 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptKG: A Prompt Learning Framework for Knowledge Graph Representation Learning and Application
Oct 01, 2022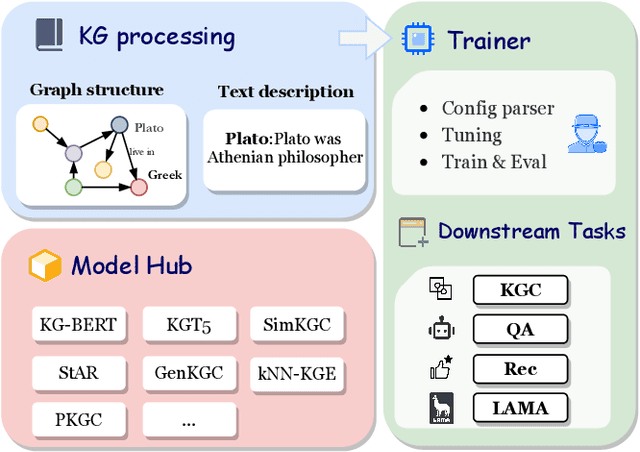
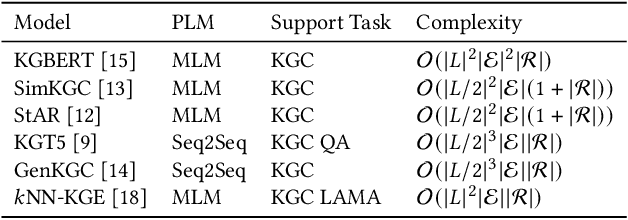
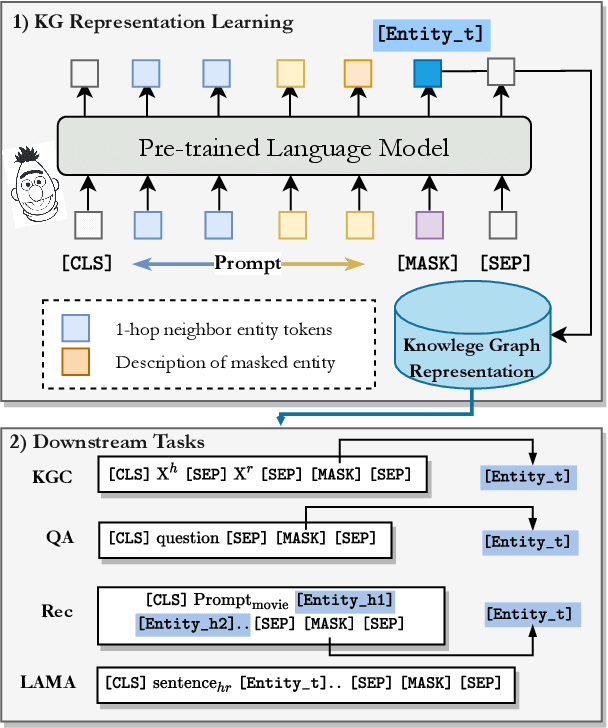
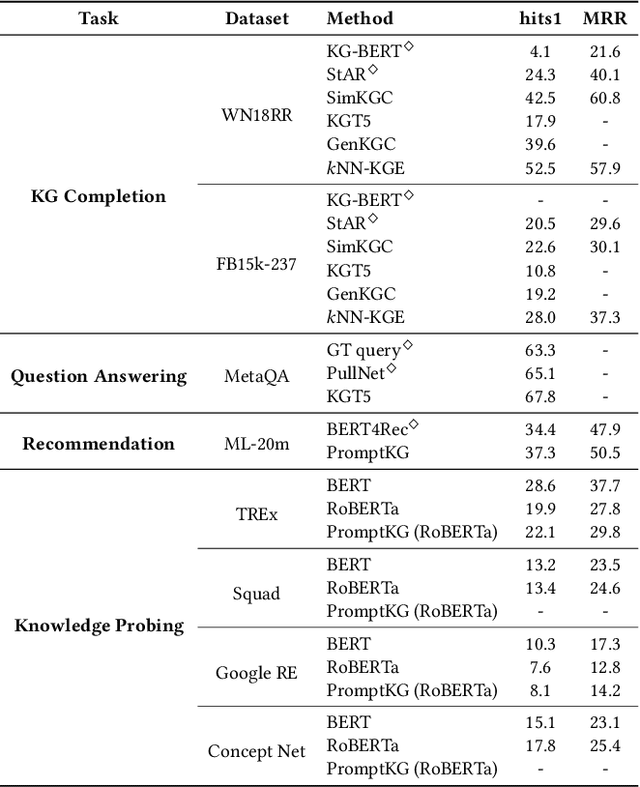
Knowledge Graphs (KGs) often have two characteristics: heterogeneous graph structure and text-rich entity/relation information. KG representation models should consider graph structures and text semantics, but no comprehensive open-sourced framework is mainly designed for KG regarding informative text description. In this paper, we present PromptKG, a prompt learning framework for KG representation learning and application that equips the cutting-edge text-based methods, integrates a new prompt learning model and supports various tasks (e.g., knowledge graph completion, question answering, recommendation, and knowledge probing). PromptKG is publicly open-sourced at https://github.com/zjunlp/PromptKG with long-term technical support.
