 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Oct 08, 2021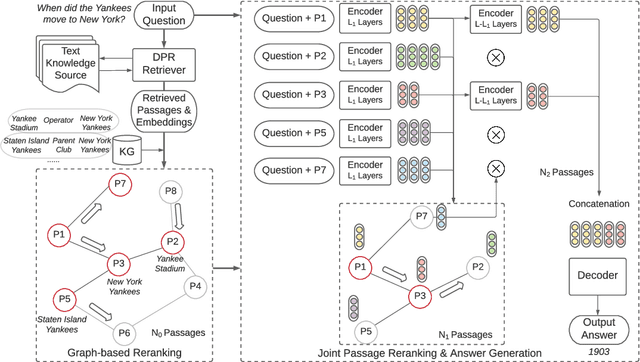
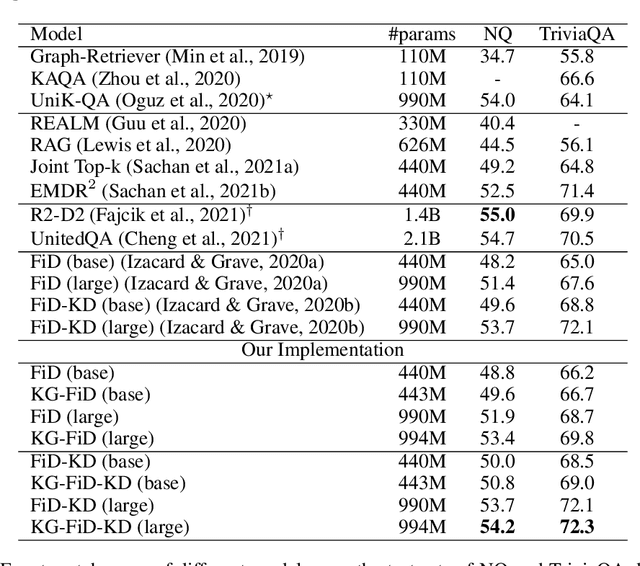
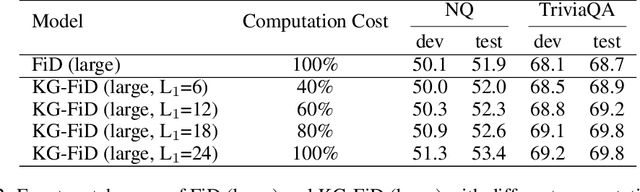
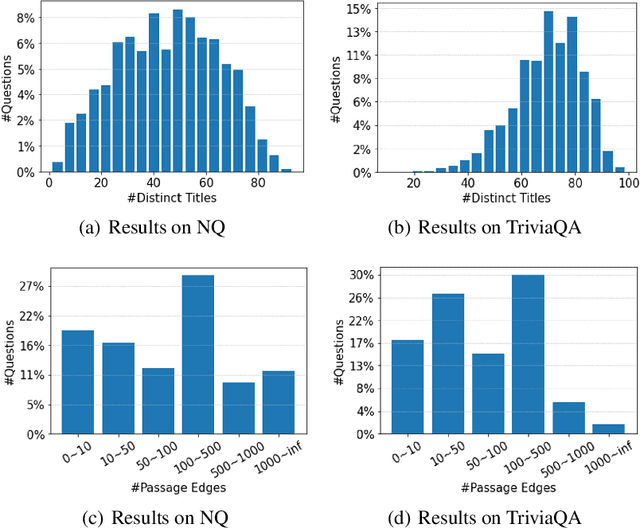
Current Open-Domain Question Answering (ODQA) model paradigm often contains a retrieving module and a reading module. Given an input question, the reading module predicts the answer from the relevant passages which are retrieved by the retriever. The recent proposed Fusion-in-Decoder (FiD), which is built on top of the pretrained generative model T5, achieves the state-of-the-art performance in the reading module. Although being effective, it remains constrained by inefficient attention on all retrieved passages which contain a lot of noise. In this work, we propose a novel method KG-FiD, which filters noisy passages by leveraging the structural relationship among the retrieved passages with a knowledge graph. We initiate the passage node embedding from the FiD encoder and then use graph neural network (GNN) to update the representation for reranking. To improve the efficiency, we build the GNN on top of the intermediate layer output of the FiD encoder and only pass a few top reranked passages into the higher layers of encoder and decoder for answer generation. We also apply the proposed GNN based reranking method to enhance the passage retrieval results in the retrieving module. Extensive experiments on common ODQA benchmark datasets (Natural Question and TriviaQA) demonstrate that KG-FiD can improve vanilla FiD by up to 1.5% on answer exact match score and achieve comparable performance with FiD with only 40% of computation cost.
