 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Evaluating LLMs for Fine-Grained Automatic Malware Behavior Auditing
Sep 17, 2025



Automated malware classification has achieved strong detection performance. Yet, malware behavior auditing seeks causal and verifiable explanations of malicious activities -- essential not only to reveal what malware does but also to substantiate such claims with evidence. This task is challenging, as adversarial intent is often hidden within complex, framework-heavy applications, making manual auditing slow and costly. Large Language Models (LLMs) could help address this gap, but their auditing potential remains largely unexplored due to three limitations: (1) scarce fine-grained annotations for fair assessment; (2) abundant benign code obscuring malicious signals; and (3) unverifiable, hallucination-prone outputs undermining attribution credibility. To close this gap, we introduce MalEval, a comprehensive framework for fine-grained Android malware auditing, designed to evaluate how effectively LLMs support auditing under real-world constraints. MalEval provides expert-verified reports and an updated sensitive API list to mitigate ground truth scarcity and reduce noise via static reachability analysis. Function-level structural representations serve as intermediate attribution units for verifiable evaluation. Building on this, we define four analyst-aligned tasks -- function prioritization, evidence attribution, behavior synthesis, and sample discrimination -- together with domain-specific metrics and a unified workload-oriented score. We evaluate seven widely used LLMs on a curated dataset of recent malware and misclassified benign apps, offering the first systematic assessment of their auditing capabilities. MalEval reveals both promising potential and critical limitations across audit stages, providing a reproducible benchmark and foundation for future research on LLM-enhanced malware behavior auditing. MalEval is publicly available at https://github.com/ZhengXR930/MalEval.git
MEGG: Replay via Maximally Extreme GGscore in Incremental Learning for Neural Recommendation Models
Sep 09, 2025



Neural Collaborative Filtering models are widely used in recommender systems but are typically trained under static settings, assuming fixed data distributions. This limits their applicability in dynamic environments where user preferences evolve. Incremental learning offers a promising solution, yet conventional methods from computer vision or NLP face challenges in recommendation tasks due to data sparsity and distinct task paradigms. Existing approaches for neural recommenders remain limited and often lack generalizability. To address this, we propose MEGG, Replay Samples with Maximally Extreme GGscore, an experience replay based incremental learning framework. MEGG introduces GGscore, a novel metric that quantifies sample influence, enabling the selective replay of highly influential samples to mitigate catastrophic forgetting. Being model-agnostic, MEGG integrates seamlessly across architectures and frameworks. Experiments on three neural models and four benchmark datasets show superior performance over state-of-the-art baselines, with strong scalability, efficiency, and robustness. Implementation will be released publicly upon acceptance.
CURE: Controlled Unlearning for Robust Embeddings -- Mitigating Conceptual Shortcuts in Pre-Trained Language Models
Sep 05, 2025Pre-trained language models have achieved remarkable success across diverse applications but remain susceptible to spurious, concept-driven correlations that impair robustness and fairness. In this work, we introduce CURE, a novel and lightweight framework that systematically disentangles and suppresses conceptual shortcuts while preserving essential content information. Our method first extracts concept-irrelevant representations via a dedicated content extractor reinforced by a reversal network, ensuring minimal loss of task-relevant information. A subsequent controllable debiasing module employs contrastive learning to finely adjust the influence of residual conceptual cues, enabling the model to either diminish harmful biases or harness beneficial correlations as appropriate for the target task. Evaluated on the IMDB and Yelp datasets using three pre-trained architectures, CURE achieves an absolute improvement of +10 points in F1 score on IMDB and +2 points on Yelp, while introducing minimal computational overhead. Our approach establishes a flexible, unsupervised blueprint for combating conceptual biases, paving the way for more reliable and fair language understanding systems.
Careful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025



Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.
BOOD: Boundary-based Out-Of-Distribution Data Generation
Aug 01, 2025