Multimodal Analogical Reasoning over Knowledge Graphs
Oct 01, 2022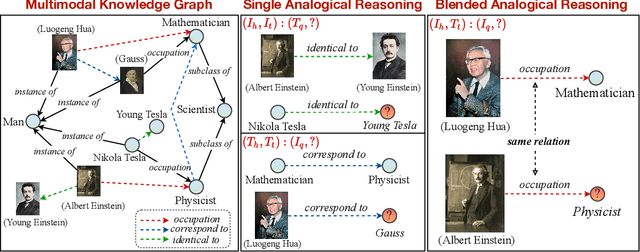

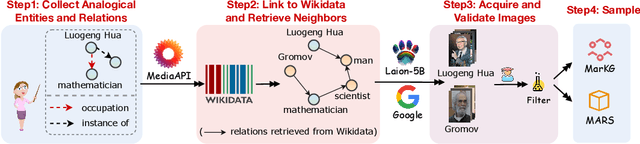
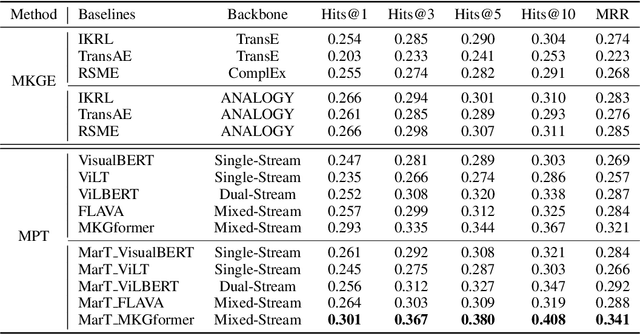
Analogical reasoning is fundamental to human cognition and holds an important place in various fields. However, previous studies mainly focus on single-modal analogical reasoning and ignore taking advantage of structure knowledge. Notably, the research in cognitive psychology has demonstrated that information from multimodal sources always brings more powerful cognitive transfer than single modality sources. To this end, we introduce the new task of multimodal analogical reasoning over knowledge graphs, which requires multimodal reasoning ability with the help of background knowledge. Specifically, we construct a Multimodal Analogical Reasoning dataSet (MARS) and a multimodal knowledge graph MarKG. We evaluate with multimodal knowledge graph embedding and pre-trained Transformer baselines, illustrating the potential challenges of the proposed task. We further propose a novel model-agnostic Multimodal analogical reasoning framework with Transformer (MarT) motivated by the structure mapping theory, which can obtain better performance.
