 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMI-Underwater: Learning Underwater Manipulation without Underwater Teleoperation
Mar 27, 2026Underwater robotic grasping is difficult due to degraded, highly variable imagery and the expense of collecting diverse underwater demonstrations. We introduce a system that (i) autonomously collects successful underwater grasp demonstrations via a self-supervised data collection pipeline and (ii) transfers grasp knowledge from on-land human demonstrations through a depth-based affordance representation that bridges the on-land-to-underwater domain gap and is robust to lighting and color shift. An affordance model trained on on-land handheld demonstrations is deployed underwater zero-shot via geometric alignment, and an affordance-conditioned diffusion policy is then trained on underwater demonstrations to generate control actions. In pool experiments, our approach improves grasping performance and robustness to background shifts, and enables generalization to objects seen only in on-land data, outperforming RGB-only baselines. Code, videos, and additional results are available at https://umi-under-water.github.io.
Self-Improving Autonomous Underwater Manipulation
Oct 24, 2024



Underwater robotic manipulation faces significant challenges due to complex fluid dynamics and unstructured environments, causing most manipulation systems to rely heavily on human teleoperation. In this paper, we introduce AquaBot, a fully autonomous manipulation system that combines behavior cloning from human demonstrations with self-learning optimization to improve beyond human teleoperation performance. With extensive real-world experiments, we demonstrate AquaBot's versatility across diverse manipulation tasks, including object grasping, trash sorting, and rescue retrieval. Our real-world experiments show that AquaBot's self-optimized policy outperforms a human operator by 41% in speed. AquaBot represents a promising step towards autonomous and self-improving underwater manipulation systems. We open-source both hardware and software implementation details.
UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers
Jul 14, 2024



We introduce UMI-on-Legs, a new framework that combines real-world and simulation data for quadruped manipulation systems. We scale task-centric data collection in the real world using a hand-held gripper (UMI), providing a cheap way to demonstrate task-relevant manipulation skills without a robot. Simultaneously, we scale robot-centric data in simulation by training whole-body controller for task-tracking without task simulation setups. The interface between these two policies is end-effector trajectories in the task frame, inferred by the manipulation policy and passed to the whole-body controller for tracking. We evaluate UMI-on-Legs on prehensile, non-prehensile, and dynamic manipulation tasks, and report over 70% success rate on all tasks. Lastly, we demonstrate the zero-shot cross-embodiment deployment of a pre-trained manipulation policy checkpoint from prior work, originally intended for a fixed-base robot arm, on our quadruped system. We believe this framework provides a scalable path towards learning expressive manipulation skills on dynamic robot embodiments. Please checkout our website for robot videos, code, and data: https://umi-on-legs.github.io
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
PaperBot: Learning to Design Real-World Tools Using Paper
Mar 14, 2024



Paper is a cheap, recyclable, and clean material that is often used to make practical tools. Traditional tool design either relies on simulation or physical analysis, which is often inaccurate and time-consuming. In this paper, we propose PaperBot, an approach that directly learns to design and use a tool in the real world using paper without human intervention. We demonstrated the effectiveness and efficiency of PaperBot on two tool design tasks: 1. learning to fold and throw paper airplanes for maximum travel distance 2. learning to cut paper into grippers that exert maximum gripping force. We present a self-supervised learning framework that learns to perform a sequence of folding, cutting, and dynamic manipulation actions in order to optimize the design and use of a tool. We deploy our system to a real-world two-arm robotic system to solve challenging design tasks that involve aerodynamics (paper airplane) and friction (paper gripper) that are impossible to simulate accurately.
Dynamics-Guided Diffusion Model for Robot Manipulator Design
Feb 23, 2024



We present Dynamics-Guided Diffusion Model, a data-driven framework for generating manipulator geometry designs for a given manipulation task. Instead of training different design models for each task, our approach employs a learned dynamics network shared across tasks. For a new manipulation task, we first decompose it into a collection of individual motion targets which we call target interaction profile, where each individual motion can be modeled by the shared dynamics network. The design objective constructed from the target and predicted interaction profiles provides a gradient to guide the refinement of finger geometry for the task. This refinement process is executed as a classifier-guided diffusion process, where the design objective acts as the classifier guidance. We evaluate our framework on various manipulation tasks, under the sensor-less setting using only an open-loop parallel jaw motion. Our generated designs outperform optimization-based and unguided diffusion baselines relatively by 31.5% and 45.3% on average manipulation success rate. With the ability to generate a design within 0.8 seconds, our framework could facilitate rapid design iteration and enhance the adoption of data-driven approaches for robotic mechanism design.
Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition
Jul 26, 2023We present a framework for robot skill acquisition, which 1) efficiently scale up data generation of language-labelled robot data and 2) effectively distills this data down into a robust multi-task language-conditioned visuo-motor policy. For (1), we use a large language model (LLM) to guide high-level planning, and sampling-based robot planners (e.g. motion or grasp samplers) for generating diverse and rich manipulation trajectories. To robustify this data-collection process, the LLM also infers a code-snippet for the success condition of each task, simultaneously enabling the data-collection process to detect failure and retry as well as the automatic labeling of trajectories with success/failure. For (2), we extend the diffusion policy single-task behavior-cloning approach to multi-task settings with language conditioning. Finally, we propose a new multi-task benchmark with 18 tasks across five domains to test long-horizon behavior, common-sense reasoning, tool-use, and intuitive physics. We find that our distilled policy successfully learned the robust retrying behavior in its data collection policy, while improving absolute success rates by 34.8% on average across five domains. The benchmark, code, and qualitative results are on our website https://www.cs.columbia.edu/~huy/scalingup/
Bag All You Need: Learning a Generalizable Bagging Strategy for Heterogeneous Objects
Oct 18, 2022
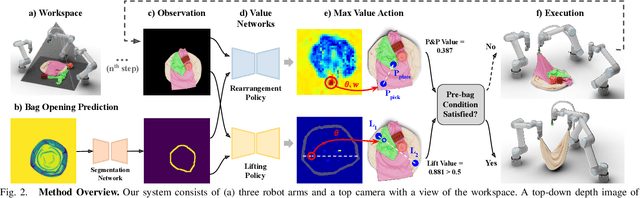
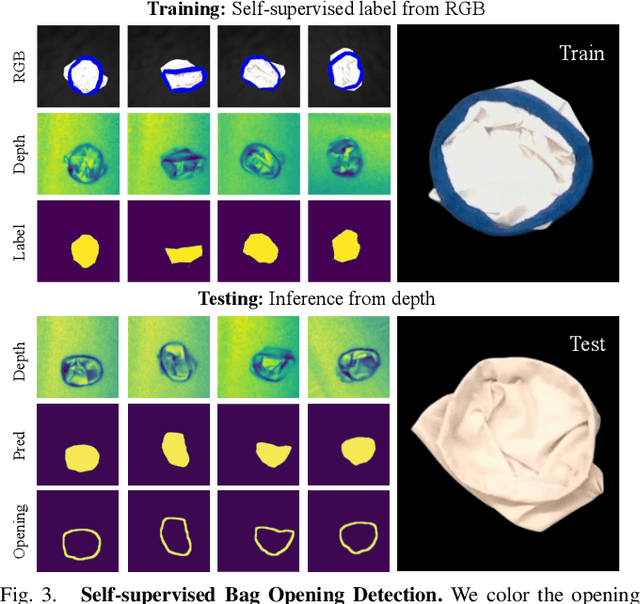
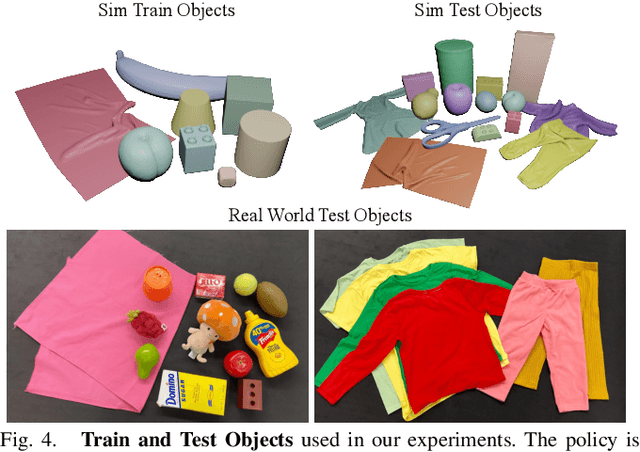
We introduce a practical robotics solution for the task of heterogeneous bagging, requiring the placement of multiple rigid and deformable objects into a deformable bag. This is a difficult task as it features complex interactions between multiple highly deformable objects under limited observability. To tackle these challenges, we propose a robotic system consisting of two learned policies: a rearrangement policy that learns to place multiple rigid objects and fold deformable objects in order to achieve desirable pre-bagging conditions, and a lifting policy to infer suitable grasp points for bi-manual bag lifting. We evaluate these learned policies on a real-world three-arm robot platform that achieves a 70% heterogeneous bagging success rate with novel objects. To facilitate future research and comparison, we also develop a novel heterogeneous bagging simulation benchmark that will be made publicly available.