Want To Reduce Labeling Cost? GPT-3 Can Help
Aug 30, 2021
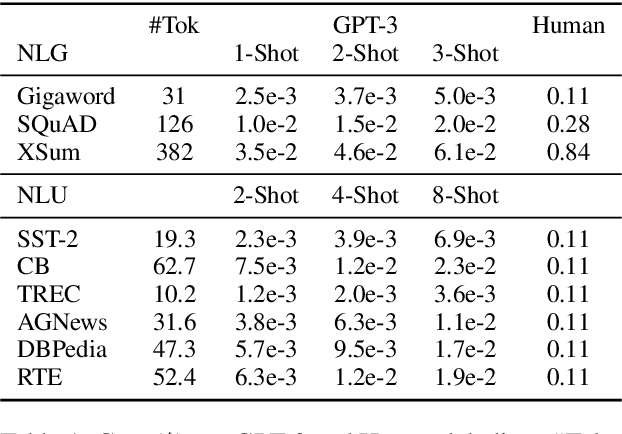
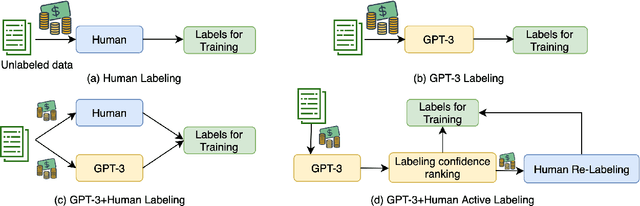
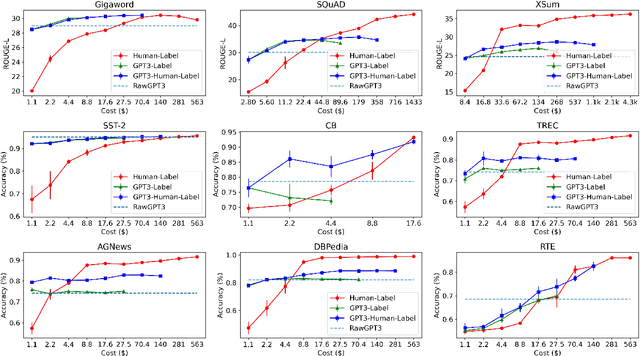
Data annotation is a time-consuming and labor-intensive process for many NLP tasks. Although there exist various methods to produce pseudo data labels, they are often task-specific and require a decent amount of labeled data to start with. Recently, the immense language model GPT-3 with 175 billion parameters has achieved tremendous improvement across many few-shot learning tasks. In this paper, we explore ways to leverage GPT-3 as a low-cost data labeler to train other models. We find that, to make the downstream model achieve the same performance on a variety of NLU and NLG tasks, it costs 50% to 96% less to use labels from GPT-3 than using labels from humans. Furthermore, we propose a novel framework of combining pseudo labels from GPT-3 with human labels, which leads to even better performance with limited labeling budget. These results present a cost-effective data labeling methodology that is generalizable to many practical applications.
