 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILD: Physics-Informed Learning via Diffusion
Jan 29, 2026Diffusion models have emerged as powerful generative tools for modeling complex data distributions, yet their purely data-driven nature limits applicability in practical engineering and scientific problems where physical laws need to be followed. This paper proposes Physics-Informed Learning via Diffusion (PILD), a framework that unifies diffusion modeling and first-principles physical constraints by introducing a virtual residual observation sampled from a Laplace distribution to supervise generation during training. To further integrate physical laws, a conditional embedding module is incorporated to inject physical information into the denoising network at multiple layers, ensuring consistent guidance throughout the diffusion process. The proposed PILD framework is concise, modular, and broadly applicable to problems governed by ordinary differential equations, partial differential equations, as well as algebraic equations or inequality constraints. Extensive experiments across engineering and scientific tasks including estimating vehicle trajectories, tire forces, Darcy flow and plasma dynamics, demonstrate that our PILD substantially improves accuracy, stability, and generalization over existing physics-informed and diffusion-based baselines.
Plan, Verify and Fill: A Structured Parallel Decoding Approach for Diffusion Language Models
Jan 18, 2026Diffusion Language Models (DLMs) present a promising non-sequential paradigm for text generation, distinct from standard autoregressive (AR) approaches. However, current decoding strategies often adopt a reactive stance, underutilizing the global bidirectional context to dictate global trajectories. To address this, we propose Plan-Verify-Fill (PVF), a training-free paradigm that grounds planning via quantitative validation. PVF actively constructs a hierarchical skeleton by prioritizing high-leverage semantic anchors and employs a verification protocol to operationalize pragmatic structural stopping where further deliberation yields diminishing returns. Extensive evaluations on LLaDA-8B-Instruct and Dream-7B-Instruct demonstrate that PVF reduces the Number of Function Evaluations (NFE) by up to 65% compared to confidence-based parallel decoding across benchmark datasets, unlocking superior efficiency without compromising accuracy.
Diffusion^2: Dual Diffusion Model with Uncertainty-Aware Adaptive Noise for Momentary Trajectory Prediction
Oct 05, 2025



Accurate pedestrian trajectory prediction is crucial for ensuring safety and efficiency in autonomous driving and human-robot interaction scenarios. Earlier studies primarily utilized sufficient observational data to predict future trajectories. However, in real-world scenarios, such as pedestrians suddenly emerging from blind spots, sufficient observational data is often unavailable (i.e. momentary trajectory), making accurate prediction challenging and increasing the risk of traffic accidents. Therefore, advancing research on pedestrian trajectory prediction under extreme scenarios is critical for enhancing traffic safety. In this work, we propose a novel framework termed Diffusion^2, tailored for momentary trajectory prediction. Diffusion^2 consists of two sequentially connected diffusion models: one for backward prediction, which generates unobserved historical trajectories, and the other for forward prediction, which forecasts future trajectories. Given that the generated unobserved historical trajectories may introduce additional noise, we propose a dual-head parameterization mechanism to estimate their aleatoric uncertainty and design a temporally adaptive noise module that dynamically modulates the noise scale in the forward diffusion process. Empirically, Diffusion^2 sets a new state-of-the-art in momentary trajectory prediction on ETH/UCY and Stanford Drone datasets.
SMART: Scalable Multi-Agent Reasoning and Trajectory Planning in Dense Environments
Sep 19, 2025Multi-vehicle trajectory planning is a non-convex problem that becomes increasingly difficult in dense environments due to the rapid growth of collision constraints. Efficient exploration of feasible behaviors and resolution of tight interactions are essential for real-time, large-scale coordination. This paper introduces SMART, Scalable Multi-Agent Reasoning and Trajectory Planning, a hierarchical framework that combines priority-based search with distributed optimization to achieve efficient and feasible multi-vehicle planning. The upper layer explores diverse interaction modes using reinforcement learning-based priority estimation and large-step hybrid A* search, while the lower layer refines solutions via parallelizable convex optimization. By partitioning space among neighboring vehicles and constructing robust feasible corridors, the method decouples the joint non-convex problem into convex subproblems solved efficiently in parallel. This design alleviates the step-size trade-off while ensuring kinematic feasibility and collision avoidance. Experiments show that SMART consistently outperforms baselines. On 50 m x 50 m maps, it sustains over 90% success within 1 s up to 25 vehicles, while baselines often drop below 50%. On 100 m x 100 m maps, SMART achieves above 95% success up to 50 vehicles and remains feasible up to 90 vehicles, with runtimes more than an order of magnitude faster than optimization-only approaches. Built on vehicle-to-everything communication, SMART incorporates vehicle-infrastructure cooperation through roadside sensing and agent coordination, improving scalability and safety. Real-world experiments further validate this design, achieving planning times as low as 0.014 s while preserving cooperative behaviors.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025



Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025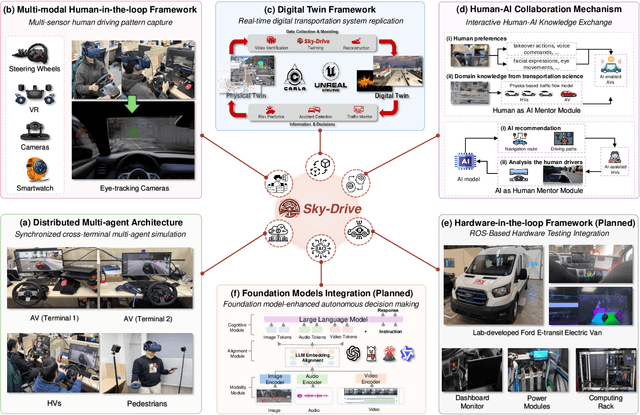
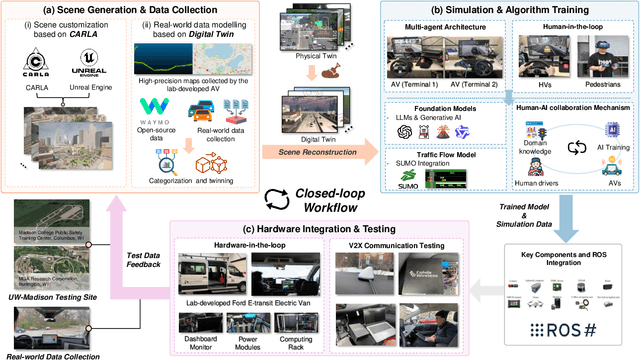
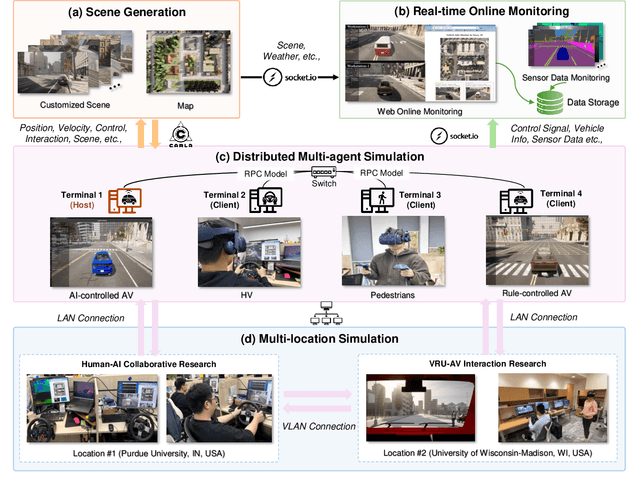
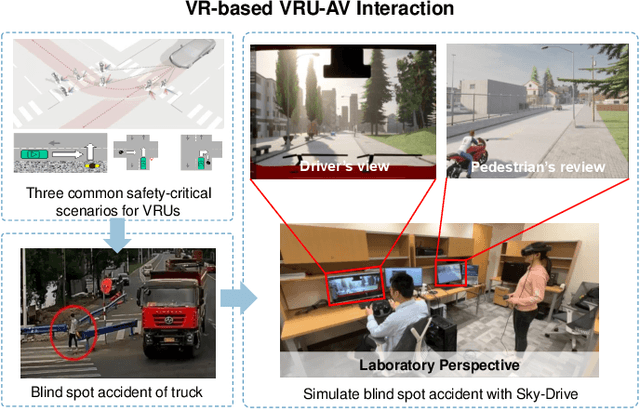
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
Feb 21, 2025



Ensuring safety in autonomous driving systems remains a critical challenge, particularly in handling rare but potentially catastrophic safety-critical scenarios. While existing research has explored generating safety-critical scenarios for autonomous vehicle (AV) testing, there is limited work on effectively incorporating these scenarios into policy learning to enhance safety. Furthermore, developing training curricula that adapt to an AV's evolving behavioral patterns and performance bottlenecks remains largely unexplored. To address these challenges, we propose CurricuVLM, a novel framework that leverages Vision-Language Models (VLMs) to enable personalized curriculum learning for autonomous driving agents. Our approach uniquely exploits VLMs' multimodal understanding capabilities to analyze agent behavior, identify performance weaknesses, and dynamically generate tailored training scenarios for curriculum adaptation. Through comprehensive analysis of unsafe driving situations with narrative descriptions, CurricuVLM performs in-depth reasoning to evaluate the AV's capabilities and identify critical behavioral patterns. The framework then synthesizes customized training scenarios targeting these identified limitations, enabling effective and personalized curriculum learning. Extensive experiments on the Waymo Open Motion Dataset show that CurricuVLM outperforms state-of-the-art baselines across both regular and safety-critical scenarios, achieving superior performance in terms of navigation success, driving efficiency, and safety metrics. Further analysis reveals that CurricuVLM serves as a general approach that can be integrated with various RL algorithms to enhance autonomous driving systems. The code and demo video are available at: https://zihaosheng.github.io/CurricuVLM/.
VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving
Dec 20, 2024



