 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Power of Multitask Representation Learning in Linear MDP
Jun 15, 2021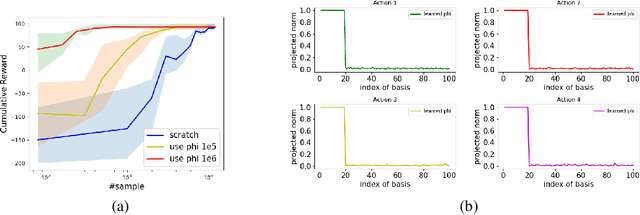
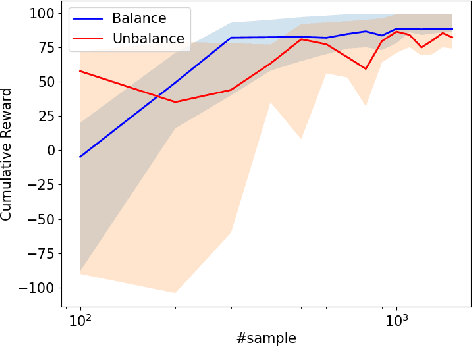
While multitask representation learning has become a popular approach in reinforcement learning (RL), theoretical understanding of why and when it works remains limited. This paper presents analyses for the statistical benefit of multitask representation learning in linear Markov Decision Process (MDP) under a generative model. In this paper, we consider an agent to learn a representation function $\phi$ out of a function class $\Phi$ from $T$ source tasks with $N$ data per task, and then use the learned $\hat{\phi}$ to reduce the required number of sample for a new task. We first discover a \emph{Least-Activated-Feature-Abundance} (LAFA) criterion, denoted as $\kappa$, with which we prove that a straightforward least-square algorithm learns a policy which is $\tilde{O}(H^2\sqrt{\frac{\mathcal{C}(\Phi)^2 \kappa d}{NT}+\frac{\kappa d}{n}})$ sub-optimal. Here $H$ is the planning horizon, $\mathcal{C}(\Phi)$ is $\Phi$'s complexity measure, $d$ is the dimension of the representation (usually $d\ll \mathcal{C}(\Phi)$) and $n$ is the number of samples for the new task. Thus the required $n$ is $O(\kappa d H^4)$ for the sub-optimality to be close to zero, which is much smaller than $O(\mathcal{C}(\Phi)^2\kappa d H^4)$ in the setting without multitask representation learning, whose sub-optimality gap is $\tilde{O}(H^2\sqrt{\frac{\kappa \mathcal{C}(\Phi)^2d}{n}})$. This theoretically explains the power of multitask representation learning in reducing sample complexity. Further, we note that to ensure high sample efficiency, the LAFA criterion $\kappa$ should be small. In fact, $\kappa$ varies widely in magnitude depending on the different sampling distribution for new task. This indicates adaptive sampling technique is important to make $\kappa$ solely depend on $d$. Finally, we provide empirical results of a noisy grid-world environment to corroborate our theoretical findings.
Provable Adaptation across Multiway Domains via Representation Learning
Jun 12, 2021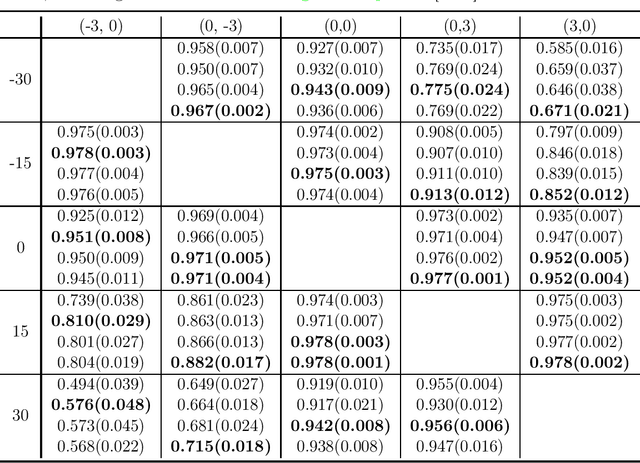
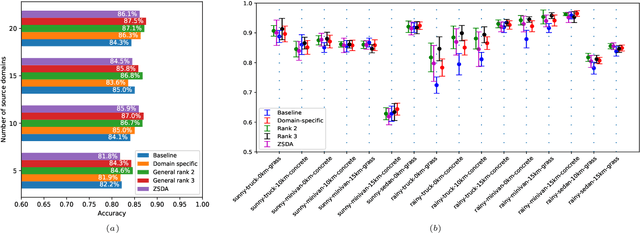
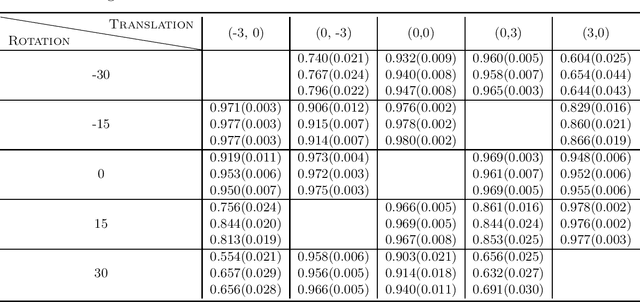
