 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast DenseNet: Towards Efficient and Accurate Text Recognition with Fast Dense Networks
Dec 15, 2019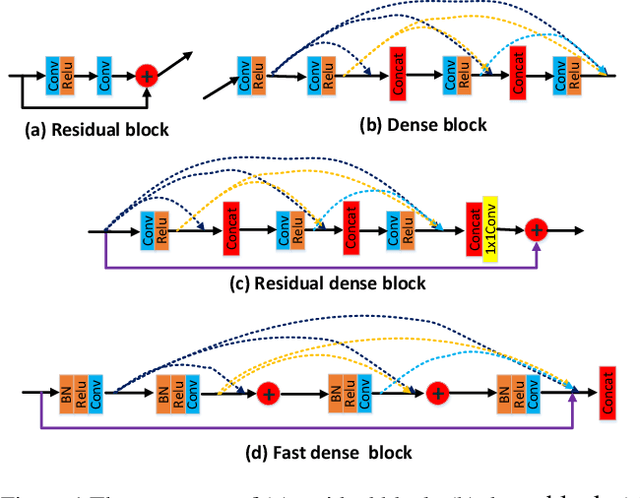

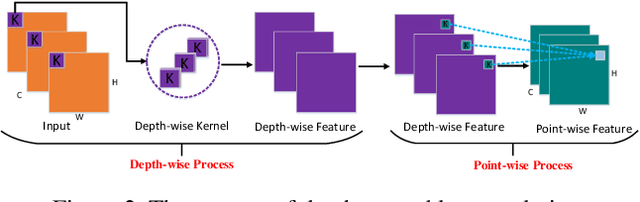
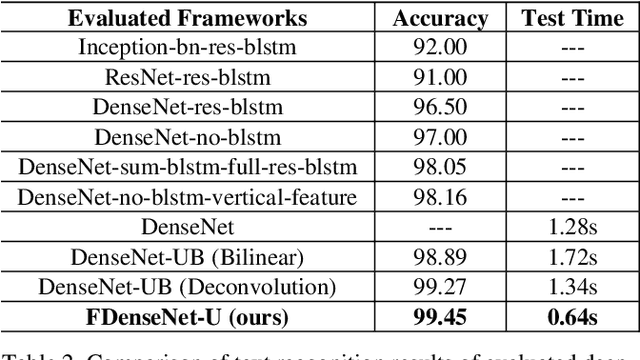
Convolutional Recurrent Neural Network (CRNN) is a popular network for recognizing texts in images. Advances like the variants of CRNN, such as Dense Convolutional Network with Connectionist Temporal Classification, has reduced the running time of the networks, but exposing the inner computation cost of the convolutional networks as a bottleneck. Specifically, DenseNet based frameworks use the dense blocks as the core module, but the inner features are combined in the form of concatenation in dense blocks. As a result, the number of channels of combined features delivered as the input of the layers close to the output and the relevant computational cost grows rapidly with the dense blocks getting deeper. This will severely bring heavy computational cost and restrict the depth of dense blocks. In this paper, we propose an efficient convolutional block called Fast Dense Block (FDB). To reduce the computing cost, we redefine and design the way of combining internal features of dense blocks. FDB is a convolutional block similarly as the dense block, but it applies both sum and concatenating operations to connect the inner features in blocks, which can reduce the computation cost to (1/L, 2/L), compared with the original dense block, where L is the number of layers in the dense block. Importantly, since the parameters of standard dense block and our new FDB keep consistent except the way of combining features, and their inputs and outputs have the same size and same number of channels, so FDB can be easily used to replace the original dense block in any DenseNet based framework. Based on the designed FDBs, we further propose a fast network of DenseNet to improve the text recognition performance in images.
