 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Oct 19, 2023



We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
NEWTON: Are Large Language Models Capable of Physical Reasoning?
Oct 10, 2023



Large Language Models (LLMs), through their contextualized representations, have been empirically proven to encapsulate syntactic, semantic, word sense, and common-sense knowledge. However, there has been limited exploration of their physical reasoning abilities, specifically concerning the crucial attributes for comprehending everyday objects. To address this gap, we introduce NEWTON, a repository and benchmark for evaluating the physics reasoning skills of LLMs. Further, to enable domain-specific adaptation of this benchmark, we present a pipeline to enable researchers to generate a variant of this benchmark that has been customized to the objects and attributes relevant for their application. The NEWTON repository comprises a collection of 2800 object-attribute pairs, providing the foundation for generating infinite-scale assessment templates. The NEWTON benchmark consists of 160K QA questions, curated using the NEWTON repository to investigate the physical reasoning capabilities of several mainstream language models across foundational, explicit, and implicit reasoning tasks. Through extensive empirical analysis, our results highlight the capabilities of LLMs for physical reasoning. We find that LLMs like GPT-4 demonstrate strong reasoning capabilities in scenario-based tasks but exhibit less consistency in object-attribute reasoning compared to humans (50% vs. 84%). Furthermore, the NEWTON platform demonstrates its potential for evaluating and enhancing language models, paving the way for their integration into physically grounded settings, such as robotic manipulation. Project site: https://newtonreasoning.github.io
Cherry-Picking with Reinforcement Learning
Mar 09, 2023



Grasping small objects surrounded by unstable or non-rigid material plays a crucial role in applications such as surgery, harvesting, construction, disaster recovery, and assisted feeding. This task is especially difficult when fine manipulation is required in the presence of sensor noise and perception errors; this inevitably triggers dynamic motion, which is challenging to model precisely. Circumventing the difficulty to build accurate models for contacts and dynamics, data-driven methods like reinforcement learning (RL) can optimize task performance via trial and error. Applying these methods to real robots, however, has been hindered by factors such as prohibitively high sample complexity or the high training infrastructure cost for providing resets on hardware. This work presents CherryBot, an RL system that uses chopsticks for fine manipulation that surpasses human reactiveness for some dynamic grasping tasks. By carefully designing the training paradigm and algorithm, we study how to make a real-world robot learning system sample efficient and general while reducing the human effort required for supervision. Our system shows continual improvement through 30 minutes of real-world interaction: through reactive retry, it achieves an almost 100% success rate on the demanding task of using chopsticks to grasp small objects swinging in the air. We demonstrate the reactiveness, robustness and generalizability of CherryBot to varying object shapes and dynamics (e.g., external disturbances like wind and human perturbations). Videos are available at https://goodcherrybot.github.io/.
Lazy Incremental Search for Efficient Replanning with Bounded Suboptimality Guarantees
Oct 23, 2022



We present a lazy incremental search algorithm, Lifelong-GLS (L-GLS), along with its bounded suboptimal version, Bounded L-GLS (B-LGLS) that combine the search efficiency of incremental search algorithms with the evaluation efficiency of lazy search algorithms for fast replanning in problem domains where edge-evaluations are more expensive than vertex-expansions. The proposed algorithms generalize Lifelong Planning A* (LPA*) and its bounded suboptimal version, Truncated LPA* (TLPA*), within the Generalized Lazy Search (GLS) framework, so as to restrict expensive edge evaluations only to the current shortest subpath when the cost-to-come inconsistencies are propagated during repair. We also present dynamic versions of the L-GLS and B-LGLS algorithms, called Generalized D* (GD*) and Bounded Generalized D* (B-GD*), respectively, for efficient replanning with non-stationary queries, designed specifically for navigation of mobile robots. We prove that the proposed algorithms are complete and correct in finding a solution that is guaranteed not to exceed the optimal solution cost by a user-chosen factor. Our numerical and experimental results support the claim that the proposed integration of the incremental and lazy search frameworks can help find solutions faster compared to the regular incremental or regular lazy search algorithms when the underlying graph representation changes often.
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022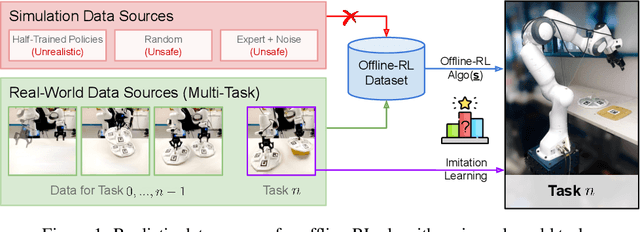