Construction and Applications of Open Business Knowledge Graph
Sep 30, 2022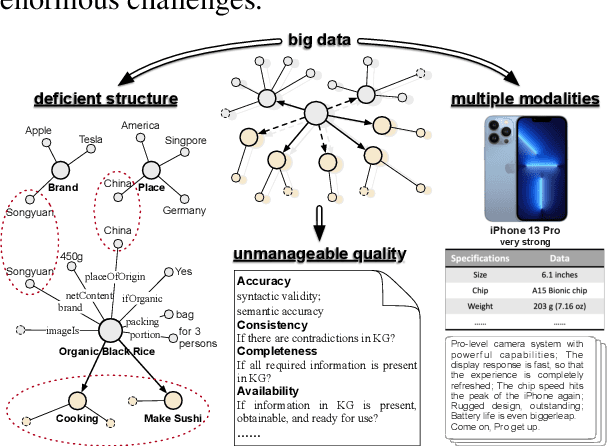

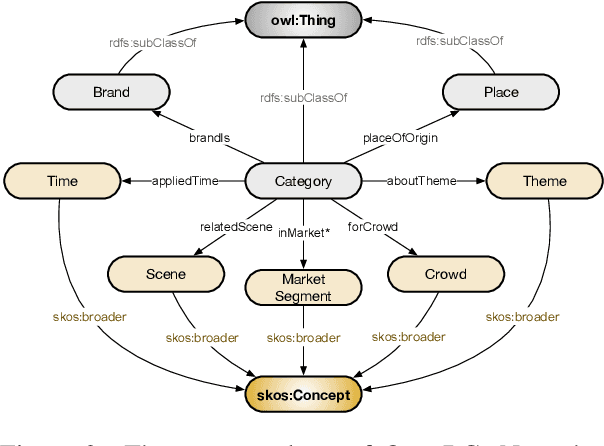
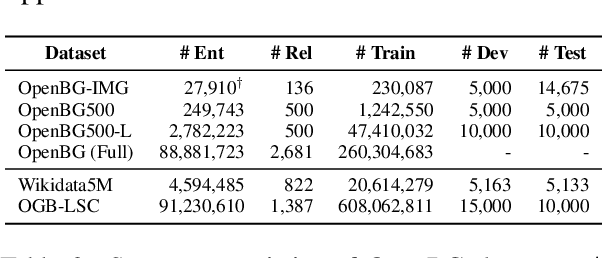
Business Knowledge Graph is important to many enterprises today, providing the factual knowledge and structured data that steer many products and make them more intelligent. Despite the welcome outcome, building business KG brings prohibitive issues of deficient structure, multiple modalities and unmanageable quality. In this paper, we advance the practical challenges related to building KG in non-trivial real-world systems. We introduce the process of building an open business knowledge graph (OpenBG) derived from a well-known enterprise. Specifically, we define a core ontology to cover various abstract products and consumption demands, with fine-grained taxonomy and multi-modal facts in deployed applications. OpenBG is ongoing, and the current version contains more than 2.6 billion triples with more than 88 million entities and 2,681 types of relations. We release all the open resources (OpenBG benchmark) derived from it for the community. We also report benchmark results with best learned lessons \url{https://github.com/OpenBGBenchmark/OpenBG}.
Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning
May 29, 2022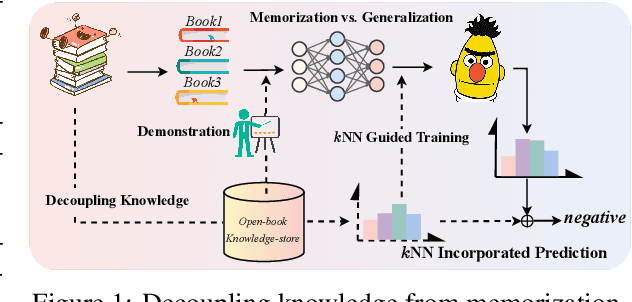
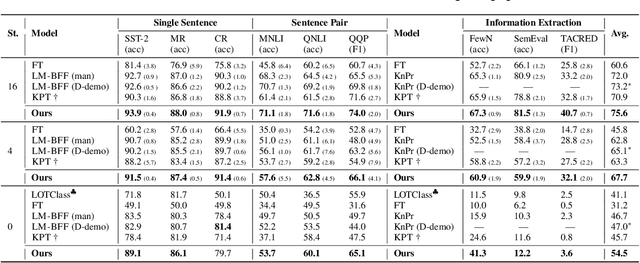
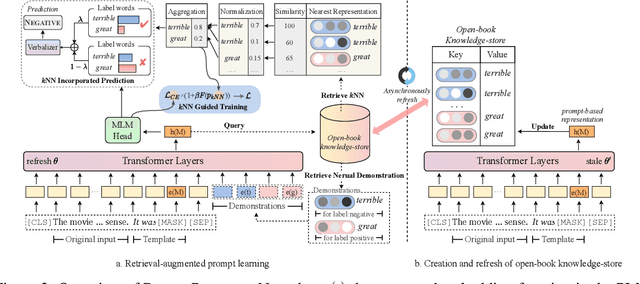
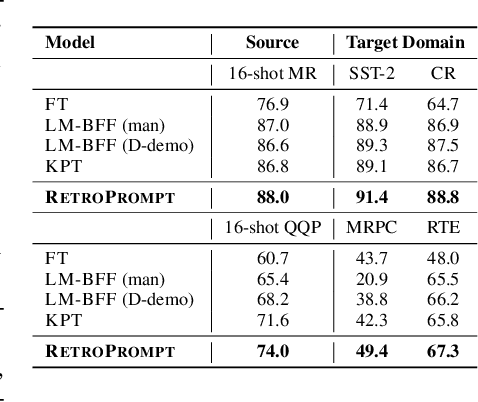
Prompt learning approaches have made waves in natural language processing by inducing better few-shot performance while they still follow a parametric-based learning paradigm; the oblivion and rote memorization problems in learning may encounter unstable generalization issues. Specifically, vanilla prompt learning may struggle to utilize atypical instances by rote during fully-supervised training or overfit shallow patterns with low-shot data. To alleviate such limitations, we develop RetroPrompt with