This paper studies zero-shot domain adaptation where each domain is indexed on a multi-dimensional array, and we only have data from a small subset of domains. Our goal is to produce predictors that perform well on \emph{unseen} domains. We propose a model which consists of a domain-invariant latent representation layer and a domain-specific linear prediction layer with a low-rank tensor structure. Theoretically, we present explicit sample complexity bounds to characterize the prediction error on unseen domains in terms of the number of domains with training data and the number of data per domain. To our knowledge, this is the first finite-sample guarantee for zero-shot domain adaptation. In addition, we provide experiments on two-way MNIST and four-way fiber sensing datasets to demonstrate the effectiveness of our proposed model.
Stochastic Shortest Path: Minimax, Parameter-Free and Towards Horizon-Free Regret
Apr 22, 2021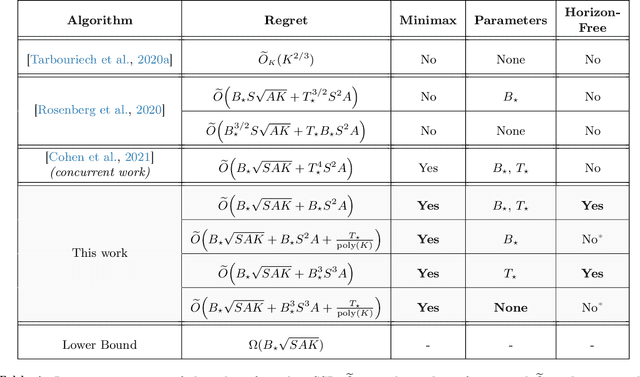
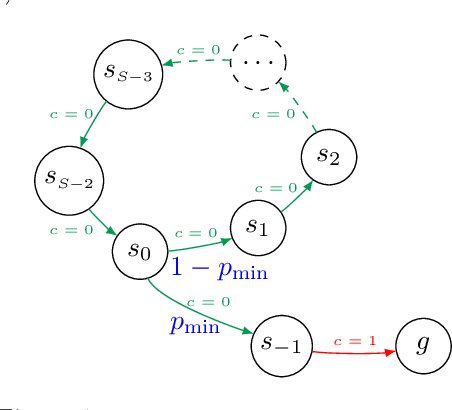
We study the problem of learning in the stochastic shortest path (SSP) setting, where an agent seeks to minimize the expected cost accumulated before reaching a goal state. We design a novel model-based algorithm EB-SSP that carefully skews the empirical transitions and perturbs the empirical costs with an exploration bonus to guarantee both optimism and convergence of the associated value iteration scheme. We prove that EB-SSP achieves the minimax regret rate $\widetilde{O}(B_{\star} \sqrt{S A K})$, where $K$ is the number of episodes, $S$ is the number of states, $A$ is the number of actions and $B_{\star}$ bounds the expected cumulative cost of the optimal policy from any state, thus closing the gap with the lower bound. Interestingly, EB-SSP obtains this result while being parameter-free, i.e., it does not require any prior knowledge of $B_{\star}$, nor of $T_{\star}$ which bounds the expected time-to-goal of the optimal policy from any state. Furthermore, we illustrate various cases (e.g., positive costs, or general costs when an order-accurate estimate of $T_{\star}$ is available) where the regret only contains a logarithmic dependence on $T_{\star}$, thus yielding the first horizon-free regret bound beyond the finite-horizon MDP setting.