Playing Lottery Tickets with Vision and Language
Apr 23, 2021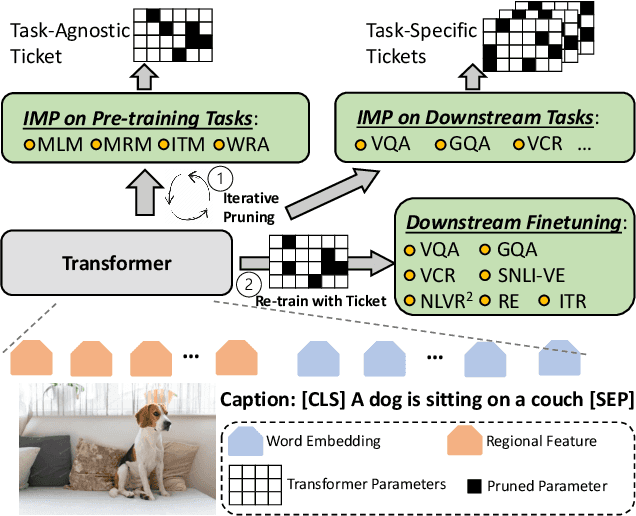
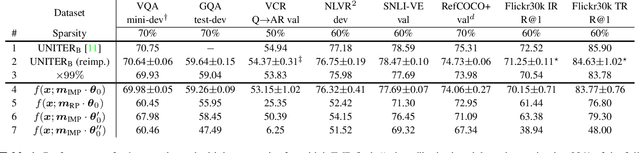
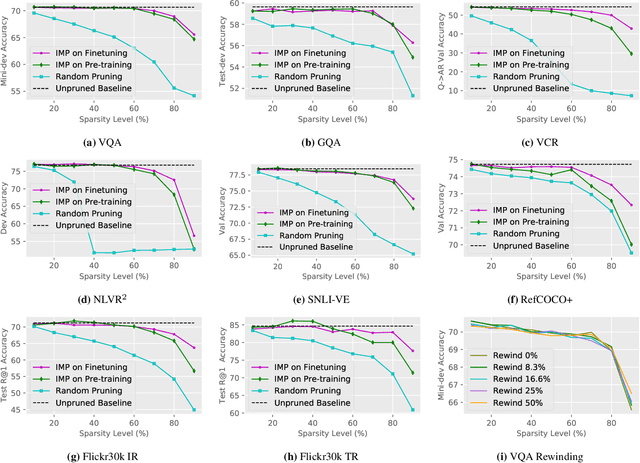
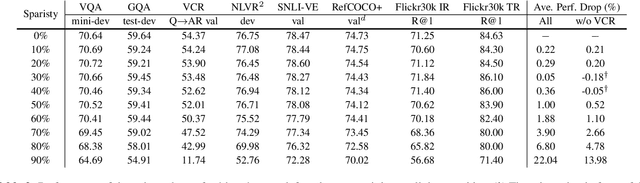
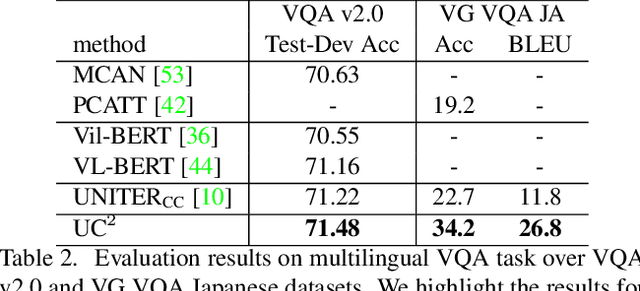
Large-scale transformer-based pre-training has recently revolutionized vision-and-language (V+L) research. Models such as LXMERT, ViLBERT and UNITER have significantly lifted the state of the art over a wide range of V+L tasks. However, the large number of parameters in such models hinders their application in practice. In parallel, work on the lottery ticket hypothesis has shown that deep neural networks contain small matching subnetworks that can achieve on par or even better performance than the dense networks when trained in isolation. In this work, we perform the first empirical study to assess whether such trainable subnetworks also exist in pre-trained V+L models. We use UNITER, one of the best-performing V+L models, as the testbed, and consolidate 7 representative V+L tasks for experiments, including visual question answering, visual commonsense reasoning, visual entailment, referring expression comprehension, image-text retrieval, GQA, and NLVR$^2$. Through comprehensive analysis, we summarize our main findings as follows. ($i$) It is difficult to find subnetworks (i.e., the tickets) that strictly match the performance of the full UNITER model. However, it is encouraging to confirm that we can find "relaxed" winning tickets at 50%-70% sparsity that maintain 99% of the full accuracy. ($ii$) Subnetworks found by task-specific pruning transfer reasonably well to the other tasks, while those found on the pre-training tasks at 60%/70% sparsity transfer universally, matching 98%/96% of the full accuracy on average over all the tasks. ($iii$) Adversarial training can be further used to enhance the performance of the found lottery tickets.