the motivation of decoupling knowledge from memorization to help the model strike a balance between generalization and memorization. In contrast with vanilla prompt learning, RetroPrompt constructs an open-book knowledge-store from training instances and implements a retrieval mechanism during the process of input, training and inference, thus equipping the model with the ability to retrieve related contexts from the training corpus as cues for enhancement. Extensive experiments demonstrate that RetroPrompt can obtain better performance in both few-shot and zero-shot settings. Besides, we further illustrate that our proposed RetroPrompt can yield better generalization abilities with new datasets. Detailed analysis of memorization indeed reveals RetroPrompt can reduce the reliance of language models on memorization; thus, improving generalization for downstream tasks.
Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction
May 07, 2022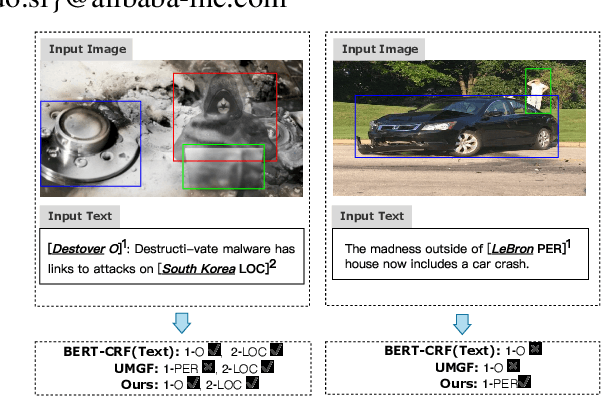
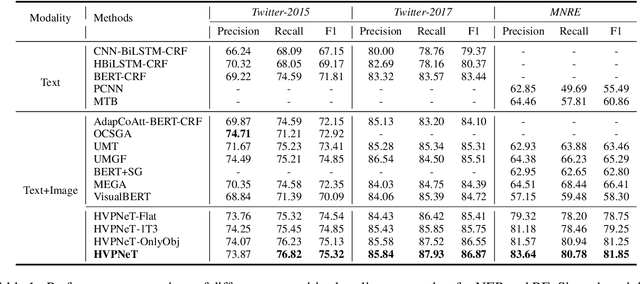
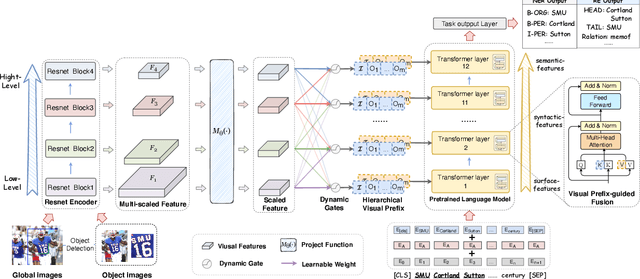

Multimodal named entity recognition and relation extraction (MNER and MRE) is a fundamental and crucial branch in information extraction. However, existing approaches for MNER and MRE usually suffer from error sensitivity when irrelevant object images incorporated in texts. To deal with these issues, we propose a novel Hierarchical Visual Prefix fusion NeTwork (HVPNeT) for visual-enhanced entity and relation extraction, aiming to achieve more effective and robust performance. Specifically, we regard visual representation as pluggable visual prefix to guide the textual representation for error insensitive forecasting decision. We further propose a dynamic gated aggregation strategy to achieve hierarchical multi-scaled visual features as visual prefix for fusion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our method, and achieve state-of-the-art performance. Code is available in https://github.com/zjunlp/HVPNeT.
Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion
May 04, 2022
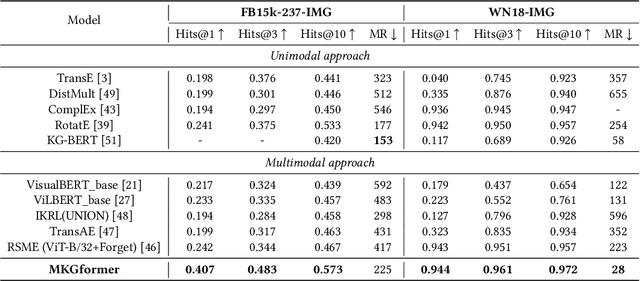
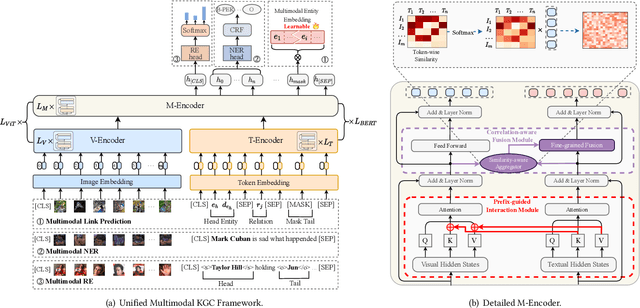
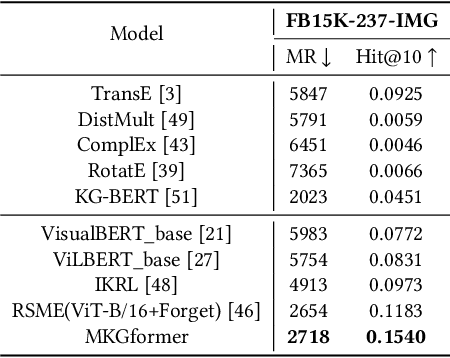
Multimodal Knowledge Graphs (MKGs), which organize visual-text factual knowledge, have recently been successfully applied to tasks such as information retrieval, question answering, and recommendation system. Since most MKGs are far from complete, extensive knowledge graph completion studies have been proposed focusing on the multimodal entity, relation extraction and link prediction. However, different tasks and modalities require changes to the model architecture, and not all images/objects are relevant to text input, which hinders the applicability to diverse real-world scenarios. In this paper, we propose a hybrid transformer with multi-level fusion to address those issues. Specifically, we leverage a hybrid transformer architecture with unified input-output for diverse multimodal knowledge graph completion tasks. Moreover, we propose multi-level fusion, which integrates visual and text representation via coarse-grained prefix-guided interaction and fine-grained correlation-aware fusion modules. We conduct extensive experiments to validate that our MKGformer can obtain SOTA performance on four datasets of multimodal link prediction, multimodal RE, and multimodal NER. Code is available in https://github.com/zjunlp/MKGformer.
Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective
Feb 16, 2022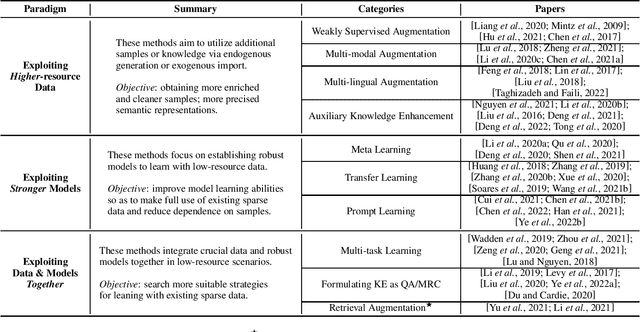
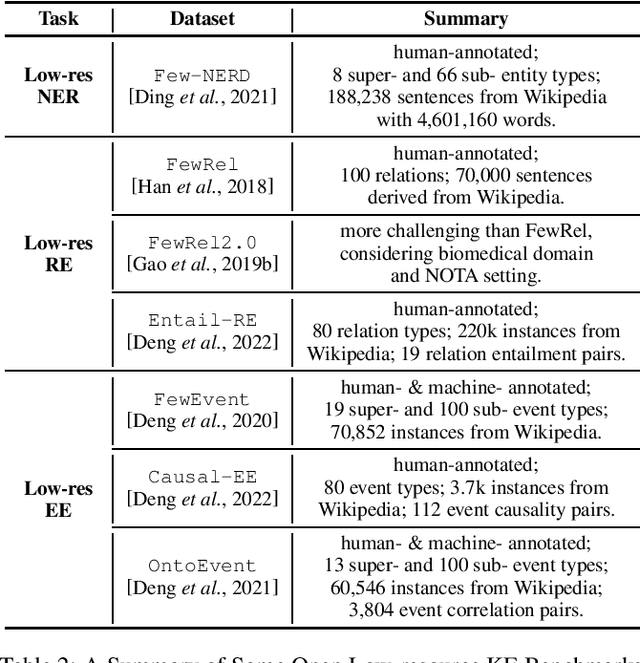
Knowledge Extraction (KE) which aims to extract structural information from unstructured texts often suffers from data scarcity and emerging unseen types, i.e., low-resource scenarios. Many neural approaches on low-resource KE have been widely investigated and achieved impressive performance. In this paper, we present a literature review towards KE in low-resource scenarios, and systematically categorize existing works into three paradigms: (1) exploiting higher-resource data, (2) exploiting stronger models, and (3) exploiting data and models together. In addition, we describe promising applications and outline some potential directions for future research. We hope that our survey can help both the academic and industrial community to better understand this field, inspire more ideas and boost broader applications.
From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer
Feb 08, 2022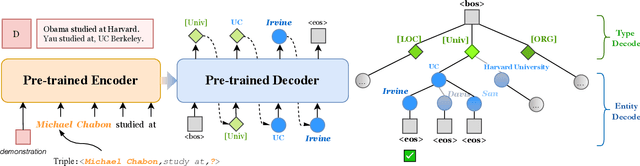

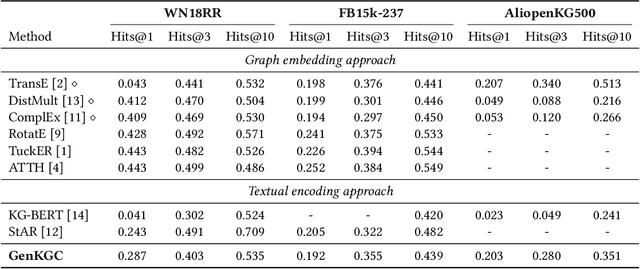
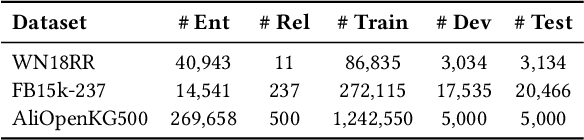
Knowledge graph completion aims to address the problem of extending a KG with missing triples. In this paper, we provide an approach GenKGC, which converts knowledge graph completion to sequence-to-sequence generation task with the pre-trained language model. We further introduce relation-guided demonstration and entity-aware hierarchical decoding for better representation learning and fast inference. Experimental results on three datasets show that our approach can obtain better or comparable performance than baselines and achieve faster inference speed compared with previous methods with pre-trained language models. We also release a new large-scale Chinese knowledge graph dataset AliopenKG500 for research purpose. Code and datasets are available in https://github.com/zjunlp/PromptKGC/tree/main/GenKGC.