Efficient Differentiable Neural Architecture Search with Meta Kernels
Dec 10, 2019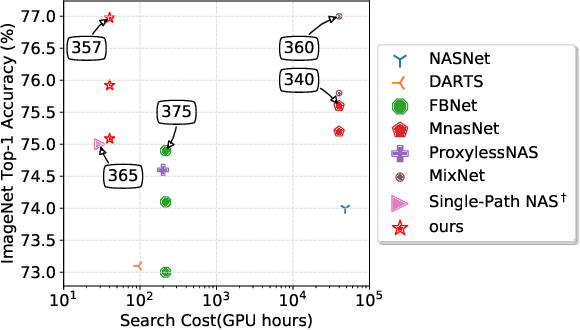
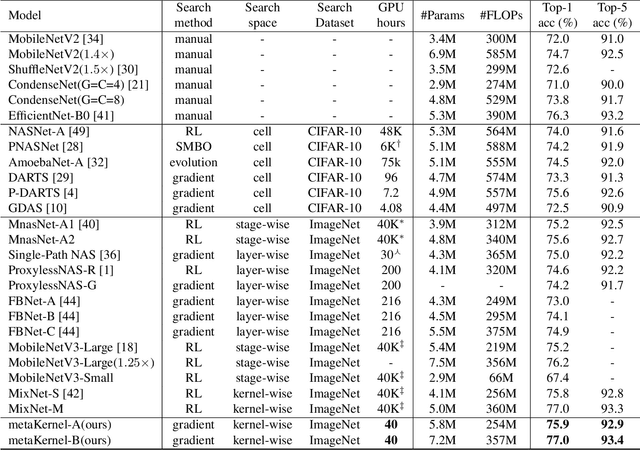
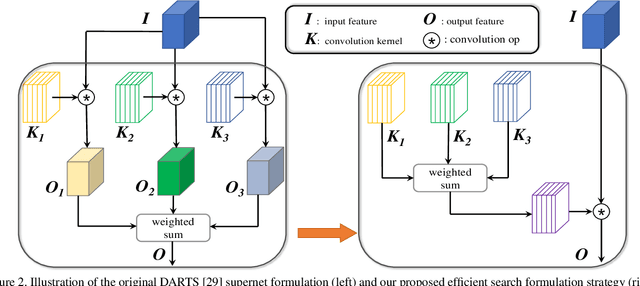

The searching procedure of neural architecture search (NAS) is notoriously time consuming and cost prohibitive.To make the search space continuous, most existing gradient-based NAS methods relax the categorical choice of a particular operation to a softmax over all possible operations and calculate the weighted sum of multiple features, resulting in a large memory requirement and a huge computation burden. In this work, we propose an efficient and novel search strategy with meta kernels. We directly encode the supernet from the perspective on convolution kernels and "shrink" multiple convolution kernel candidates into a single one before these candidates operate on the input feature. In this way, only a single feature is generated between two intermediate nodes. The memory for storing intermediate features and the resource budget for conducting convolution operations are both reduced remarkably. Despite high efficiency, our search strategy can search in a more fine-grained way than existing works and increases the capacity for representing possible networks. We demonstrate the effectiveness of our search strategy by conducting extensive experiments. Specifically, our method achieves 77.0% top-1 accuracy on ImageNet benchmark dataset with merely 357M FLOPs, outperforming both EfficientNet and MobileNetV3 under the same FLOPs constraints. Compared to models discovered by the start-of-the-art NAS method, our method achieves the same (sometimes even better) performance, while faster by three orders of magnitude.