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Apr 11, 2021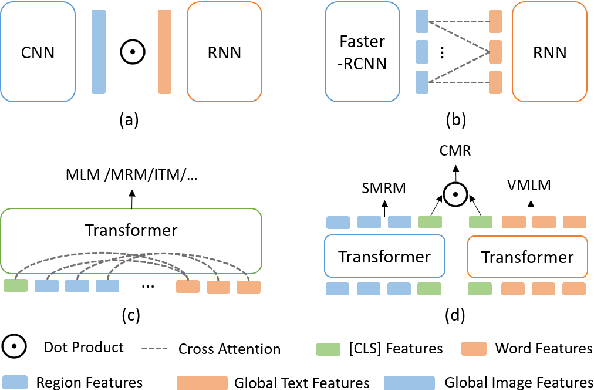
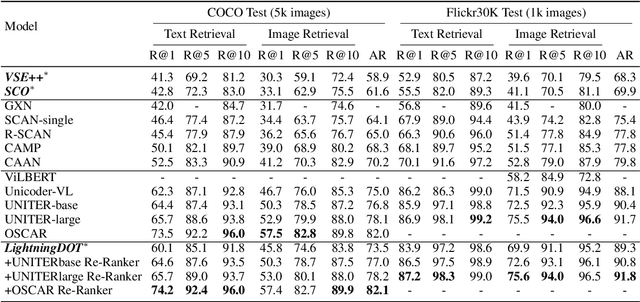
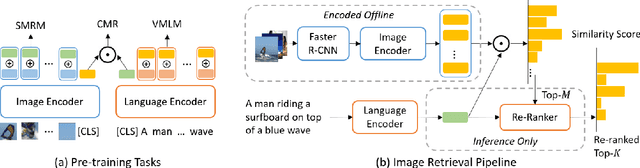

Multimodal pre-training has propelled great advancement in vision-and-language research. These large-scale pre-trained models, although successful, fatefully suffer from slow inference speed due to enormous computation cost mainly from cross-modal attention in Transformer architecture. When applied to real-life applications, such latency and computation demand severely deter the practical use of pre-trained models. In this paper, we study Image-text retrieval (ITR), the most mature scenario of V+L application, which has been widely studied even prior to the emergence of recent pre-trained models. We propose a simple yet highly effective approach, LightningDOT that accelerates the inference time of ITR by thousands of times, without sacrificing accuracy. LightningDOT removes the time-consuming cross-modal attention by pre-training on three novel learning objectives, extracting feature indexes offline, and employing instant dot-product matching with further re-ranking, which significantly speeds up retrieval process. In fact, LightningDOT achieves new state of the art across multiple ITR benchmarks such as Flickr30k, COCO and Multi30K, outperforming existing pre-trained models that consume 1000x magnitude of computational hours. Code and pre-training checkpoints are available at https://github.com/intersun/LightningDOT.
UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
Apr 01, 2021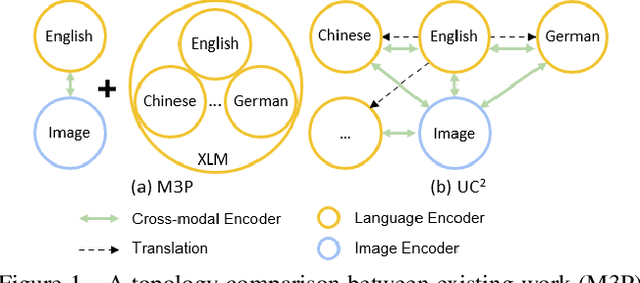
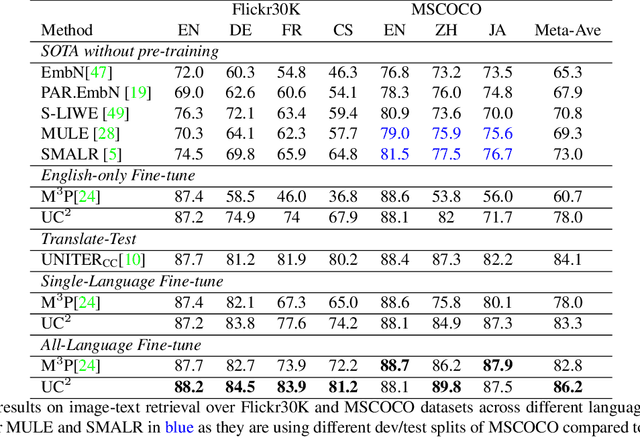
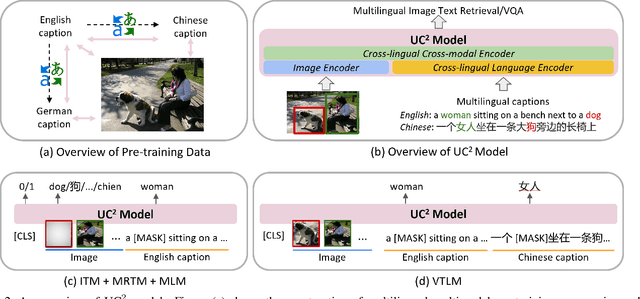