Cloth Funnels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation
Oct 17, 2022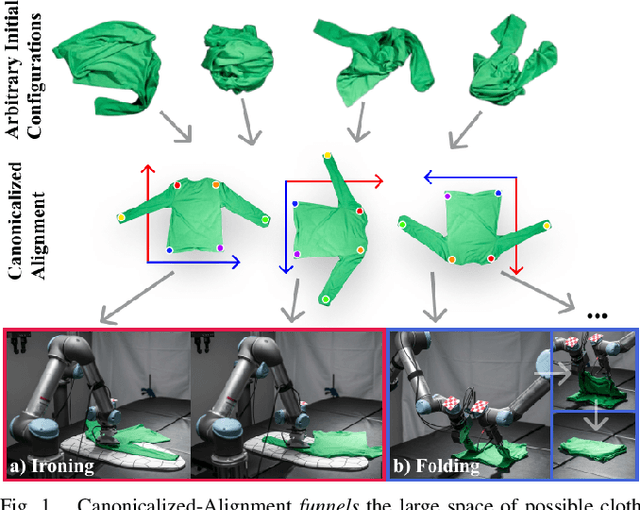
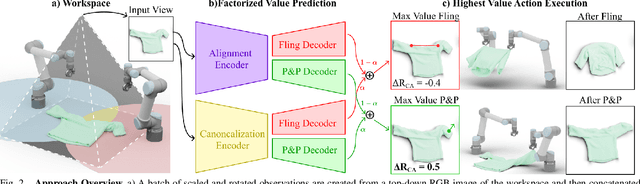
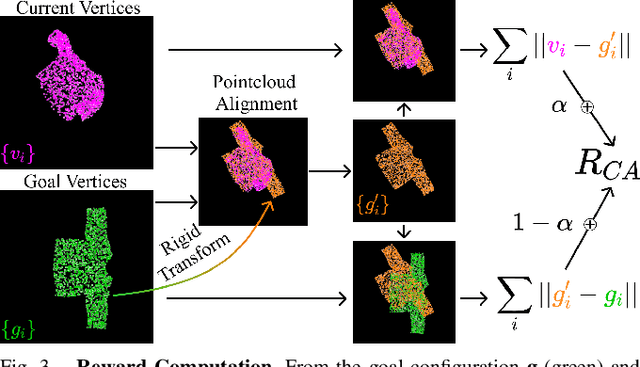
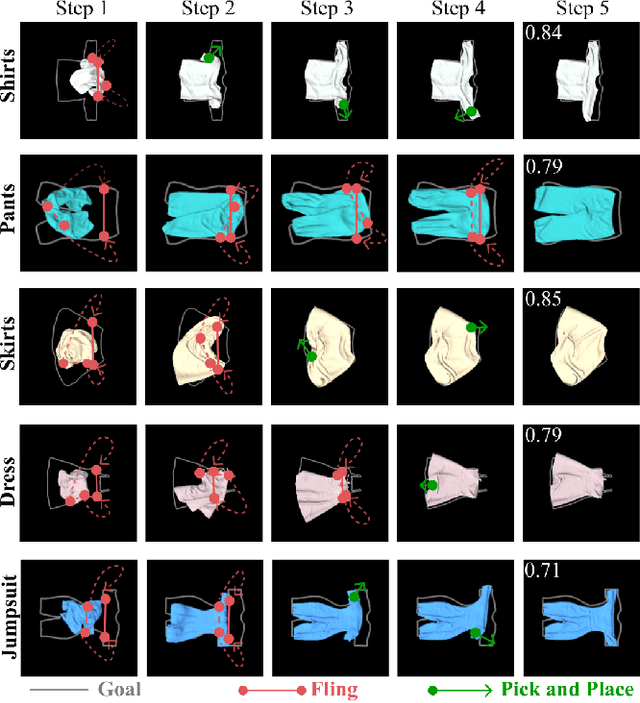
Automating garment manipulation is challenging due to extremely high variability in object configurations. To reduce this intrinsic variation, we introduce the task of "canonicalized-alignment" that simplifies downstream applications by reducing the possible garment configurations. This task can be considered as "cloth state funnel" that manipulates arbitrarily configured clothing items into a predefined deformable configuration (i.e. canonicalization) at an appropriate rigid pose (i.e. alignment). In the end, the cloth items will result in a compact set of structured and highly visible configurations - which are desirable for downstream manipulation skills. To enable this task, we propose a novel canonicalized-alignment objective that effectively guides learning to avoid adverse local minima during learning. Using this objective, we learn a multi-arm, multi-primitive policy that strategically chooses between dynamic flings and quasi-static pick and place actions to achieve efficient canonicalized-alignment. We evaluate this approach on a real-world ironing and folding system that relies on this learned policy as the common first step. Empirically, we demonstrate that our task-agnostic canonicalized-alignment can enable even simple manually-designed policies to work well where they were previously inadequate, thus bridging the gap between automated non-deformable manufacturing and deformable manipulation. Code and qualitative visualizations are available at https://clothfunnels.cs.columbia.edu/. Video can be found at https://www.youtube.com/watch?v=TkUn0b7mbj0.