AdversarialNAS: Adversarial Neural Architecture Search for GANs
Dec 04, 2019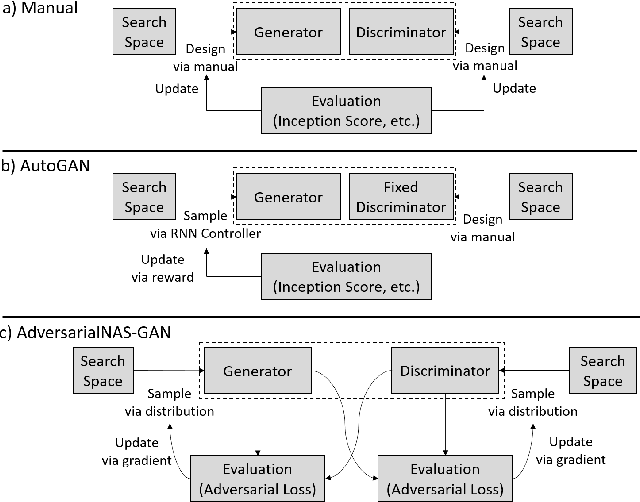
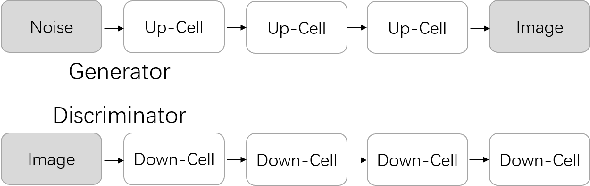
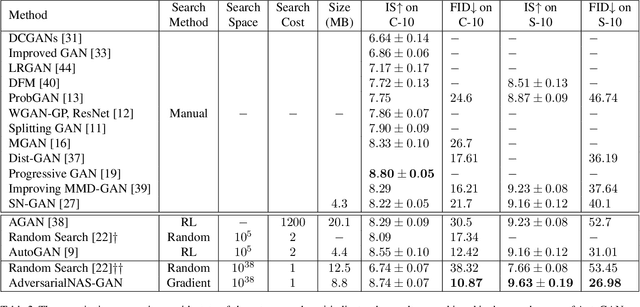
Neural Architecture Search (NAS) that aims to automate the procedure of architecture design has achieved promising results in many computer vision fields. In this paper, we propose an AdversarialNAS method specially tailored for Generative Adversarial Networks (GANs) to search for a superior generative model on the task of unconditional image generation. The proposed method leverages an adversarial searching mechanism to search for the architectures of generator and discriminator simultaneously in a differentiable manner. Therefore, the searching algorithm considers the relevance and balance between the two networks leading to search for a superior generative model. Besides, AdversarialNAS does not need any extra evaluation metric to evaluate the performance of the architecture in each searching iteration, which is very efficient and can take only 1 GPU day to search for an optimal network architecture in a large search space ($10^{38}$). Experiments demonstrate the effectiveness and superiority of our method. The discovered generative model sets a new state-of-the-art FID score of $10.87$ and highly competitive Inception Score of $8.74$ on CIFAR-10. Its transferability is also proven by setting new state-of-the-art FID score of $26.98$ and Inception score of $9.63$ on STL-10. Our code will be released to facilitate the related academic and industrial study.
Discriminative Local Sparse Representation by Robust Adaptive Dictionary Pair Learning
Nov 20, 2019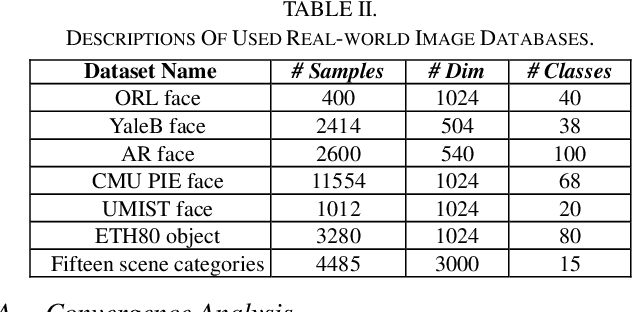