Vision-and-language pre-training has achieved impressive success in learning multimodal representations between vision and language. To generalize this success to non-English languages, we introduce UC2, the first machine translation-augmented framework for cross-lingual cross-modal representation learning. To tackle the scarcity problem of multilingual captions for image datasets, we first augment existing English-only datasets with other languages via machine translation (MT). Then we extend the standard Masked Language Modeling and Image-Text Matching training objectives to multilingual setting, where alignment between different languages is captured through shared visual context (i.e, using image as pivot). To facilitate the learning of a joint embedding space of images and all languages of interest, we further propose two novel pre-training tasks, namely Masked Region-to-Token Modeling (MRTM) and Visual Translation Language Modeling (VTLM), leveraging MT-enhanced translated data. Evaluation on multilingual image-text retrieval and multilingual visual question answering benchmarks demonstrates that our proposed framework achieves new state-of-the-art on diverse non-English benchmarks while maintaining comparable performance to monolingual pre-trained models on English tasks.
The Elastic Lottery Ticket Hypothesis
Mar 30, 2021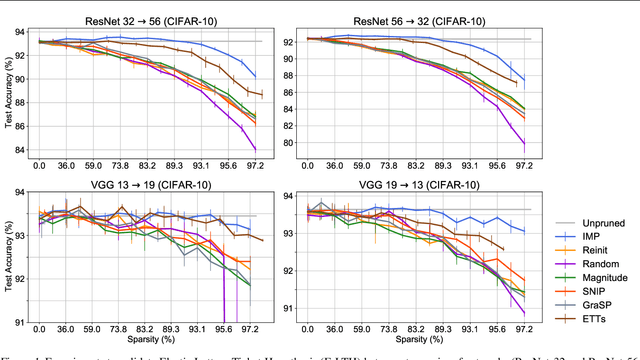
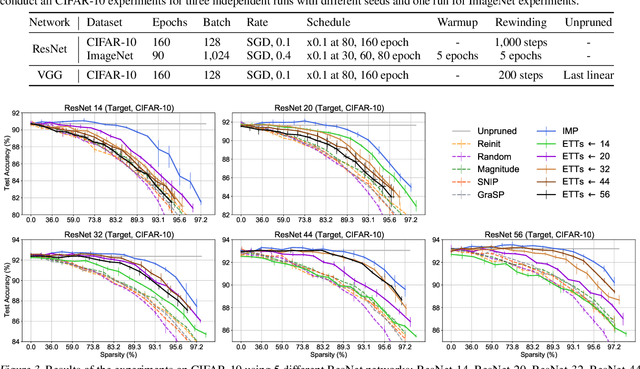
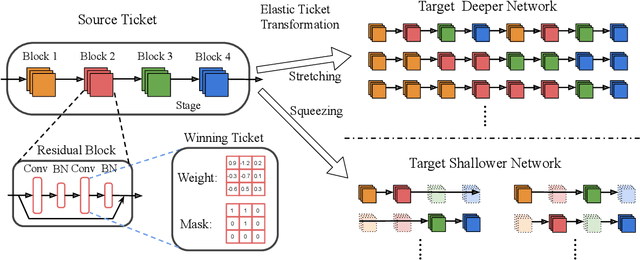
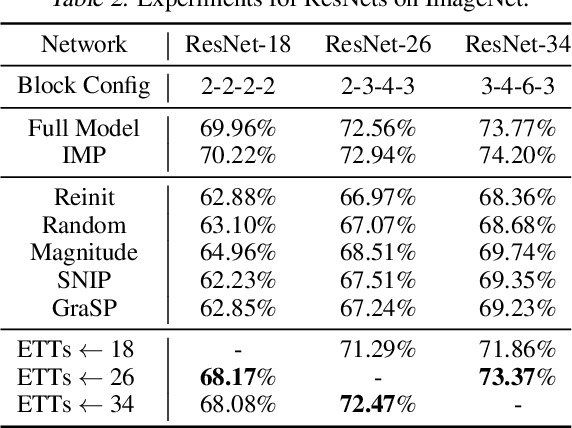
Lottery Ticket Hypothesis raises keen attention to identifying sparse trainable subnetworks or winning tickets, at the initialization (or early stage) of training, which can be trained in isolation to achieve similar or even better performance compared to the full models. Despite many efforts being made, the most effective method to identify such winning tickets is still Iterative Magnitude-based Pruning (IMP), which is computationally expensive and has to be run thoroughly for every different network. A natural question that comes in is: can we "transform" the winning ticket found in one network to another with a different architecture, yielding a winning ticket for the latter at the beginning, without re-doing the expensive IMP? Answering this question is not