Ontology-enhanced Prompt-tuning for Few-shot Learning
Jan 27, 2022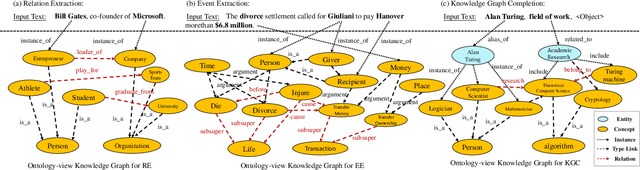
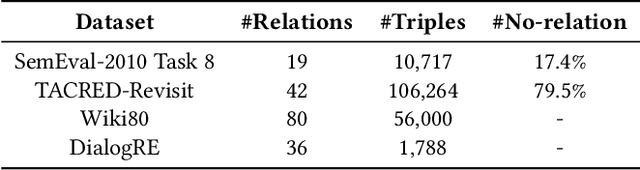
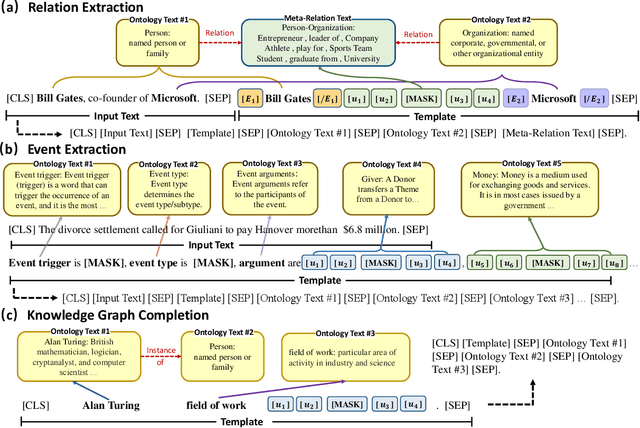
Few-shot Learning (FSL) is aimed to make predictions based on a limited number of samples. Structured data such as knowledge graphs and ontology libraries has been leveraged to benefit the few-shot setting in various tasks. However, the priors adopted by the existing methods suffer from challenging knowledge missing, knowledge noise, and knowledge heterogeneity, which hinder the performance for few-shot learning. In this study, we explore knowledge injection for FSL with pre-trained language models and propose ontology-enhanced prompt-tuning (OntoPrompt). Specifically, we develop the ontology transformation based on the external knowledge graph to address the knowledge missing issue, which fulfills and converts structure knowledge to text. We further introduce span-sensitive knowledge injection via a visible matrix to select informative knowledge to handle the knowledge noise issue. To bridge the gap between knowledge and text, we propose a collective training algorithm to optimize representations jointly. We evaluate our proposed OntoPrompt in three tasks, including relation extraction, event extraction, and knowledge graph completion, with eight datasets. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
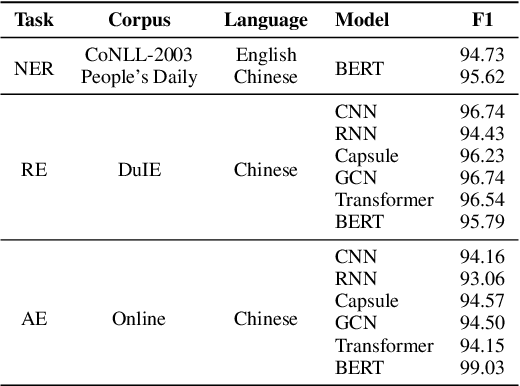
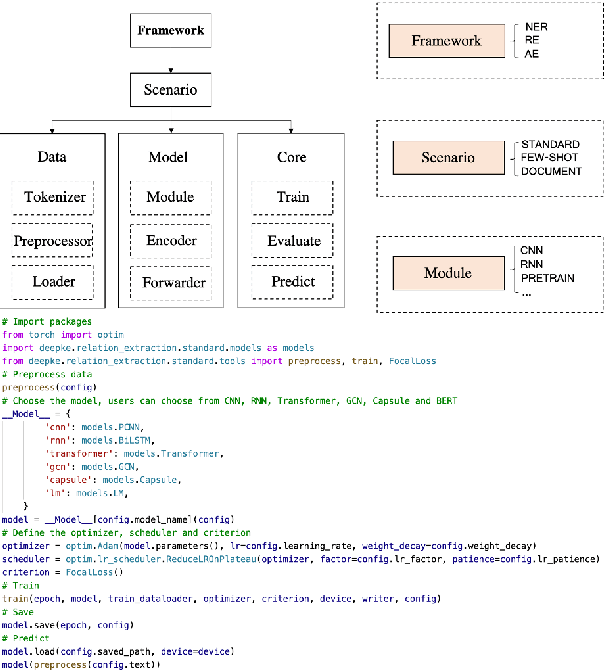
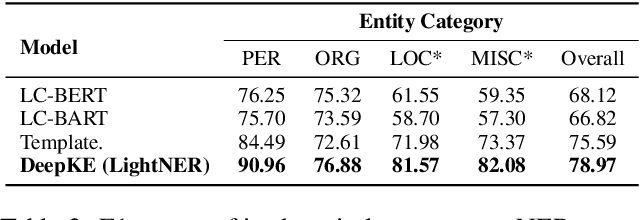
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.