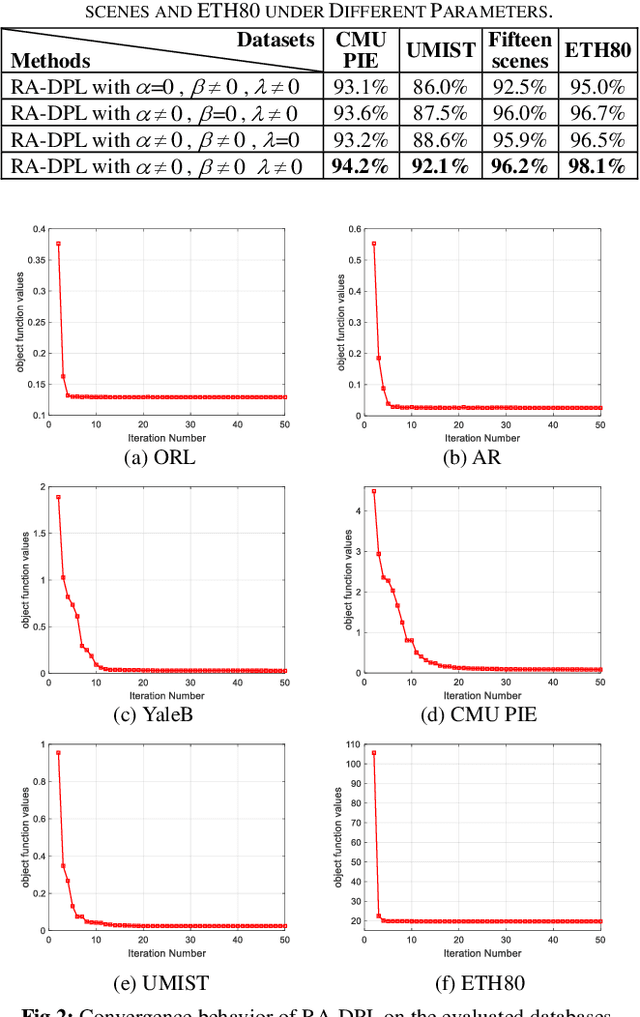

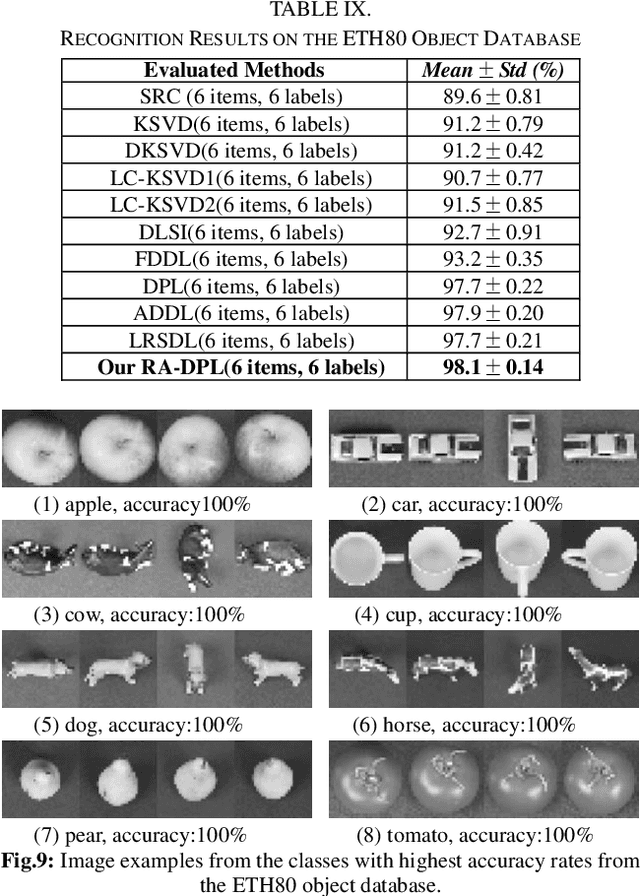
In this paper, we propose a structured Robust Adaptive Dic-tionary Pair Learning (RA-DPL) framework for the discrim-inative sparse representation learning. To achieve powerful representation ability of the available samples, the setting of RA-DPL seamlessly integrates the robust projective dictionary pair learning, locality-adaptive sparse representations and discriminative coding coefficients learning into a unified learning framework. Specifically, RA-DPL improves existing projective dictionary pair learning in four perspectives. First, it applies a sparse l2,1-norm based metric to encode the recon-struction error to deliver the robust projective dictionary pairs, and the l2,1-norm has the potential to minimize the error. Sec-ond, it imposes the robust l2,1-norm clearly on the analysis dictionary to ensure the sparse property of the coding coeffi-cients rather than using the costly l0/l1-norm. As such, the robustness of the data representation and the efficiency of the learning process are jointly considered to guarantee the effi-cacy of our RA-DPL. Third, RA-DPL conceives a structured reconstruction weight learning paradigm to preserve the local structures of the coding coefficients within each class clearly in an adaptive manner, which encourages to produce the locality preserving representations. Fourth, it also considers improving the discriminating ability of coding coefficients and dictionary by incorporating a discriminating function, which can ensure high intra-class compactness and inter-class separation in the code space. Extensive experiments show that our RA-DPL can obtain superior performance over other state-of-the-arts.