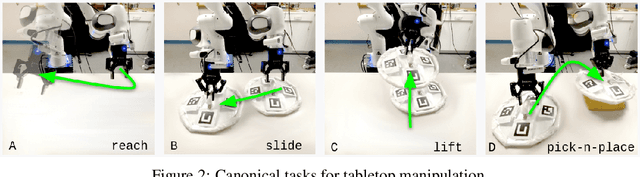
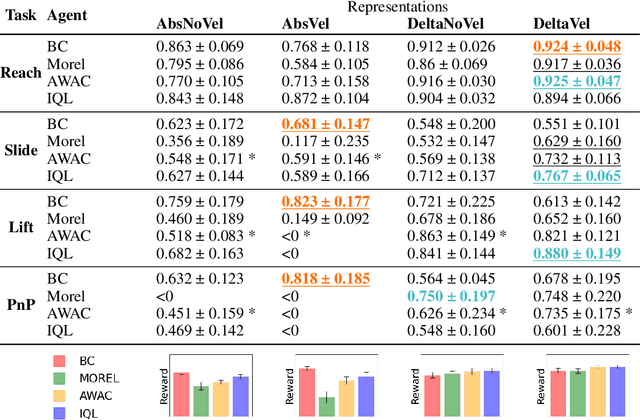
Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl
Git Re-Basin: Merging Models modulo Permutation Symmetries
Sep 11, 2022
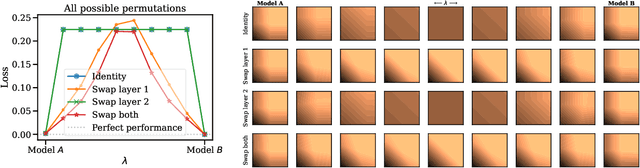

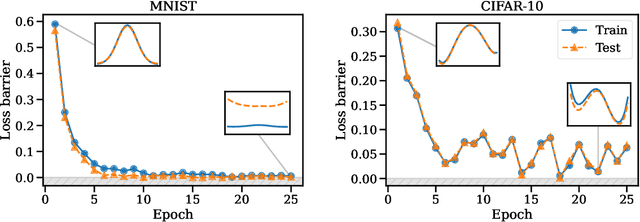
The success of deep learning is thanks to our ability to solve certain massive non-convex optimization problems with relative ease. Despite non-convex optimization being NP-hard, simple algorithms -- often variants of stochastic gradient descent -- exhibit surprising effectiveness in fitting large neural networks in practice. We argue that neural network loss landscapes contain (nearly) a single basin, after accounting for all possible permutation symmetries of hidden units. We introduce three algorithms to permute the units of one model to bring them into alignment with units of a reference model. This transformation produces a functionally equivalent set of weights that lie in an approximately convex basin near the reference model. Experimentally, we demonstrate the single basin phenomenon across a variety of model architectures and datasets, including the first (to our knowledge) demonstration of zero-barrier linear mode connectivity between independently trained ResNet models on CIFAR-10 and CIFAR-100. Additionally, we identify intriguing phenomena relating model width and training time to mode connectivity across a variety of models and datasets. Finally, we discuss shortcomings of a single basin theory, including a counterexample to the linear mode connectivity hypothesis.
Iterative Linear Quadratic Optimization for Nonlinear Control: Differentiable Programming Algorithmic Templates
Jul 13, 2022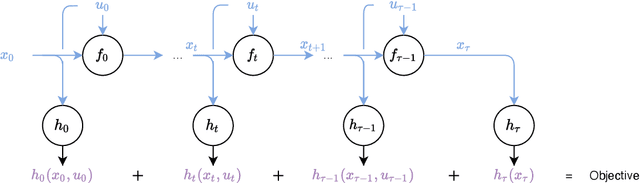


