 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Score Optimization for Multi Dimension Video Quality Assessment
Feb 18, 2026Video Quality Assessment (VQA) is evolving beyond single-number mean opinion score toward richer, multi-faceted evaluations of video content. In this paper, we present a large-scale multi-dimensional VQA dataset UltraVQA that encompasses diverse User-Generated Content~(UGC) annotated across five key quality dimensions: Motion Quality, Motion Amplitude, Aesthetic Quality, Content Quality, and Clarity Quality. Each video in our dataset is scored by over 3 human raters on these dimensions, with fine-grained sub-attribute labels, and accompanied by an explanatory rationale generated by GPT based on the collective human judgments. To better leverage these rich annotations and improve discrete quality score assessment, we introduce Analytic Score Optimization (ASO), a theoretically grounded post-training objective derived for multi-dimensional VQA. By reframing quality assessment as a regularized decision-making process, we obtain a closed-form solution that naturally captures the ordinal nature of human ratings, ensuring alignment with human ranking preferences. In experiments, our method outperforms most baselines including closed-source APIs and open-source models, while also reducing mean absolute error (MAE) in quality prediction. Our work highlights the importance of multi-dimensional, interpretable annotations and reinforcement-based alignment in advancing video quality assessment.
ChatGPT is a Potential Zero-Shot Dependency Parser
Oct 25, 2023



Pre-trained language models have been widely used in dependency parsing task and have achieved significant improvements in parser performance. However, it remains an understudied question whether pre-trained language models can spontaneously exhibit the ability of dependency parsing without introducing additional parser structure in the zero-shot scenario. In this paper, we propose to explore the dependency parsing ability of large language models such as ChatGPT and conduct linguistic analysis. The experimental results demonstrate that ChatGPT is a potential zero-shot dependency parser, and the linguistic analysis also shows some unique preferences in parsing outputs.
Schema-Free Dependency Parsing via Sequence Generation
Jan 28, 2022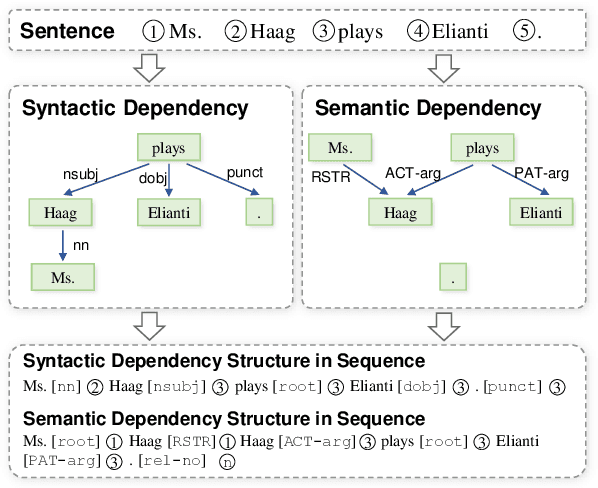
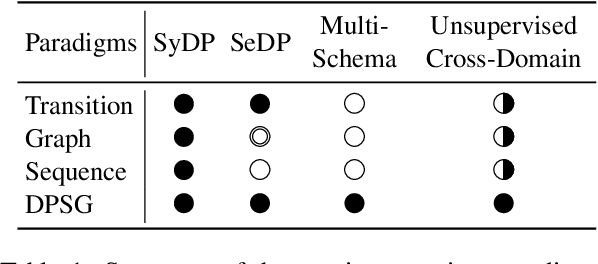
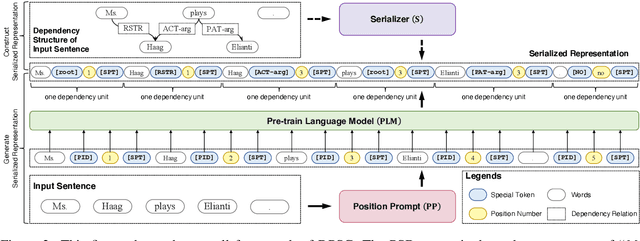
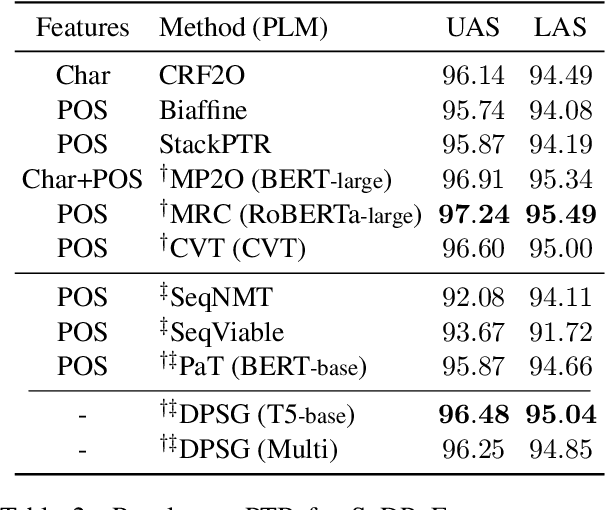
Dependency parsing aims to extract syntactic dependency structure or semantic dependency structure for sentences. Existing methods suffer the drawbacks of lacking universality or highly relying on the auxiliary decoder. To remedy these drawbacks, we propose to achieve universal and schema-free Dependency Parsing (DP) via Sequence Generation (SG) DPSG by utilizing only the pre-trained language model (PLM) without any auxiliary structures or parsing algorithms. We first explore different serialization designing strategies for converting parsing structures into sequences. Then we design dependency units and concatenate these units into the sequence for DPSG. Thanks to the high flexibility of the sequence generation, our DPSG can achieve both syntactic DP and semantic DP using a single model. By concatenating the prefix to indicate the specific schema with the sequence, our DPSG can even accomplish multi-schemata parsing. The effectiveness of our DPSG is demonstrated by the experiments on widely used DP benchmarks, i.e., PTB, CODT, SDP15, and SemEval16. DPSG achieves comparable results with the first-tier methods on all the benchmarks and even the state-of-the-art (SOTA) performance in CODT and SemEval16. This paper demonstrates our DPSG has the potential to be a new parsing paradigm. We will release our codes upon acceptance.