Semantic Abstraction: Open-World 3D Scene Understanding from 2D Vision-Language Models
Jul 23, 2022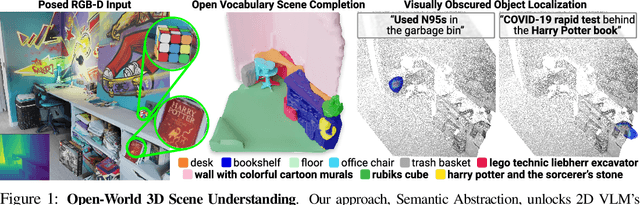
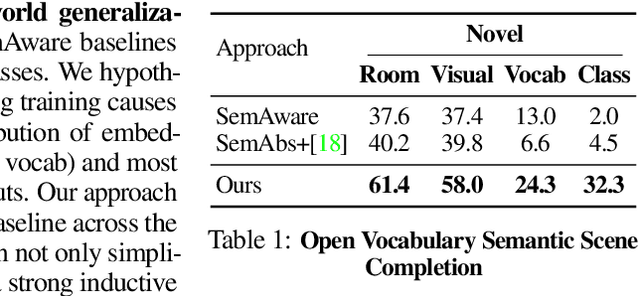
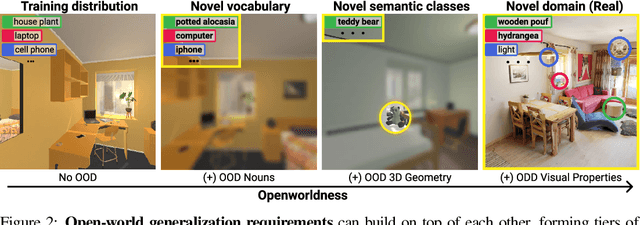
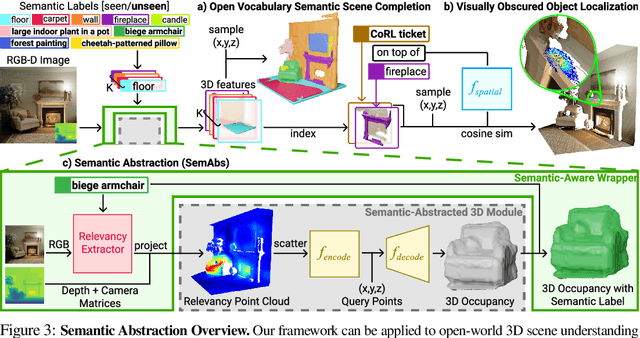
We study open-world 3D scene understanding, a family of tasks that require agents to reason about their 3D environment with an open-set vocabulary and out-of-domain visual inputs - a critical skill for robots to operate in the unstructured 3D world. Towards this end, we propose Semantic Abstraction (SemAbs), a framework that equips 2D Vision-Language Models (VLMs) with new 3D spatial capabilities, while maintaining their zero-shot robustness. We achieve this abstraction using relevancy maps extracted from CLIP, and learn 3D spatial and geometric reasoning skills on top of those abstractions in a semantic-agnostic manner. We demonstrate the usefulness of SemAbs on two open-world 3D scene understanding tasks: 1) completing partially observed objects and 2) localizing hidden objects from language descriptions. Experiments show that SemAbs can generalize to novel vocabulary, materials/lighting, classes, and domains (i.e., real-world scans) from training on limited 3D synthetic data. Code and data will be available at https://semantic-abstraction.cs.columbia.edu/