only practically relevant for efficient "once-for-all" winning ticket finding, but also theoretically appealing for uncovering inherently scalable sparse patterns in networks. We conduct extensive experiments on CIFAR-10 and ImageNet, and propose a variety of strategies to tweak the winning tickets found from different networks of the same model family (e.g., ResNets). Based on these results, we articulate the Elastic Lottery Ticket Hypothesis (E-LTH): by mindfully replicating (or dropping) and re-ordering layers for one network, its corresponding winning ticket could be stretched (or squeezed) into a subnetwork for another deeper (or shallower) network from the same family, whose performance is nearly as competitive as the latter's winning ticket directly found by IMP. We have also thoroughly compared E-LTH with pruning-at-initialization and dynamic sparse training methods, and discuss the generalizability of E-LTH to different model families, layer types, and even across datasets. Our codes are publicly available at https://github.com/VITA-Group/ElasticLTH.
EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
Dec 31, 2020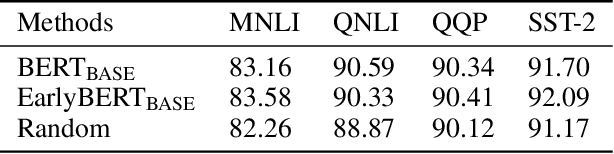
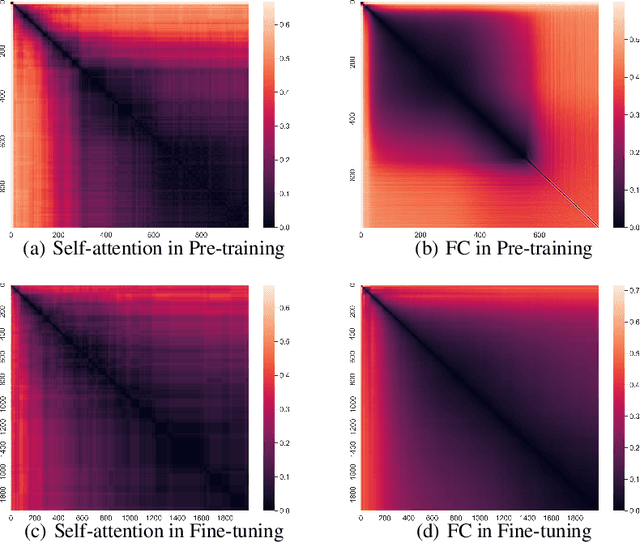
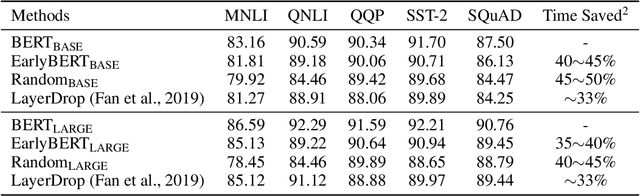
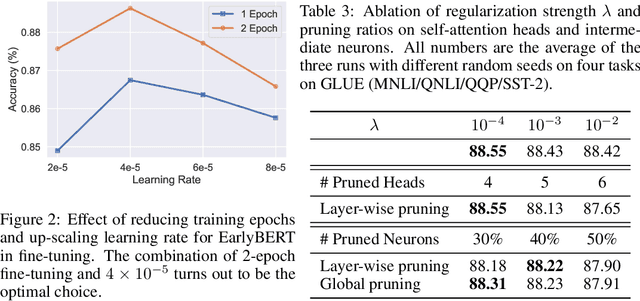
Deep, heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focus on reducing inference cost/time, while still requiring expensive training process. Other works use extremely large batch sizes to shorten the pre-training time at the expense of high demand for computation resources. In this paper, inspired by the Early-Bird Lottery Tickets studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. We are the first to identify structured winning tickets in the early stage of BERT training, and use them for efficient training. Comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks show that EarlyBERT easily achieves comparable performance to standard BERT with 35~45% less training time.