PSGAN: Pose-Robust Spatial-Aware GAN for Customizable Makeup Transfer
Sep 16, 2019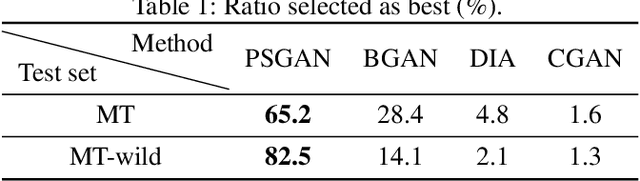
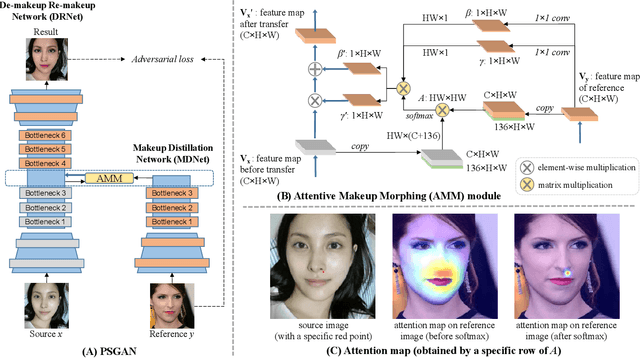


We propose a novel Pose-robust Spatial-aware GAN (PSGAN) for transferring the makeup style from a reference image to a source image. Previous GAN-based methods often fail in cases with variant poses and expressions. Also, they cannot adjust the shade of makeup or specify the part of transfer. To address these issues, the proposed PSGAN includes a Makeup Distillation Network to distill the makeup style of the reference image into two spatial-aware makeup matrices. Then an Attentive Makeup Morphing module is introduced to specify how a pixel in the source image is morphed from the reference image. The pixelwise correspondence is built upon both the relative position features and visual features. Based on the morphed makeup matrices, a De-makeup Re-makeup Network performs makeup transfer. By incorporating the above novelties, our PSGAN not only achieves state-of-the-art results on the existing datasets, but also is able to perform the customizable part-by-part, shade controllable and pose-robust makeup transfer.
Flexible Auto-weighted Local-coordinate Concept Factorization: A Robust Framework for Unsupervised Clustering
Sep 02, 2019
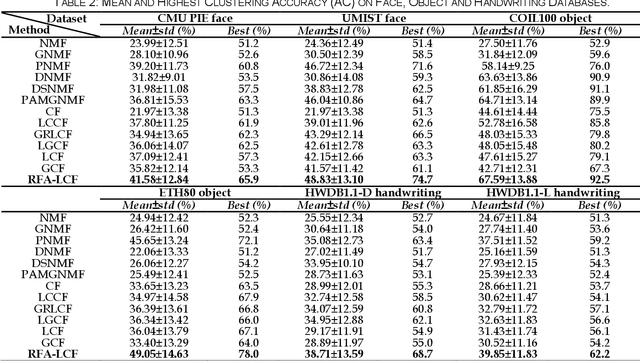
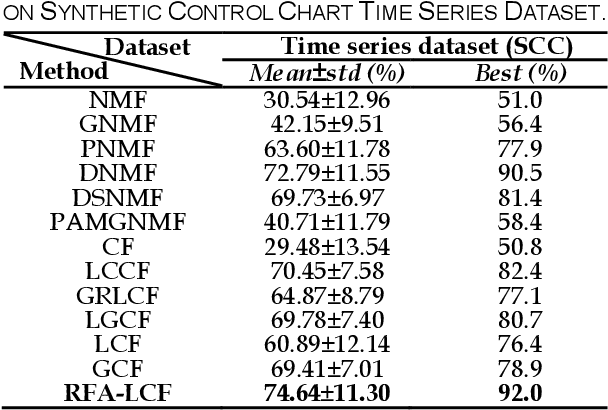

Concept Factorization (CF) and its variants may produce inaccurate representation and clustering results due to the sensitivity to noise, hard constraint on the reconstruction error and pre-obtained approximate similarities. To improve the representation ability, a novel unsupervised Robust Flexible Auto-weighted Local-coordinate Concept Factorization (RFA-LCF) framework is proposed for clustering high-dimensional data. Specifically, RFA-LCF integrates the robust flexible CF by clean data space recovery, robust sparse local-coordinate coding and adaptive weighting into a unified model. RFA-LCF improves the representations by enhancing the robustness of CF to noise and errors, providing a flexible constraint on the reconstruction error and optimizing the locality jointly. For robust learning, RFA-LCF clearly learns a sparse projection to recover the underlying clean data space, and then the flexible CF is performed in the projected feature space. RFA-LCF also uses a L2,1-norm based flexible residue to encode the mismatch between the recovered data and its reconstruction, and uses the robust sparse local-coordinate coding to represent data using a few nearby basis concepts. For auto-weighting, RFA-LCF jointly preserves the manifold structures in the basis concept space and new coordinate space in an adaptive manner by minimizing the reconstruction errors on clean data, anchor points and coordinates. By updating the local-coordinate preserving data, basis concepts and new coordinates alternately, the representation abilities can be potentially improved. Extensive results on public databases show that RFA-LCF delivers the state-of-the-art clustering results compared with other related methods.
