 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Adjustment of Matching Radii under the Broadcasting Mode: A Novel Multitask Learning Strategy and Temporal Modeling Approach
Dec 09, 2023As ride-hailing services have experienced significant growth, the majority of research has concentrated on the dispatching mode, where drivers must adhere to the platform's assigned routes. However, the broadcasting mode, in which drivers can freely choose their preferred orders from those broadcast by the platform, has received less attention. One important but challenging task in such a system is the determination of the optimal matching radius, which usually varies across space, time, and real-time supply/demand characteristics. This study develops a Transformer-Encoder-Based (TEB) model that predicts key system performance metrics for a range of matching radii, which enables the ride-hailing platform to select an optimal matching radius that maximizes overall system performance according to real-time supply and demand information. To simultaneously maximize multiple system performance metrics for matching radius determination, we devise a novel multi-task learning algorithm that enhances convergence speed of each task (corresponding to the optimization of one metric) and delivers more accurate overall predictions. We evaluate our methods in a simulation environment specifically designed for broadcasting-mode-based ride-hailing service. Our findings reveal that dynamically adjusting matching radii based on our proposed predict-then-optimize approach significantly improves system performance, e.g., increasing platform revenue by 7.55% and enhancing order fulfillment rate by 13% compared to benchmark algorithms.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023



We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
Efficient Neural Music Generation
May 25, 2023



Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
Language-universal phonetic encoder for low-resource speech recognition
May 19, 2023



Multilingual training is effective in improving low-resource ASR, which may partially be explained by phonetic representation sharing between languages. In end-to-end (E2E) ASR systems, graphemes are often used as basic modeling units, however graphemes may not be ideal for multilingual phonetic sharing. In this paper, we leverage International Phonetic Alphabet (IPA) based language-universal phonetic model to improve low-resource ASR performances, for the first time within the attention encoder-decoder architecture. We propose an adaptation method on the phonetic IPA model to further improve the proposed approach on extreme low-resource languages. Experiments carried out on the open-source MLS corpus and our internal databases show our approach outperforms baseline monolingual models and most state-of-the-art works. Our main approach and adaptation are effective on extremely low-resource languages, even within domain- and language-mismatched scenarios.
Language-Universal Phonetic Representation in Multilingual Speech Pretraining for Low-Resource Speech Recognition
May 19, 2023