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
Oct 14, 2020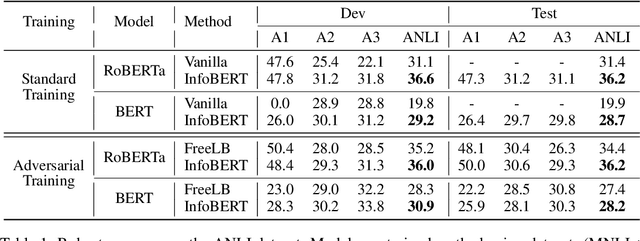
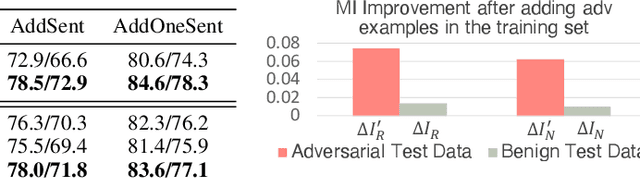
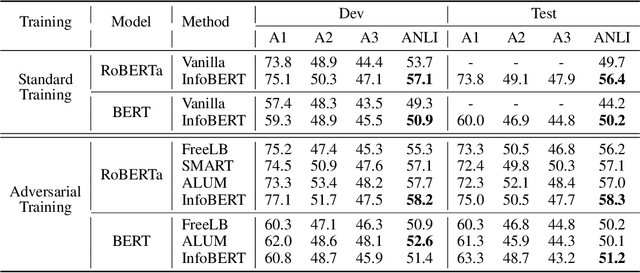
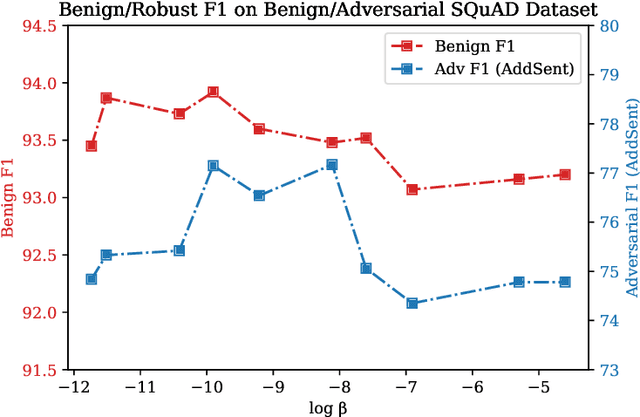
Large-scale language models such as BERT have achieved state-of-the-art performance across a wide range of NLP tasks. Recent studies, however, show that such BERT-based models are vulnerable facing the threats of textual adversarial attacks. We aim to address this problem from an information-theoretic perspective, and propose InfoBERT, a novel learning framework for robust fine-tuning of pre-trained language models. InfoBERT contains two mutual-information-based regularizers for model training: (i) an Information Bottleneck regularizer, which suppresses noisy mutual information between the input and the feature representation; and (ii) a Robust Feature regularizer, which increases the mutual information between local robust features and global features. We provide a principled way to theoretically analyze and improve the robustness of representation learning for language models in both standard and adversarial training. Extensive experiments demonstrate that InfoBERT achieves state-of-the-art robust accuracy over several adversarial datasets on Natural Language Inference (NLI) and Question Answering (QA) tasks.