Single-Stage Multi-Person Pose Machines
Aug 24, 2019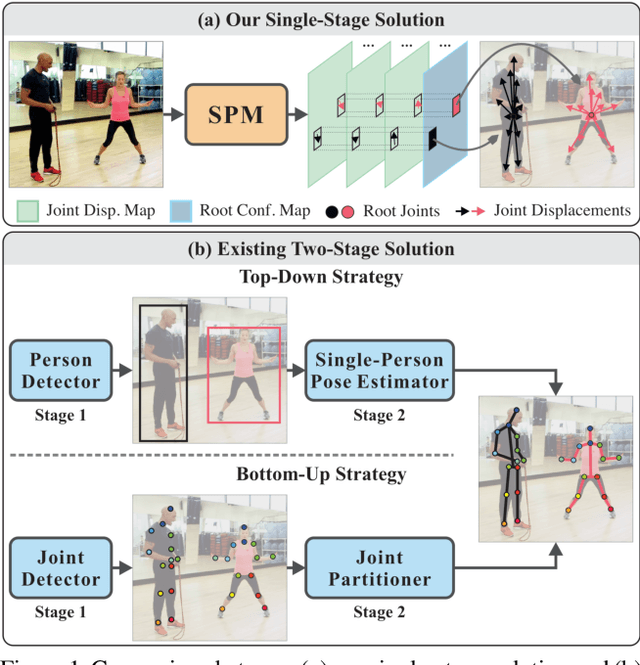
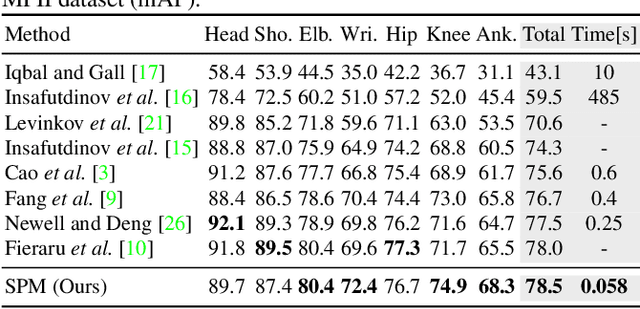
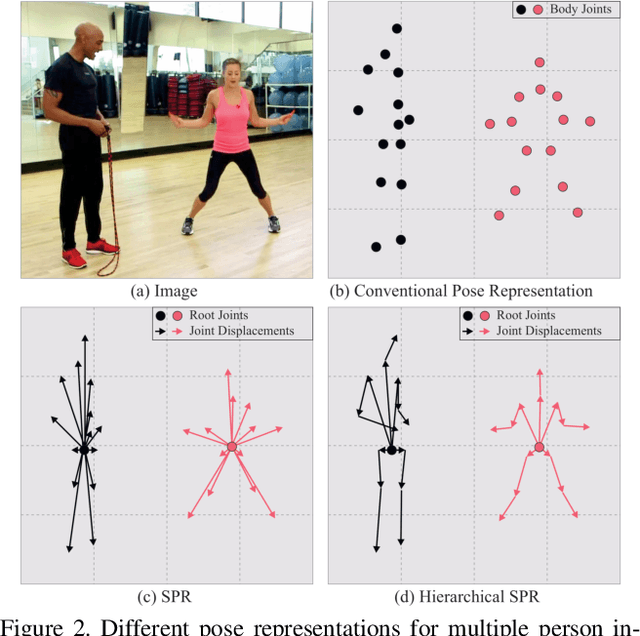

Multi-person pose estimation is a challenging problem. Existing methods are mostly two-stage based--one stage for proposal generation and the other for allocating poses to corresponding persons. However, such two-stage methods generally suffer low efficiency. In this work, we present the first single-stage model, Single-stage multi-person Pose Machine (SPM), to simplify the pipeline and lift the efficiency for multi-person pose estimation. To achieve this, we propose a novel Structured Pose Representation (SPR) that unifies person instance and body joint position representations. Based on SPR, we develop the SPM model that can directly predict structured poses for multiple persons in a single stage, and thus offer a more compact pipeline and attractive efficiency advantage over two-stage methods. In particular, SPR introduces the root joints to indicate different person instances and human body joint positions are encoded into their displacements w.r.t. the roots. To better predict long-range displacements for some joints, SPR is further extended to hierarchical representations. Based on SPR, SPM can efficiently perform multi-person poses estimation by simultaneously predicting root joints (location of instances) and body joint displacements via CNNs. Moreover, to demonstrate the generality of SPM, we also apply it to multi-person 3D pose estimation. Comprehensive experiments on benchmarks MPII, extended PASCAL-Person-Part, MSCOCO and CMU Panoptic clearly demonstrate the state-of-the-art efficiency of SPM for multi-person 2D/3D pose estimation, together with outstanding accuracy.
