 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT is a Potential Zero-Shot Dependency Parser
Oct 25, 2023



Pre-trained language models have been widely used in dependency parsing task and have achieved significant improvements in parser performance. However, it remains an understudied question whether pre-trained language models can spontaneously exhibit the ability of dependency parsing without introducing additional parser structure in the zero-shot scenario. In this paper, we propose to explore the dependency parsing ability of large language models such as ChatGPT and conduct linguistic analysis. The experimental results demonstrate that ChatGPT is a potential zero-shot dependency parser, and the linguistic analysis also shows some unique preferences in parsing outputs.
DemoSG: Demonstration-enhanced Schema-guided Generation for Low-resource Event Extraction
Oct 16, 2023



Most current Event Extraction (EE) methods focus on the high-resource scenario, which requires a large amount of annotated data and can hardly be applied to low-resource domains. To address EE more effectively with limited resources, we propose the Demonstration-enhanced Schema-guided Generation (DemoSG) model, which benefits low-resource EE from two aspects: Firstly, we propose the demonstration-based learning paradigm for EE to fully use the annotated data, which transforms them into demonstrations to illustrate the extraction process and help the model learn effectively. Secondly, we formulate EE as a natural language generation task guided by schema-based prompts, thereby leveraging label semantics and promoting knowledge transfer in low-resource scenarios. We conduct extensive experiments under in-domain and domain adaptation low-resource settings on three datasets, and study the robustness of DemoSG. The results show that DemoSG significantly outperforms current methods in low-resource scenarios.
Type-aware Decoding via Explicitly Aggregating Event Information for Document-level Event Extraction
Oct 16, 2023



Document-level event extraction (DEE) faces two main challenges: arguments-scattering and multi-event. Although previous methods attempt to address these challenges, they overlook the interference of event-unrelated sentences during event detection and neglect the mutual interference of different event roles during argument extraction. Therefore, this paper proposes a novel Schema-based Explicitly Aggregating~(SEA) model to address these limitations. SEA aggregates event information into event type and role representations, enabling the decoding of event records based on specific type-aware representations. By detecting each event based on its event type representation, SEA mitigates the interference caused by event-unrelated information. Furthermore, SEA extracts arguments for each role based on its role-aware representations, reducing mutual interference between different roles. Experimental results on the ChFinAnn and DuEE-fin datasets show that SEA outperforms the SOTA methods.
L-CAD: Language-based Colorization with Any-level Descriptions
May 26, 2023



Language-based colorization produces plausible and visually pleasing colors under the guidance of user-friendly natural language descriptions. Previous methods implicitly assume that users provide comprehensive color descriptions for most of the objects in the image, which leads to suboptimal performance. In this paper, we propose a unified model to perform language-based colorization with any-level descriptions. We leverage the pretrained cross-modality generative model for its robust language understanding and rich color priors to handle the inherent ambiguity of any-level descriptions. We further design modules to align with input conditions to preserve local spatial structures and prevent the ghosting effect. With the proposed novel sampling strategy, our model achieves instance-aware colorization in diverse and complex scenarios. Extensive experimental results demonstrate our advantages of effectively handling any-level descriptions and outperforming both language-based and automatic colorization methods. The code and pretrained models are available at: https://github.com/changzheng123/L-CAD.