Counterfactual Variable Control for Robust and Interpretable Question Answering
Oct 12, 2020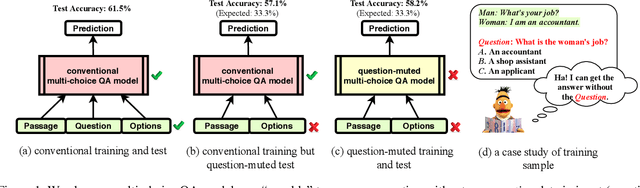
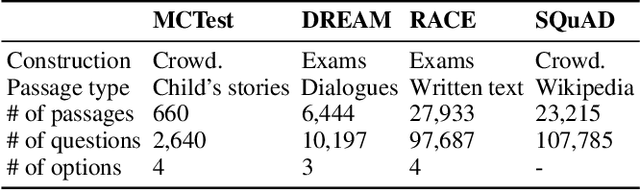
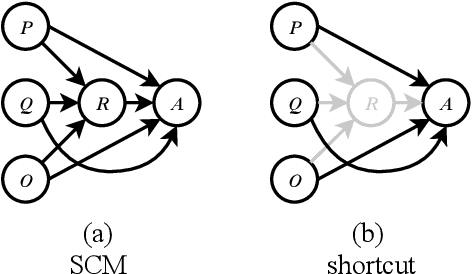
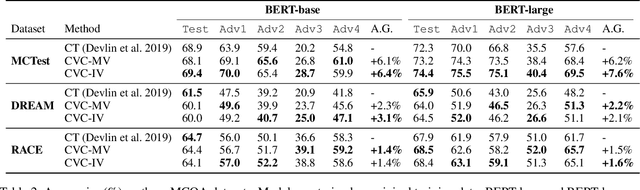
Deep neural network based question answering (QA) models are neither robust nor explainable in many cases. For example, a multiple-choice QA model, tested without any input of question, is surprisingly "capable" to predict the most of correct options. In this paper, we inspect such spurious "capability" of QA models using causal inference. We find the crux is the shortcut correlation, e.g., unrobust word alignment between passage and options learned by the models. We propose a novel approach called Counterfactual Variable Control (CVC) that explicitly mitigates any shortcut correlation and preserves the comprehensive reasoning for robust QA. Specifically, we leverage multi-branch architecture that allows us to disentangle robust and shortcut correlations in the training process of QA. We then conduct two novel CVC inference methods (on trained models) to capture the effect of comprehensive reasoning as the final prediction. For evaluation, we conduct extensive experiments using two BERT backbones on both multi-choice and span-extraction QA benchmarks. The results show that our CVC achieves high robustness against a variety of adversarial attacks in QA while maintaining good interpretation ability.
Cross-Thought for Sentence Encoder Pre-training
Oct 07, 2020
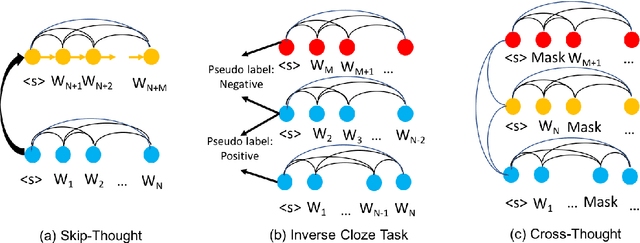
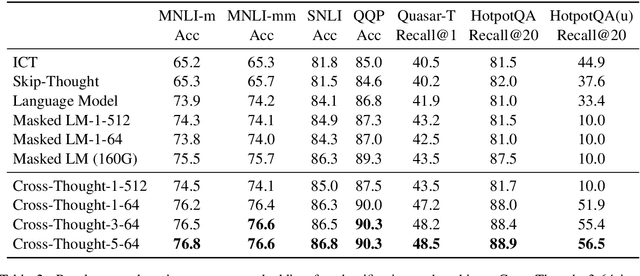
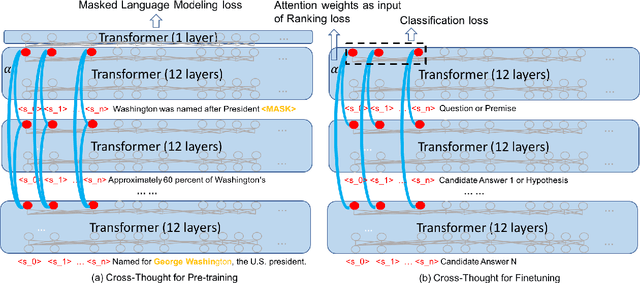
In this paper, we propose Cross-Thought, a novel approach to pre-training sequence encoder, which is instrumental in building reusable sequence embeddings for large-scale NLP tasks such as question answering. Instead of using the original signals of full sentences, we train a Transformer-based sequence encoder over a large set of short sequences, which allows the model to automatically select the most useful information for predicting masked words. Experiments on question answering and textual entailment tasks demonstrate that our pre-trained encoder can outperform state-of-the-art encoders trained with continuous sentence signals as well as traditional masked language modeling baselines. Our proposed approach also achieves new state of the art on HotpotQA (full-wiki setting) by improving intermediate information retrieval performance.