Nearly Horizon-Free Offline Reinforcement Learning
Mar 25, 2021
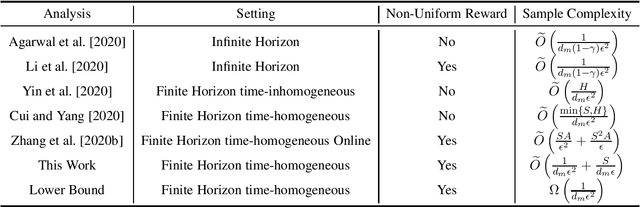
We revisit offline reinforcement learning on episodic time-homogeneous tabular Markov Decision Processes with $S$ states, $A$ actions and planning horizon $H$. Given the collected $N$ episodes data with minimum cumulative reaching probability $d_m$, we obtain the first set of nearly $H$-free sample complexity bounds for evaluation and planning using the empirical MDPs: 1.For the offline evaluation, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} \right)$ error rate, which matches the lower bound and does not have additional dependency on $\poly\left(S,A\right)$ in higher-order term, that is different from previous works~\citep{yin2020near,yin2020asymptotically}. 2.For the offline policy optimization, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} + \frac{S}{Nd_m}\right)$ error rate, improving upon the best known result by \cite{cui2020plug}, which has additional $H$ and $S$ factors in the main term. Furthermore, this bound approaches the $\Omega\left(\sqrt{\frac{1}{Nd_m}}\right)$ lower bound up to logarithmic factors and a high-order term. To the best of our knowledge, these are the first set of nearly horizon-free bounds in offline reinforcement learning.
Bilinear Classes: A Structural Framework for Provable Generalization in RL
Mar 19, 2021
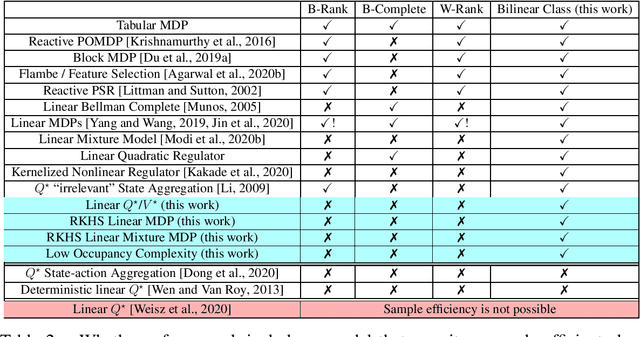
This work introduces Bilinear Classes, a new structural framework, which permit generalization in reinforcement learning in a wide variety of settings through the use of function approximation. The framework incorporates nearly all existing models in which a polynomial sample complexity is achievable, and, notably, also includes new models, such as the Linear $Q^*/V^*$ model in which both the optimal $Q$-function and the optimal $V$-function are linear in some known feature space. Our main result provides an RL algorithm which has polynomial sample complexity for Bilinear Classes; notably, this sample complexity is stated in terms of a reduction to the generalization error of an underlying supervised learning sub-problem. These bounds nearly match the best known sample complexity bounds for existing models. Furthermore, this framework also extends to the infinite dimensional (RKHS) setting: for the the Linear $Q^*/V^*$ model, linear MDPs, and linear mixture MDPs, we provide sample complexities that have no explicit dependence on the explicit feature dimension (which could be infinite), but instead depends only on information theoretic quantities.
Improved Corruption Robust Algorithms for Episodic Reinforcement Learning
Mar 08, 2021We study episodic reinforcement learning under unknown adversarial corruptions in both the rewards and the transition probabilities of the underlying system. We propose new algorithms which, compared to the existing results in (Lykouris et al., 2020), achieve strictly better regret bounds in terms of total corruptions for the tabular setting. To be specific, firstly, our regret bounds depend on more precise numerical values of total rewards corruptions and transition corruptions, instead of only on the total number of corrupted episodes. Secondly, our regret bounds are the first of their kind in the reinforcement learning setting to have the number of corruptions show up additively with respect to $\min\{\sqrt{T}, \text{PolicyGapComplexity}\}$ rather than multiplicatively. Our results follow from a general algorithmic framework that combines corruption-robust policy elimination meta-algorithms, and plug-in reward-free exploration sub-algorithms. Replacing the meta-algorithm or sub-algorithm may extend the framework to address other corrupted settings with potentially more structure.