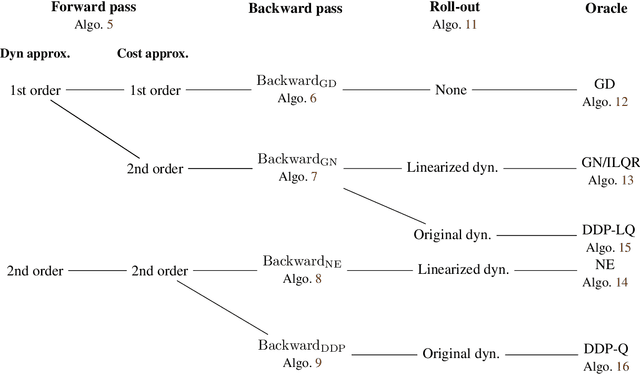
We present the implementation of nonlinear control algorithms based on linear and quadratic approximations of the objective from a functional viewpoint. We present a gradient descent, a Gauss-Newton method, a Newton method, differential dynamic programming approaches with linear quadratic or quadratic approximations, various line-search strategies, and regularized variants of these algorithms. We derive the computational complexities of all algorithms in a differentiable programming framework and present sufficient optimality conditions. We compare the algorithms on several benchmarks, such as autonomous car racing using a bicycle model of a car. The algorithms are coded in a differentiable programming language in a publicly available package.
Electrostatic Brakes Enable Individual Joint Control of Underactuated, Highly Articulated Robots
Apr 05, 2022

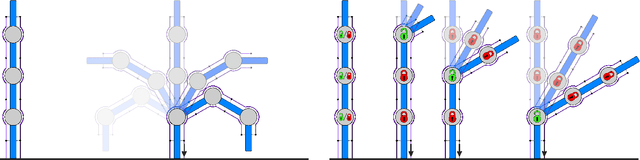
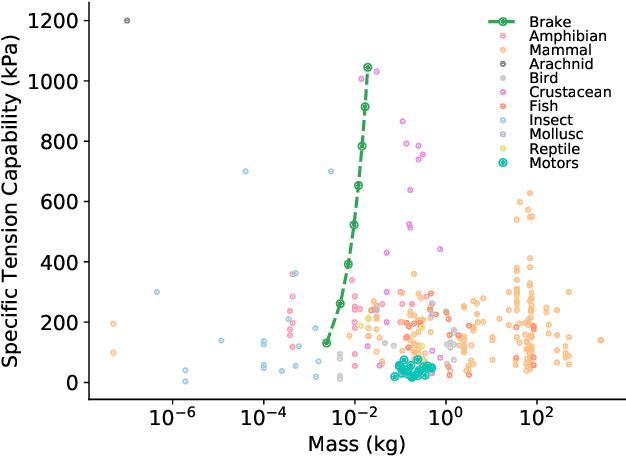
Highly articulated organisms serve as blueprints for incredibly dexterous mechanisms, but building similarly capable robotic counterparts has been hindered by the difficulties of developing electromechanical actuators with both the high strength and compactness of biological muscle. We develop a stackable electrostatic brake that has comparable specific tension and weight to that of muscles and integrate it into a robotic joint. Compared to electromechanical motors, our brake-equipped joint is four times lighter and one thousand times more power efficient while exerting similar holding torques. Our joint design enables a ten degree-of-freedom robot equipped with only one motor to manipulate multiple objects simultaneously. We also show that the use of brakes allows a two-fingered robot to perform in-hand re-positioning of an object 45% more quickly and with 53% lower positioning error than without brakes. Relative to fully actuated robots, our findings suggest that robots equipped with such electrostatic brakes will have lower weight, volume, and power consumption yet retain the ability to reach arbitrary joint configurations.
Balancing Efficiency and Comfort in Robot-Assisted Bite Transfer
Nov 22, 2021
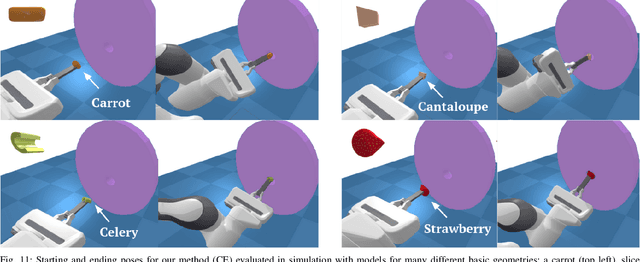

