 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real-AD: A Modular Sim-to-Real Framework for Deploying VLM-Guided Reinforcement Learning in Real-World Autonomous Driving
Apr 03, 2026Deploying reinforcement learning policies trained in simulation to real autonomous vehicles remains a fundamental challenge, particularly for VLM-guided RL frameworks whose policies are typically learned with simulator-native observations and simulator-coupled action semantics that are unavailable on physical platforms. This paper presents Sim2Real-AD, a modular framework for zero-shot sim-to-real transfer of CARLA-trained VLM-guided RL policies to full-scale vehicles without any real-world RL training data. The framework decomposes the transfer problem into four components: a Geometric Observation Bridge (GOB) that converts monocular front-view images into simulator-compatible bird's-eye-view (BEV) observations, a Physics-Aware Action Mapping (PAM) that translates policy outputs into platform-agnostic physical commands, a Two-Phase Progressive Training (TPT) strategy that stabilizes adaptation by separating action-space and observation-space transfer, and a Real-time Deployment Pipeline (RDP) that integrates perception, policy inference, control conversion, and safety monitoring for closed-loop execution. Simulation experiments show that the framework preserves the relative performance ordering of representative RL algorithms across different reward paradigms and validate the contribution of each module. Zero-shot deployment on a full-scale Ford E-Transit achieves success rates of 90%, 80%, and 75% in car-following, obstacle avoidance, and stop-sign interaction scenarios, respectively. To the best of our knowledge, this study is among the first to demonstrate zero-shot closed-loop deployment of a CARLA-trained VLM-guided RL policy on a full-scale real vehicle without any real-world RL training data. The demo video and code are available at: https://zilin-huang.github.io/Sim2Real-AD-website/.
DriveVLM-RL: Neuroscience-Inspired Reinforcement Learning with Vision-Language Models for Safe and Deployable Autonomous Driving
Mar 18, 2026Ensuring safe decision-making in autonomous vehicles remains a fundamental challenge despite rapid advances in end-to-end learning approaches. Traditional reinforcement learning (RL) methods rely on manually engineered rewards or sparse collision signals, which fail to capture the rich contextual understanding required for safe driving and make unsafe exploration unavoidable in real-world settings. Recent vision-language models (VLMs) offer promising semantic understanding capabilities; however, their high inference latency and susceptibility to hallucination hinder direct application to real-time vehicle control. To address these limitations, this paper proposes DriveVLM-RL, a neuroscience-inspired framework that integrates VLMs into RL through a dual-pathway architecture for safe and deployable autonomous driving. The framework decomposes semantic reward learning into a Static Pathway for continuous spatial safety assessment using CLIP-based contrasting language goals, and a Dynamic Pathway for attention-gated multi-frame semantic risk reasoning using a lightweight detector and a large VLM. A hierarchical reward synthesis mechanism fuses semantic signals with vehicle states, while an asynchronous training pipeline decouples expensive VLM inference from environment interaction. All VLM components are used only during offline training and are removed at deployment, ensuring real-time feasibility. Experiments in the CARLA simulator show significant improvements in collision avoidance, task success, and generalization across diverse traffic scenarios, including strong robustness under settings without explicit collision penalties. These results demonstrate that DriveVLM-RL provides a practical paradigm for integrating foundation models into autonomous driving without compromising real-time feasibility. Demo video and code are available at: https://zilin-huang.github.io/DriveVLM-RL-website/
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025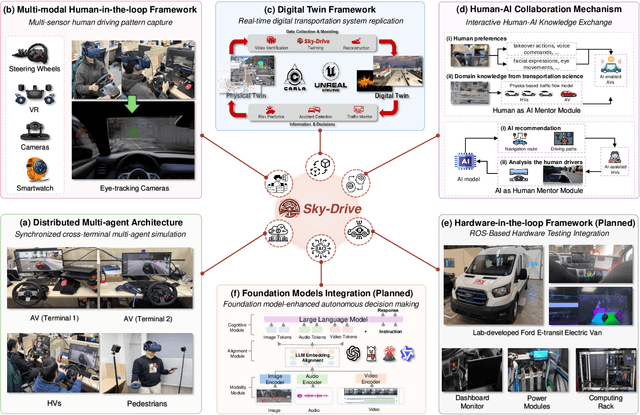
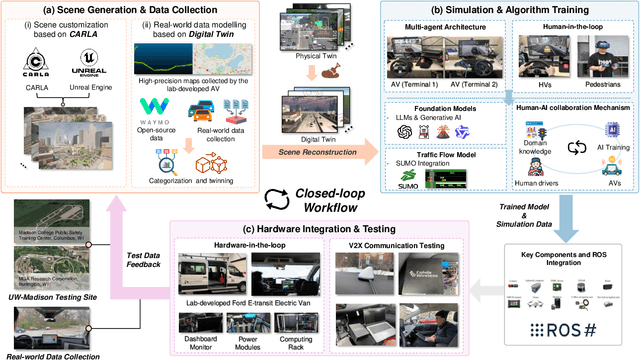
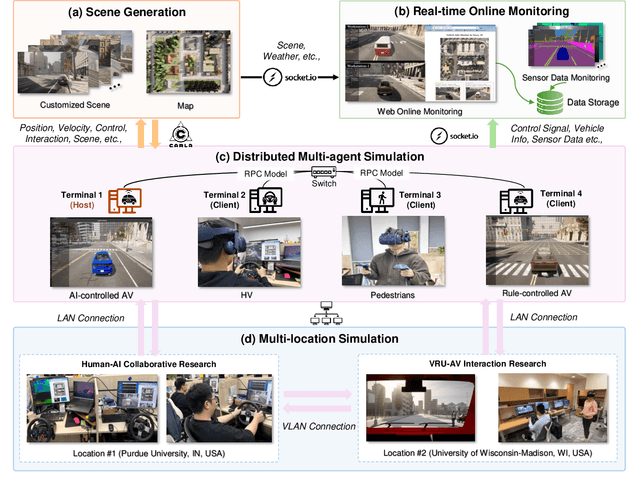
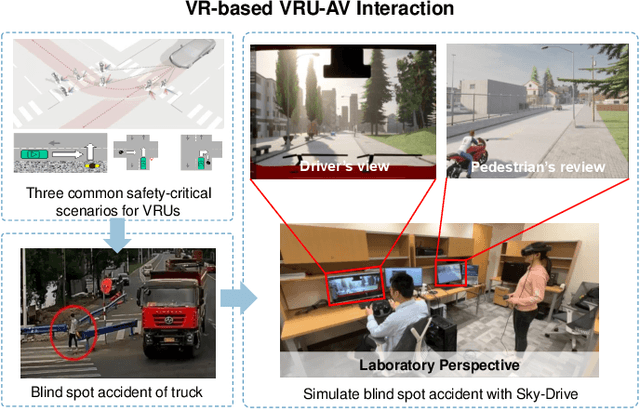
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/