Variance-Aware Confidence Set: Variance-Dependent Bound for Linear Bandits and Horizon-Free Bound for Linear Mixture MDP
Feb 19, 2021We show how to construct variance-aware confidence sets for linear bandits and linear mixture Markov Decision Process (MDP). Our method yields the following new regret bounds: * For linear bandits, we obtain an $\widetilde{O}(\mathrm{poly}(d)\sqrt{1 + \sum_{i=1}^{K}\sigma_i^2})$ regret bound, where $d$ is the feature dimension, $K$ is the number of rounds, and $\sigma_i^2$ is the (unknown) variance of the reward at the $i$-th round. This is the first regret bound that only scales with the variance and the dimension, with no explicit polynomial dependency on $K$. * For linear mixture MDP, we obtain an $\widetilde{O}(\mathrm{poly}(d, \log H)\sqrt{K})$ regret bound, where $d$ is the number of base models, $K$ is the number of episodes, and $H$ is the planning horizon. This is the first regret bound that only scales logarithmically with $H$ in the reinforcement learning with linear function approximation setting, thus exponentially improving existing results. Our methods utilize three novel ideas that may be of independent interest: 1) applications of the peeling techniques to the norm of input and the magnitude of variance, 2) a recursion-based approach to estimate the variance, and 3) a convex potential lemma that somewhat generalizes the seminal elliptical potential lemma.
Randomized Exploration is Near-Optimal for Tabular MDP
Feb 19, 2021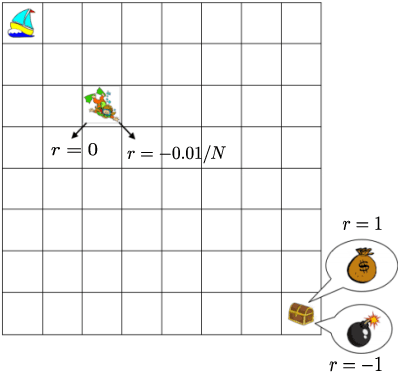
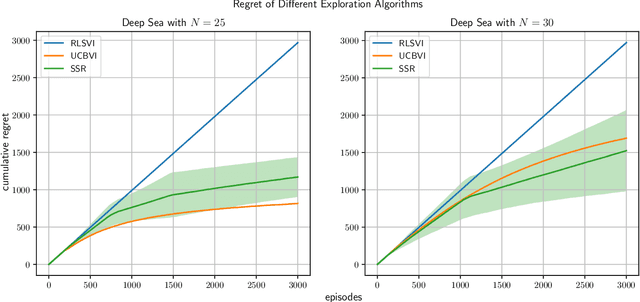
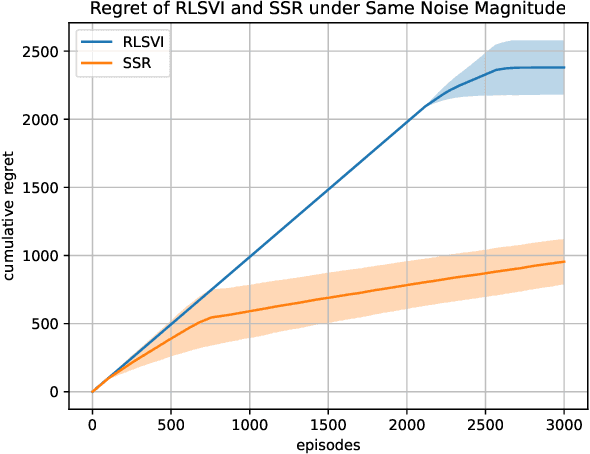
We study exploration using randomized value functions in Thompson Sampling (TS)-like algorithms in reinforcement learning. This type of algorithms enjoys appealing empirical performance. We show that when we use 1) a single random seed in each episode, and 2) a Bernstein-type magnitude of noise, we obtain a worst-case $\widetilde{O}\left(H\sqrt{SAT}\right)$ regret bound for episodic time-inhomogeneous Markov Decision Process where $S$ is the size of state space, $A$ is the size of action space, $H$ is the planning horizon and $T$ is the number of interactions. This bound polynomially improves all existing bounds for TS-like algorithms based on randomized value functions, and for the first time, matches the $\Omega\left(H\sqrt{SAT}\right)$ lower bound up to logarithmic factors. Our result highlights that randomized exploration can be near-optimal, which was previously only achieved by optimistic algorithms.