Schema-Free Dependency Parsing via Sequence Generation
Jan 28, 2022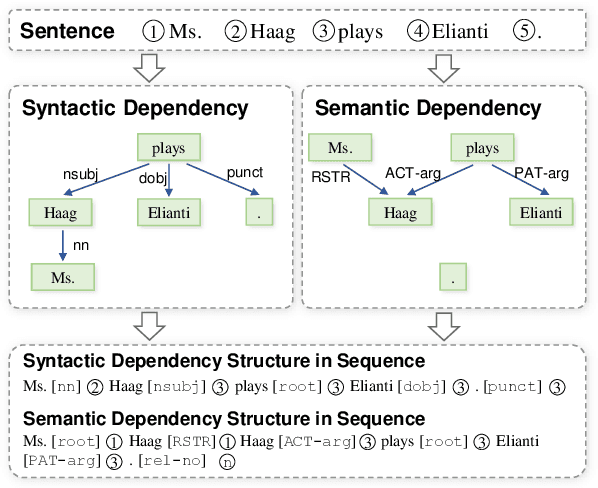
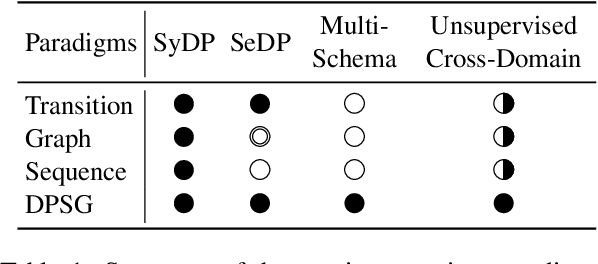
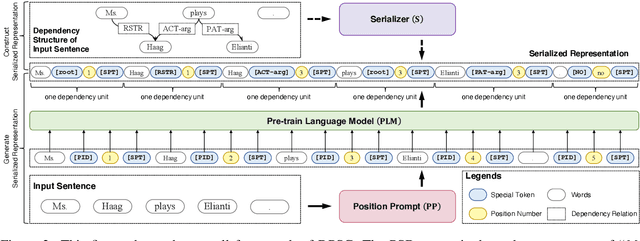
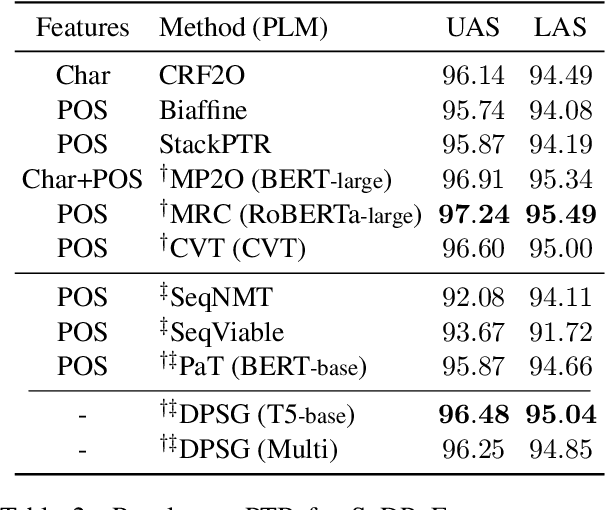
Dependency parsing aims to extract syntactic dependency structure or semantic dependency structure for sentences. Existing methods suffer the drawbacks of lacking universality or highly relying on the auxiliary decoder. To remedy these drawbacks, we propose to achieve universal and schema-free Dependency Parsing (DP) via Sequence Generation (SG) DPSG by utilizing only the pre-trained language model (PLM) without any auxiliary structures or parsing algorithms. We first explore different serialization designing strategies for converting parsing structures into sequences. Then we design dependency units and concatenate these units into the sequence for DPSG. Thanks to the high flexibility of the sequence generation, our DPSG can achieve both syntactic DP and semantic DP using a single model. By concatenating the prefix to indicate the specific schema with the sequence, our DPSG can even accomplish multi-schemata parsing. The effectiveness of our DPSG is demonstrated by the experiments on widely used DP benchmarks, i.e., PTB, CODT, SDP15, and SemEval16. DPSG achieves comparable results with the first-tier methods on all the benchmarks and even the state-of-the-art (SOTA) performance in CODT and SemEval16. This paper demonstrates our DPSG has the potential to be a new parsing paradigm. We will release our codes upon acceptance.