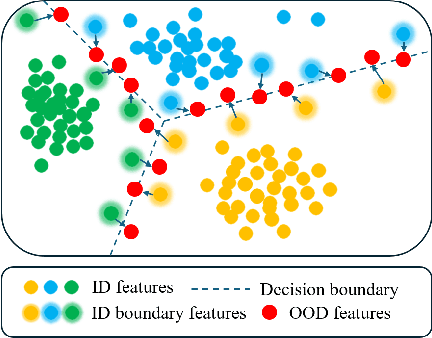
Harnessing the power of diffusion models to synthesize auxiliary training data based on latent space features has proven effective in enhancing out-of-distribution (OOD) detection performance. However, extracting effective features outside the in-distribution (ID) boundary in latent space remains challenging due to the difficulty of identifying decision boundaries between classes. This paper proposes a novel framework called Boundary-based Out-Of-Distribution data generation (BOOD), which synthesizes high-quality OOD features and generates human-compatible outlier images using diffusion models. BOOD first learns a text-conditioned latent feature space from the ID dataset, selects ID features closest to the decision boundary, and perturbs them to cross the decision boundary to form OOD features. These synthetic OOD features are then decoded into images in pixel space by a diffusion model. Compared to previous works, BOOD provides a more training efficient strategy for synthesizing informative OOD features, facilitating clearer distinctions between ID and OOD data. Extensive experimental results on common benchmarks demonstrate that BOOD surpasses the state-of-the-art method significantly, achieving a 29.64% decrease in average FPR95 (40.31% vs. 10.67%) and a 7.27% improvement in average AUROC (90.15% vs. 97.42%) on the CIFAR-100 dataset.
Multi-IMU Sensor Fusion for Legged Robots
Jul 15, 2025



This paper presents a state-estimation solution for legged robots that uses a set of low-cost, compact, and lightweight sensors to achieve low-drift pose and velocity estimation under challenging locomotion conditions. The key idea is to leverage multiple inertial measurement units on different links of the robot to correct a major error source in standard proprioceptive odometry. We fuse the inertial sensor information and joint encoder measurements in an extended Kalman filter, then combine the velocity estimate from this filter with camera data in a factor-graph-based sliding-window estimator to form a visual-inertial-leg odometry method. We validate our state estimator through comprehensive theoretical analysis and hardware experiments performed using real-world robot data collected during a variety of challenging locomotion tasks. Our algorithm consistently achieves minimal position deviation, even in scenarios involving substantial ground impact, foot slippage, and sudden body rotations. A C++ implementation, along with a large-scale dataset, is available at https://github.com/ShuoYangRobotics/Cerberus2.0.
NLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025



Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
RecCoT: Enhancing Recommendation via Chain-of-Thought
Jun 26, 2025In real-world applications, users always interact with items in multiple aspects, such as through implicit binary feedback (e.g., clicks, dislikes, long views) and explicit feedback (e.g., comments, reviews). Modern recommendation systems (RecSys) learn user-item collaborative signals from these implicit feedback signals as a large-scale binary data-streaming, subsequently recommending other highly similar items based on users' personalized historical interactions. However, from this collaborative-connection perspective, the RecSys does not focus on the actual content of the items themselves but instead prioritizes higher-probability signals of behavioral co-occurrence among items. Consequently, under this binary learning paradigm, the RecSys struggles to understand why a user likes or dislikes certain items. To alleviate it, some works attempt to utilize the content-based reviews to capture the semantic knowledge to enhance recommender models. However, most of these methods focus on predicting the ratings of reviews, but do not provide a human-understandable explanation.
Radial Attention: $O(n\log n)$ Sparse Attention with Energy Decay for Long Video Generation
Jun 24, 2025Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with $O(n \log n)$ complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard $O(n^2)$ dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9$\times$ speedup over the original dense attention. With minimal tuning, it enables video generation up to 4$\times$ longer while reducing training costs by up to 4.4$\times$ compared to direct fine-tuning and accelerating inference by up to 3.7$\times$ compared to dense attention inference.
Probabilistic Aggregation and Targeted Embedding Optimization for Collective Moral Reasoning in Large Language Models
Jun 18, 2025Large Language Models (LLMs) have shown impressive moral reasoning abilities. Yet they often diverge when confronted with complex, multi-factor moral dilemmas. To address these discrepancies, we propose a framework that synthesizes multiple LLMs' moral judgments into a collectively formulated moral judgment, realigning models that deviate significantly from this consensus. Our aggregation mechanism fuses continuous moral acceptability scores (beyond binary labels) into a collective probability, weighting contributions by model reliability. For misaligned models, a targeted embedding-optimization procedure fine-tunes token embeddings for moral philosophical theories, minimizing JS divergence to the consensus while preserving semantic integrity. Experiments on a large-scale social moral dilemma dataset show our approach builds robust consensus and improves individual model fidelity. These findings highlight the value of data-driven moral alignment across multiple models and its potential for safer, more consistent AI systems.