Provably Efficient Policy Gradient Methods for Two-Player Zero-Sum Markov Games
Feb 17, 2021Policy gradient methods are widely used in solving two-player zero-sum games to achieve superhuman performance in practice. However, it remains elusive when they can provably find a near-optimal solution and how many samples and iterations are needed. The current paper studies natural extensions of Natural Policy Gradient algorithm for solving two-player zero-sum games where function approximation is used for generalization across states. We thoroughly characterize the algorithms' performance in terms of the number of samples, number of iterations, concentrability coefficients, and approximation error. To our knowledge, this is the first quantitative analysis of policy gradient methods with function approximation for two-player zero-sum Markov games.
Fine-Grained Gap-Dependent Bounds for Tabular MDPs via Adaptive Multi-Step Bootstrap
Feb 09, 2021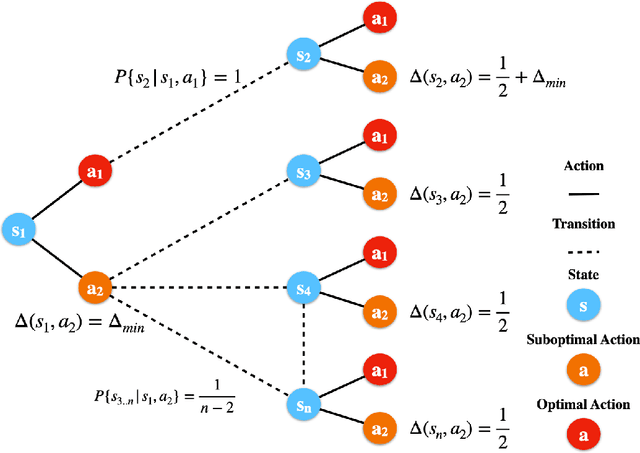
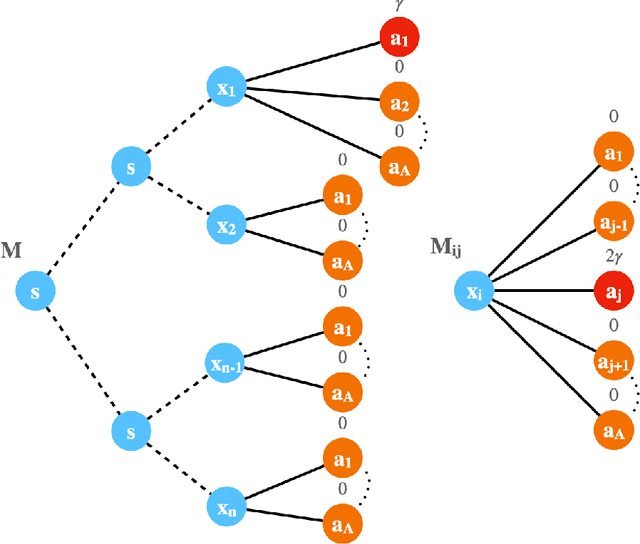
This paper presents a new model-free algorithm for episodic finite-horizon Markov Decision Processes (MDP), Adaptive Multi-step Bootstrap (AMB), which enjoys a stronger gap-dependent regret bound. The first innovation is to estimate the optimal $Q$-function by combining an optimistic bootstrap with an adaptive multi-step Monte Carlo rollout. The second innovation is to select the action with the largest confidence interval length among admissible actions that are not dominated by any other actions. We show when each state has a unique optimal action, AMB achieves a gap-dependent regret bound that only scales with the sum of the inverse of the sub-optimality gaps. In contrast, Simchowitz and Jamieson (2019) showed all upper-confidence-bound (UCB) algorithms suffer an additional $\Omega\left(\frac{S}{\Delta_{min}}\right)$ regret due to over-exploration where $\Delta_{min}$ is the minimum sub-optimality gap and $S$ is the number of states. We further show that for general MDPs, AMB suffers an additional $\frac{|Z_{mul}|}{\Delta_{min}}$ regret, where $Z_{mul}$ is the set of state-action pairs $(s,a)$'s satisfying $a$ is a non-unique optimal action for $s$. We complement our upper bound with a lower bound showing the dependency on $\frac{|Z_{mul}|}{\Delta_{min}}$ is unavoidable for any consistent algorithm. This lower bound also implies a separation between reinforcement learning and contextual bandits.