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021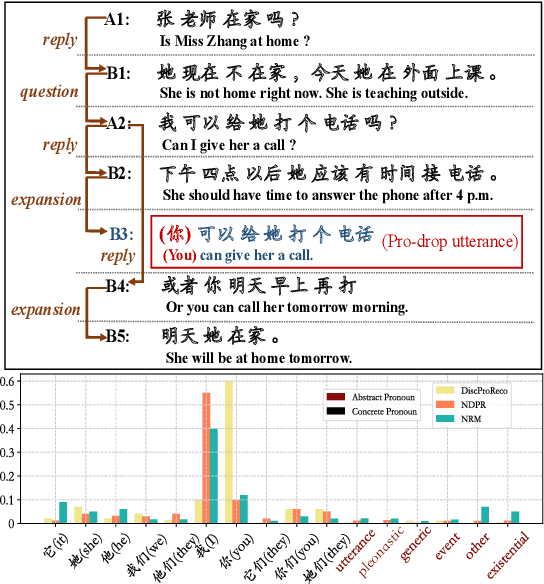
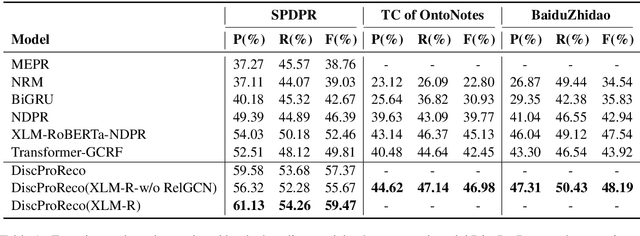
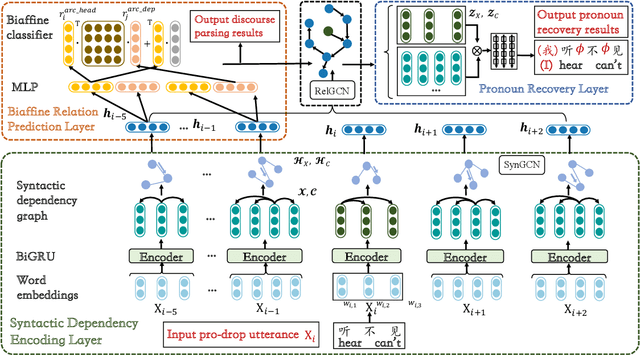
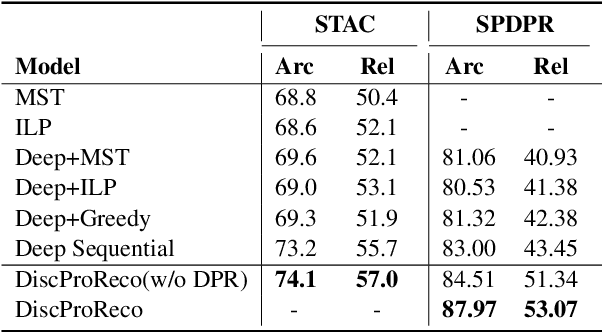
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
DeRenderNet: Intrinsic Image Decomposition of Urban Scenes with Shape-(In)dependent Shading Rendering
Apr 28, 2021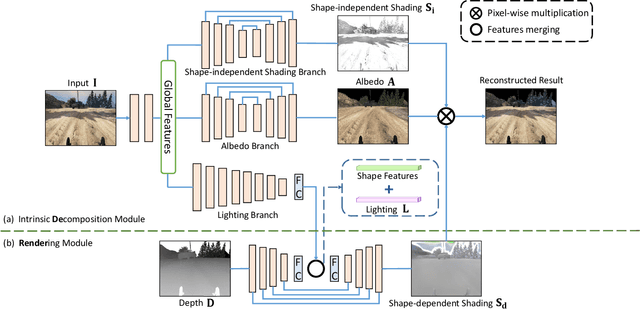
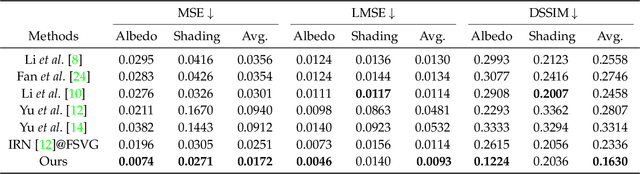
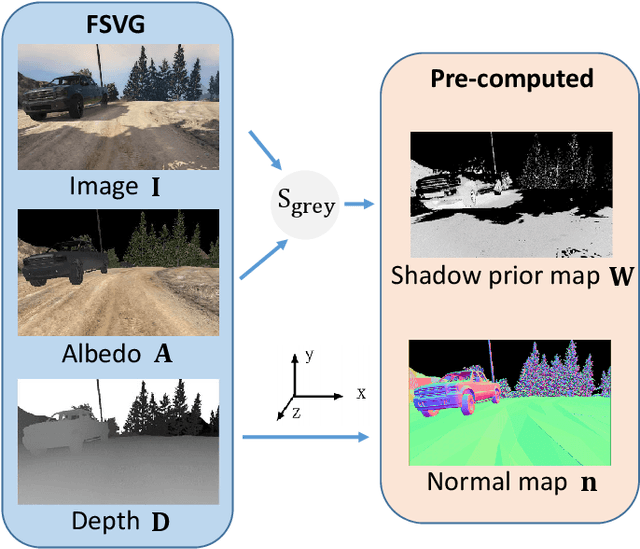
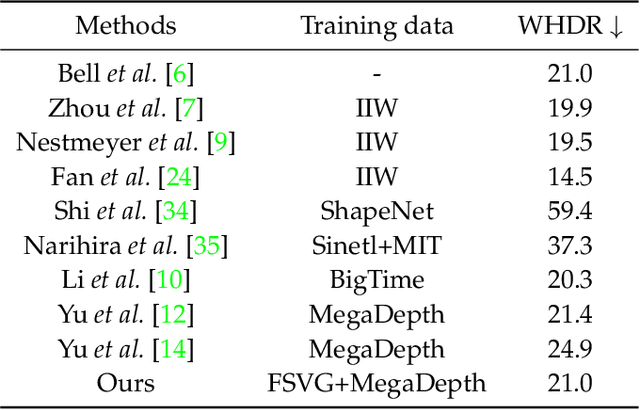
We propose DeRenderNet, a deep neural network to decompose the albedo and latent lighting, and render shape-(in)dependent shadings, given a single image of an outdoor urban scene, trained in a self-supervised manner. To achieve this goal, we propose to use the albedo maps extracted from scenes in videogames as direct supervision and pre-compute the normal and shadow prior maps based on the depth maps provided as indirect supervision. Compared with state-of-the-art intrinsic image decomposition methods, DeRenderNet produces shadow-free albedo maps with clean details and an accurate prediction of shadows in the shape-independent shading, which is shown to be effective in re-rendering and improving the accuracy of high-level vision tasks for urban scenes.