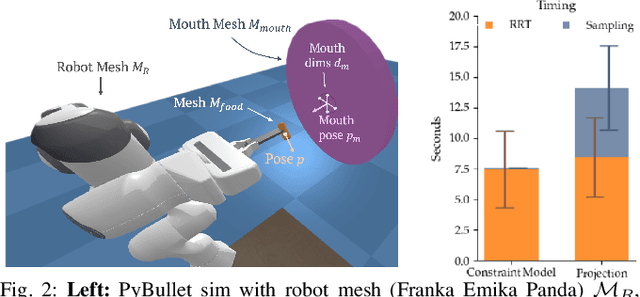
Robot-assisted feeding in household environments is challenging because it requires robots to generate trajectories that effectively bring food items of varying shapes and sizes into the mouth while making sure the user is comfortable. Our key insight is that in order to solve this challenge, robots must balance the efficiency of feeding a food item with the comfort of each individual bite. We formalize comfort and efficiency as heuristics to incorporate in motion planning. We present an approach based on heuristics-guided bi-directional Rapidly-exploring Random Trees (h-BiRRT) that selects bite transfer trajectories of arbitrary food item geometries and shapes using our developed bite efficiency and comfort heuristics and a learned constraint model. Real-robot evaluations show that optimizing both comfort and efficiency significantly outperforms a fixed-pose based method, and users preferred our method significantly more than that of a method that maximizes only user comfort. Videos and Appendices are found on our website: https://sites.google.com/view/comfortbitetransfer-icra22/home.
Leveraging Experience in Lazy Search
Oct 10, 2021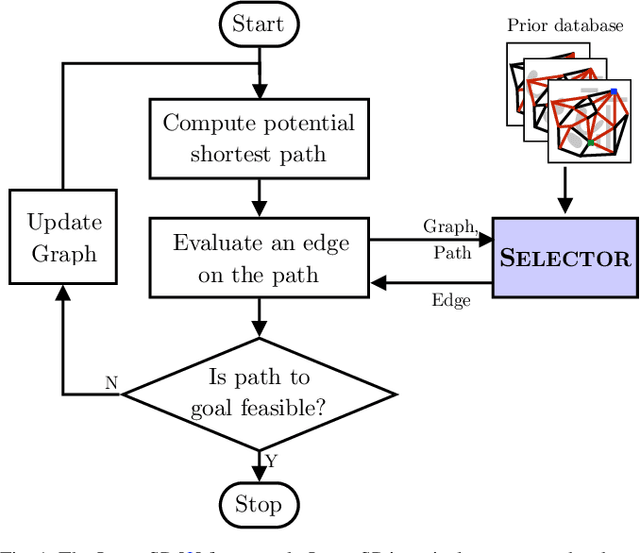
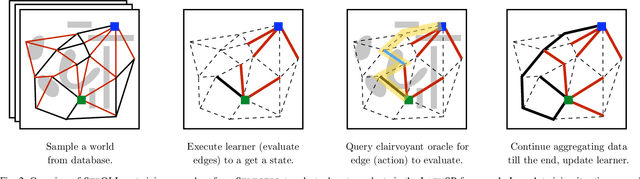
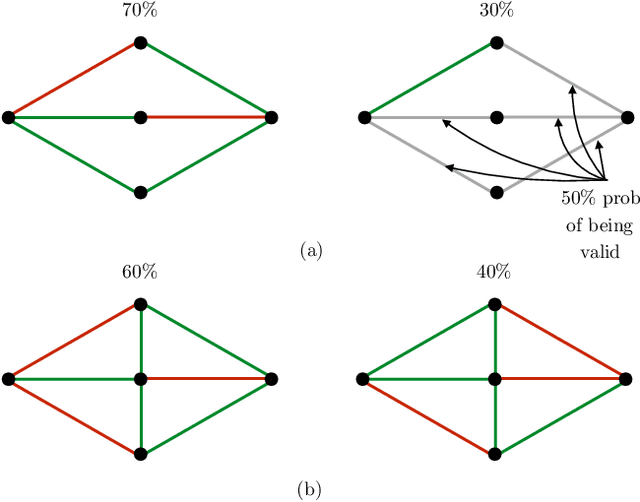
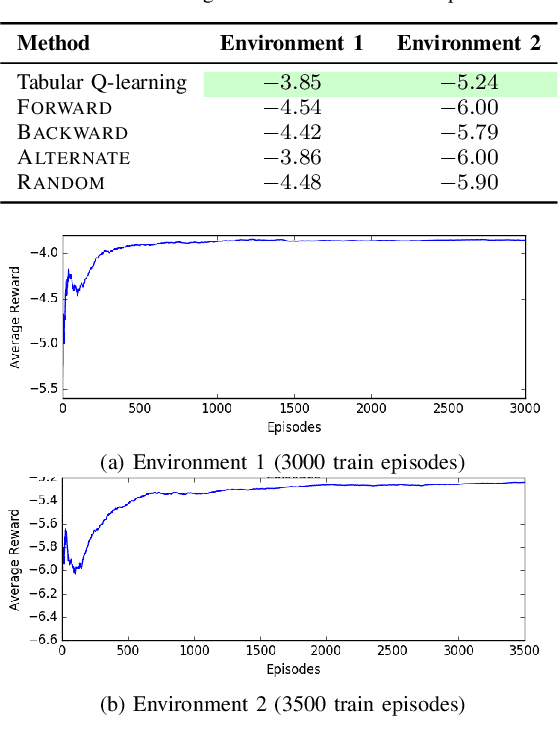
Lazy graph search algorithms are efficient at solving motion planning problems where edge evaluation is the computational bottleneck. These algorithms work by lazily computing the shortest potentially feasible path, evaluating edges along that path, and repeating until a feasible path is found. The order in which edges are selected is critical to minimizing the total number of edge evaluations: a good edge selector chooses edges that are not only likely to be invalid, but also eliminates future paths from consideration. We wish to learn such a selector by leveraging prior experience. We formulate this problem as a Markov Decision Process (MDP) on the state of the search problem. While solving this large MDP is generally intractable, we show that we can compute oracular selectors that can solve the MDP during training. With access to such oracles, we use imitation learning to find effective policies. If new search problems are sufficiently similar to problems solved during training, the learned policy will choose a good edge evaluation ordering and solve the motion planning problem quickly. We evaluate our algorithms on a wide range of 2D and 7D problems and show that the learned selector outperforms baseline commonly used heuristics. We further provide a novel theoretical analysis of lazy search in a Bayesian framework as well as regret guarantees on our imitation learning based approach to motion planning.