In recent years, reinforcement learning (RL)-based methods for learning driving policies have gained increasing attention in the autonomous driving community and have achieved remarkable progress in various driving scenarios. However, traditional RL approaches rely on manually engineered rewards, which require extensive human effort and often lack generalizability. To address these limitations, we propose \textbf{VLM-RL}, a unified framework that integrates pre-trained Vision-Language Models (VLMs) with RL to generate reward signals using image observation and natural language goals. The core of VLM-RL is the contrasting language goal (CLG)-as-reward paradigm, which uses positive and negative language goals to generate semantic rewards. We further introduce a hierarchical reward synthesis approach that combines CLG-based semantic rewards with vehicle state information, improving reward stability and offering a more comprehensive reward signal. Additionally, a batch-processing technique is employed to optimize computational efficiency during training. Extensive experiments in the CARLA simulator demonstrate that VLM-RL outperforms state-of-the-art baselines, achieving a 10.5\% reduction in collision rate, a 104.6\% increase in route completion rate, and robust generalization to unseen driving scenarios. Furthermore, VLM-RL can seamlessly integrate almost any standard RL algorithms, potentially revolutionizing the existing RL paradigm that relies on manual reward engineering and enabling continuous performance improvements. The demo video and code can be accessed at: https://zilin-huang.github.io/VLM-RL-website.
FollowGen: A Scaled Noise Conditional Diffusion Model for Car-Following Trajectory Prediction
Nov 23, 2024



Vehicle trajectory prediction is crucial for advancing autonomous driving and advanced driver assistance systems (ADAS). Although deep learning-based approaches - especially those utilizing transformer-based and generative models - have markedly improved prediction accuracy by capturing complex, non-linear patterns in vehicle dynamics and traffic interactions, they frequently overlook detailed car-following behaviors and the inter-vehicle interactions critical for real-world driving applications, particularly in fully autonomous or mixed traffic scenarios. To address the issue, this study introduces a scaled noise conditional diffusion model for car-following trajectory prediction, which integrates detailed inter-vehicular interactions and car-following dynamics into a generative framework, improving both the accuracy and plausibility of predicted trajectories. The model utilizes a novel pipeline to capture historical vehicle dynamics by scaling noise with encoded historical features within the diffusion process. Particularly, it employs a cross-attention-based transformer architecture to model intricate inter-vehicle dependencies, effectively guiding the denoising process and enhancing prediction accuracy. Experimental results on diverse real-world driving scenarios demonstrate the state-of-the-art performance and robustness of the proposed method.
Towards 3D Semantic Scene Completion for Autonomous Driving: A Meta-Learning Framework Empowered by Deformable Large-Kernel Attention and Mamba Model
Nov 06, 2024Semantic scene completion (SSC) is essential for achieving comprehensive perception in autonomous driving systems. However, existing SSC methods often overlook the high deployment costs in real-world applications. Traditional architectures, such as 3D Convolutional Neural Networks (3D CNNs) and self-attention mechanisms, face challenges in efficiently capturing long-range dependencies within 3D voxel grids, limiting their effectiveness. To address these issues, we introduce MetaSSC, a novel meta-learning-based framework for SSC that leverages deformable convolution, large-kernel attention, and the Mamba (D-LKA-M) model. Our approach begins with a voxel-based semantic segmentation (SS) pretraining task, aimed at exploring the semantics and geometry of incomplete regions while acquiring transferable meta-knowledge. Using simulated cooperative perception datasets, we supervise the perception training of a single vehicle using aggregated sensor data from multiple nearby connected autonomous vehicles (CAVs), generating richer and more comprehensive labels. This meta-knowledge is then adapted to the target domain through a dual-phase training strategy that does not add extra model parameters, enabling efficient deployment. To further enhance the model's capability in capturing long-sequence relationships within 3D voxel grids, we integrate Mamba blocks with deformable convolution and large-kernel attention into the backbone network. Extensive experiments demonstrate that MetaSSC achieves state-of-the-art performance, significantly outperforming competing models while also reducing deployment costs.