Spatially-Varying Outdoor Lighting Estimation from Intrinsics
Apr 28, 2021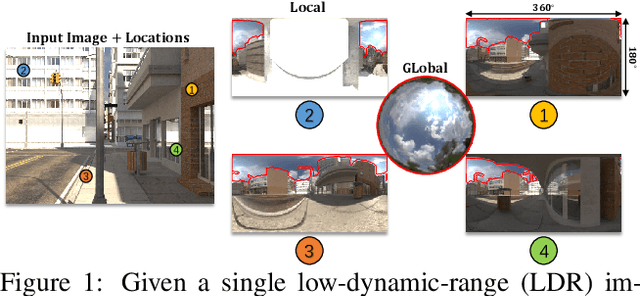
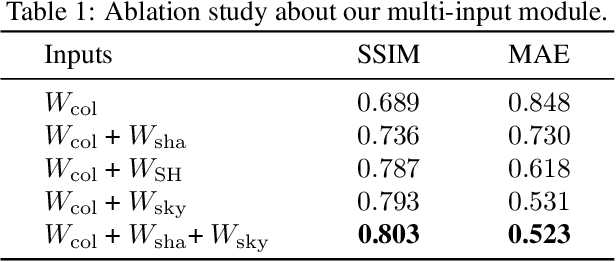
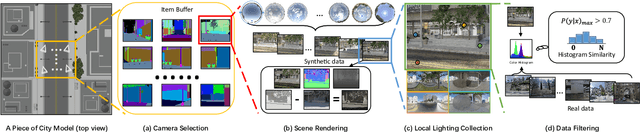
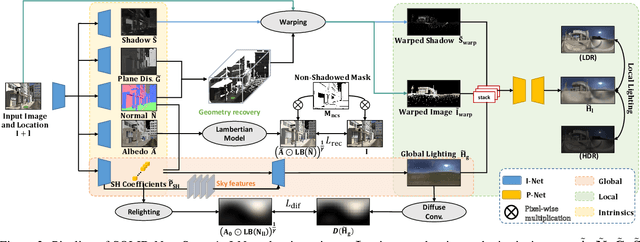
We present SOLID-Net, a neural network for spatially-varying outdoor lighting estimation from a single outdoor image for any 2D pixel location. Previous work has used a unified sky environment map to represent outdoor lighting. Instead, we generate spatially-varying local lighting environment maps by combining global sky environment map with warped image information according to geometric information estimated from intrinsics. As no outdoor dataset with image and local lighting ground truth is readily available, we introduce the SOLID-Img dataset with physically-based rendered images and their corresponding intrinsic and lighting information. We train a deep neural network to regress intrinsic cues with physically-based constraints and use them to conduct global and local lightings estimation. Experiments on both synthetic and real datasets show that SOLID-Net significantly outperforms previous methods.
