an inductive bias widely used in preference optimization yet previously unrecognized. Finally, by analyzing the entropy of the DID, we characterize how learning low-entropy differential information reinforces the policy distribution, while high-entropy differential information induces a smoothing effect, which explains the log-likelihood displacement phenomenon. We validate our theoretical findings in synthetic experiments and extend them to real-world instruction-following datasets. Our results suggest that learning high-entropy differential information is crucial for general instruction-following, while learning low-entropy differential information benefits knowledge-intensive question answering. Overall, our work presents a unifying perspective on the DPO objective, the structure of preference data, and resulting policy behaviors through the lens of differential information.
Let's Predict Sentence by Sentence
May 28, 2025



Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
The Coverage Principle: A Framework for Understanding Compositional Generalization
May 26, 2025Large language models excel at pattern matching, yet often fall short in systematic compositional generalization. We propose the coverage principle: a data-centric framework showing that models relying primarily on pattern matching for compositional tasks cannot reliably generalize beyond substituting fragments that yield identical results when used in the same contexts. We demonstrate that this framework has a strong predictive power for the generalization capabilities of Transformers. First, we derive and empirically confirm that the training data required for two-hop generalization grows at least quadratically with the token set size, and the training data efficiency does not improve with 20x parameter scaling. Second, for compositional tasks with path ambiguity where one variable affects the output through multiple computational paths, we show that Transformers learn context-dependent state representations that undermine both performance and interoperability. Third, Chain-of-Thought supervision improves training data efficiency for multi-hop tasks but still struggles with path ambiguity. Finally, we outline a \emph{mechanism-based} taxonomy that distinguishes three ways neural networks can generalize: structure-based (bounded by coverage), property-based (leveraging algebraic invariances), and shared-operator (through function reuse). This conceptual lens contextualizes our results and highlights where new architectural ideas are needed to achieve systematic compositionally. Overall, the coverage principle provides a unified lens for understanding compositional reasoning, and underscores the need for fundamental architectural or training innovations to achieve truly systematic compositionality.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025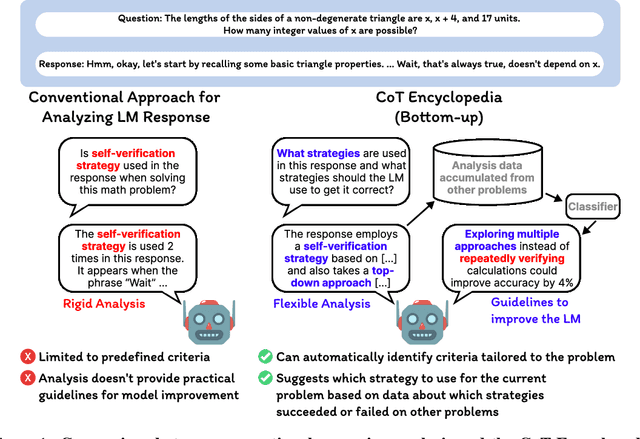
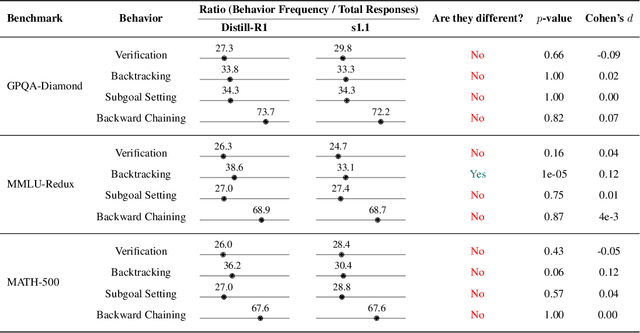
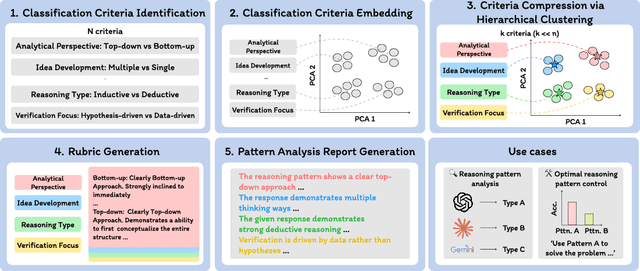

Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
Knowledge Entropy Decay during Language Model Pretraining Hinders New Knowledge Acquisition
Oct 02, 2024



In this work, we investigate how a model's tendency to broadly integrate its parametric knowledge evolves throughout pretraining, and how this behavior affects overall performance, particularly in terms of knowledge acquisition and forgetting. We introduce the concept of knowledge entropy, which quantifies the range of memory sources the model engages with; high knowledge entropy indicates that the model utilizes a wide range of memory sources, while low knowledge entropy suggests reliance on specific sources with greater certainty. Our analysis reveals a consistent decline in knowledge entropy as pretraining advances. We also find that the decline is closely associated with a reduction in the model's ability to acquire and retain knowledge, leading us to conclude that diminishing knowledge entropy (smaller number of active memory sources) impairs the model's knowledge acquisition and retention capabilities. We find further support for this by demonstrating that increasing the activity of inactive memory sources enhances the model's capacity for knowledge acquisition and retention.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Apr 16, 2024



Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets
Jul 20, 2023



Evaluation of Large Language Models (LLMs) is challenging because aligning to human values requires the composition of multiple skills and the required set of skills varies depending on the instruction. Recent studies have evaluated the performance of LLMs in two ways, (1) automatic evaluation on several independent benchmarks and (2) human or machined-based evaluation giving an overall score to the response. However, both settings are coarse-grained evaluations, not considering the nature of user instructions that require instance-wise skill composition, which limits the interpretation of the true capabilities of LLMs. In this paper, we introduce FLASK (Fine-grained Language Model Evaluation based on Alignment SKill Sets), a fine-grained evaluation protocol that can be used for both model-based and human-based evaluation which decomposes coarse-level scoring to an instance-wise skill set-level. Specifically, we define 12 fine-grained skills needed for LLMs to follow open-ended user instructions and construct an evaluation set by allocating a set of skills for each instance. Additionally, by annotating the target domains and difficulty level for each instance, FLASK provides a holistic view with a comprehensive analysis of a model's performance depending on skill, domain, and difficulty. Through using FLASK, we compare multiple open-sourced and proprietary LLMs and observe highly-correlated findings between model-based and human-based evaluations. FLASK enables developers to more accurately measure the model performance and how it can be improved by analyzing factors that make LLMs proficient in particular skills. For practitioners, FLASK can be used to recommend suitable models for particular situations through comprehensive comparison among various LLMs. We release the evaluation data and code implementation at https://github.com/kaistAI/FLASK.