We improve low-resource ASR by integrating the ideas of multilingual training and self-supervised learning. Concretely, we leverage an International Phonetic Alphabet (IPA) multilingual model to create frame-level pseudo labels for unlabeled speech, and use these pseudo labels to guide hidden-unit BERT (HuBERT) based speech pretraining in a phonetically-informed manner. The experiments on the Multilingual Speech (MLS) Corpus show that the proposed approach consistently outperforms the standard HuBERT on all the target languages. Moreover, on 3 of the 4 languages, comparing to the standard HuBERT, the approach performs better, meanwhile is able to save supervised training data by 1.5k hours (75%) at most. Our approach outperforms most of the state of the arts, with much less pretraining data in terms of hours and language diversity. Compared to XLSR-53 and a retraining based multilingual method, our approach performs better with full and limited finetuning data scenarios.
A multi-functional simulation platform for on-demand ride service operations
Mar 22, 2023On-demand ride services or ride-sourcing services have been experiencing fast development in the past decade. Various mathematical models and optimization algorithms have been developed to help ride-sourcing platforms design operational strategies with higher efficiency. However, due to cost and reliability issues (implementing an immature algorithm for real operations may result in system turbulence), it is commonly infeasible to validate these models and train/test these optimization algorithms within real-world ride sourcing platforms. Acting as a useful test bed, a simulation platform for ride-sourcing systems will be very important to conduct algorithm training/testing or model validation through trails and errors. While previous studies have established a variety of simulators for their own tasks, it lacks a fair and public platform for comparing the models or algorithms proposed by different researchers. In addition, the existing simulators still face many challenges, ranging from their closeness to real environments of ride-sourcing systems, to the completeness of different tasks they can implement. To address the challenges, we propose a novel multi-functional and open-sourced simulation platform for ride-sourcing systems, which can simulate the behaviors and movements of various agents on a real transportation network. It provides a few accessible portals for users to train and test various optimization algorithms, especially reinforcement learning algorithms, for a variety of tasks, including on-demand matching, idle vehicle repositioning, and dynamic pricing. In addition, it can be used to test how well the theoretical models approximate the simulated outcomes. Evaluated on real-world data based experiments, the simulator is demonstrated to be an efficient and effective test bed for various tasks related to on-demand ride service operations.
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Mar 10, 2023This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 11 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available.
Cross-City Traffic Prediction via Semantic-Fused Hierarchical Graph Transfer Learning
Feb 23, 2023Accurate traffic prediction benefits urban management and improves transportation efficiency. Recently, data-driven methods have been widely applied in traffic prediction and outperformed traditional methods. However, data-driven methods normally require massive data for training, while data scarcity is ubiquitous in low-developmental or newly constructed regions. To tackle this problem, we can extract meta knowledge from data-rich cities to data-scarce cities via transfer learning. Besides, relations among urban regions can be organized into various semantic graphs, e.g. proximity and POI similarity, which is barely considered in previous studies. In this paper, we propose Semantic-Fused Hierarchical Graph Transfer Learning (SF-HGTL) model to achieve knowledge transfer across cities with fused semantics. In detail, we employ hierarchical graph transformation followed by meta-knowledge retrieval to achieve knowledge transfer in various granularity. In addition, we introduce meta semantic nodes to reduce the number of parameters as well as share information across semantics. Afterwards, the parameters of the base model are generated by fused semantic embeddings to predict traffic status in terms of task heterogeneity. We implement experiments on five real-world datasets and verify the effectiveness of our SF-HGTL model by comparing it with other baselines.
Bag All You Need: Learning a Generalizable Bagging Strategy for Heterogeneous Objects
Oct 18, 2022
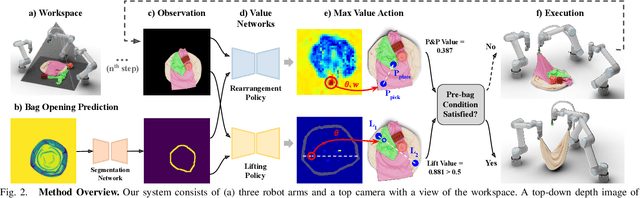
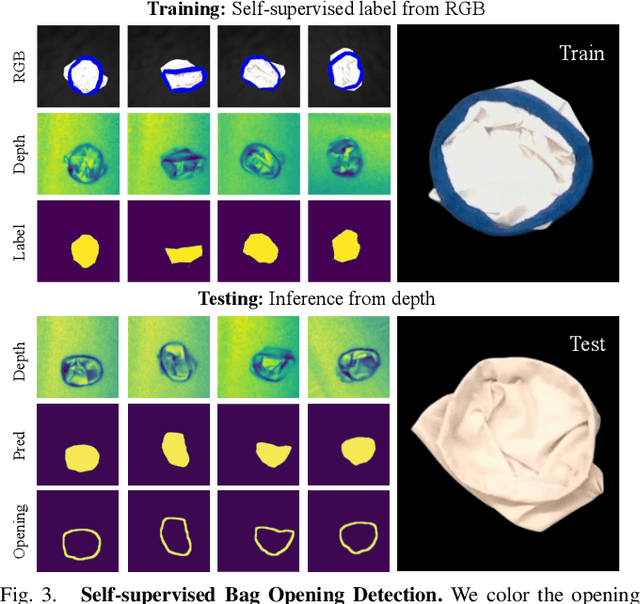
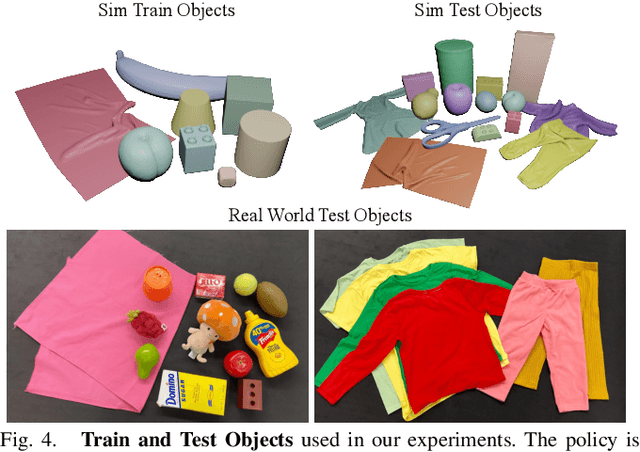
We introduce a practical robotics solution for the task of heterogeneous bagging, requiring the placement of multiple rigid and deformable objects into a deformable bag. This is a difficult task as it features complex interactions between multiple highly deformable objects under limited observability. To tackle these challenges, we propose a robotic system consisting of two learned policies: a rearrangement policy that learns to place multiple rigid objects and fold deformable objects in order to achieve desirable pre-bagging conditions, and a lifting policy to infer suitable grasp points for bi-manual bag lifting. We evaluate these learned policies on a real-world three-arm robot platform that achieves a 70% heterogeneous bagging success rate with novel objects. To facilitate future research and comparison, we also develop a novel heterogeneous bagging simulation benchmark that will be made publicly available.