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
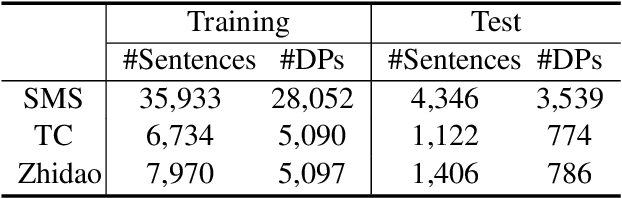
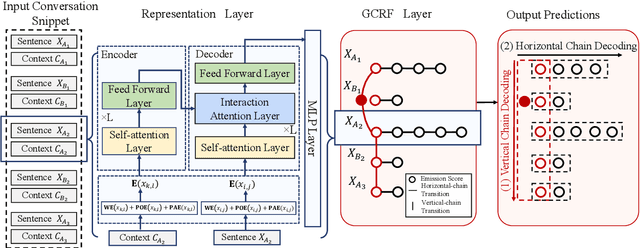
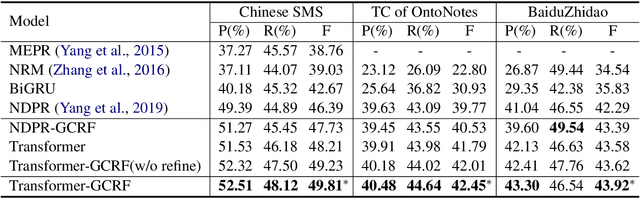
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.
ST-MNIST -- The Spiking Tactile MNIST Neuromorphic Dataset
May 08, 2020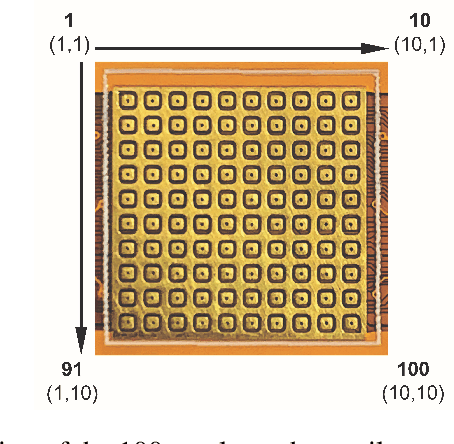
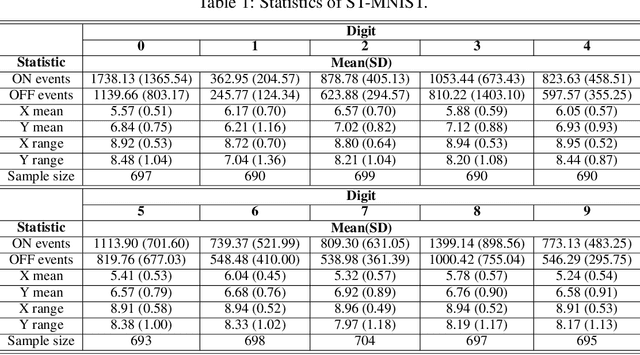
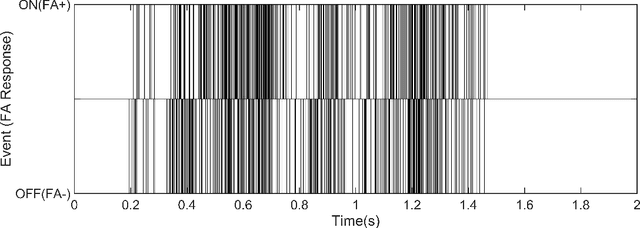
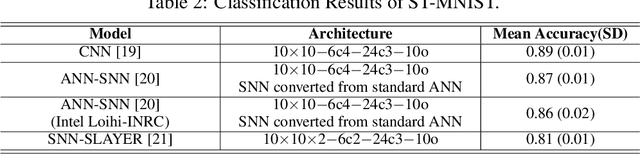
Tactile sensing is an essential modality for smart robots as it enables them to interact flexibly with physical objects in their environment. Recent advancements in electronic skins have led to the development of data-driven machine learning methods that exploit this important sensory modality. However, current datasets used to train such algorithms are limited to standard synchronous tactile sensors. There is a dearth of neuromorphic event-based tactile datasets, principally due to the scarcity of large-scale event-based tactile sensors. Having such datasets is crucial for the development and evaluation of new algorithms that process spatio-temporal event-based data. For example, evaluating spiking neural networks on conventional frame-based datasets is considered sub-optimal. Here, we debut a novel neuromorphic Spiking Tactile MNIST (ST-MNIST) dataset, which comprises handwritten digits obtained by human participants writing on a neuromorphic tactile sensor array. We also describe an initial effort to evaluate our ST-MNIST dataset using existing artificial and spiking neural network models. The classification accuracies provided herein can serve as performance benchmarks for future work. We anticipate that our ST-MNIST dataset will be of interest and useful to the neuromorphic and robotics research communities.