Joint Subspace Recovery and Enhanced Locality Driven Robust Flexible Discriminative Dictionary Learning
Jun 11, 2019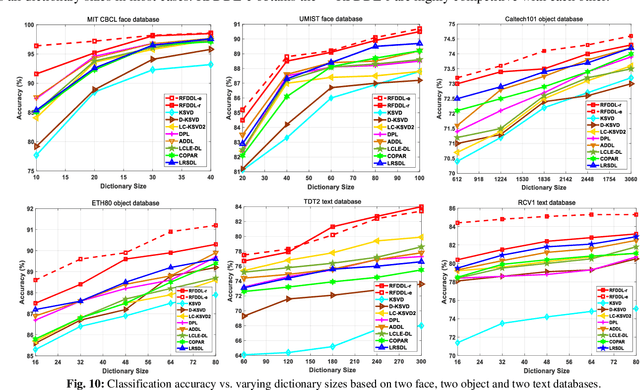
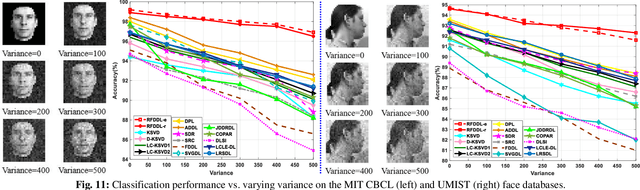
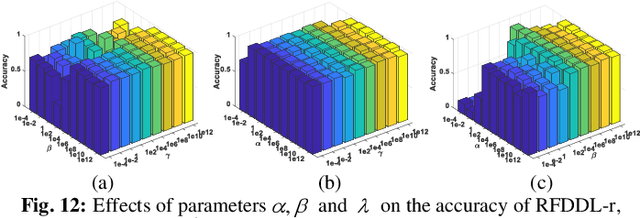
We propose a joint subspace recovery and enhanced locality based robust flexible label consistent dictionary learning method called Robust Flexible Discriminative Dictionary Learning (RFDDL). RFDDL mainly improves the data representation and classification abilities by enhancing the robust property to sparse errors and encoding the locality, reconstruction error and label consistency more accurately. First, for the robustness to noise and sparse errors in data and atoms, RFDDL aims at recovering the underlying clean data and clean atom subspaces jointly, and then performs DL and encodes the locality in the recovered subspaces. Second, to enable the data sampled from a nonlinear manifold to be handled potentially and obtain the accurate reconstruction by avoiding the overfitting, RFDDL minimizes the reconstruction error in a flexible manner. Third, to encode the label consistency accurately, RFDDL involves a discriminative flexible sparse code error to encourage the coefficients to be soft. Fourth, to encode the locality well, RFDDL defines the Laplacian matrix over recovered atoms, includes label information of atoms in terms of intra-class compactness and inter-class separation, and associates with group sparse codes and classifier to obtain the accurate discriminative locality-constrained coefficients and classifier. Extensive results on public databases show the effectiveness of our RFDDL.
Kernel-Induced Label Propagation by Mapping for Semi-Supervised Classification
May 31, 2019
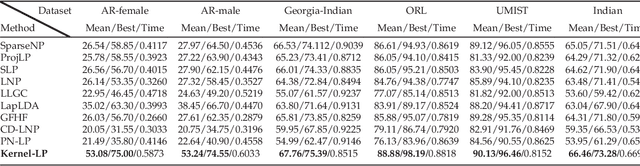
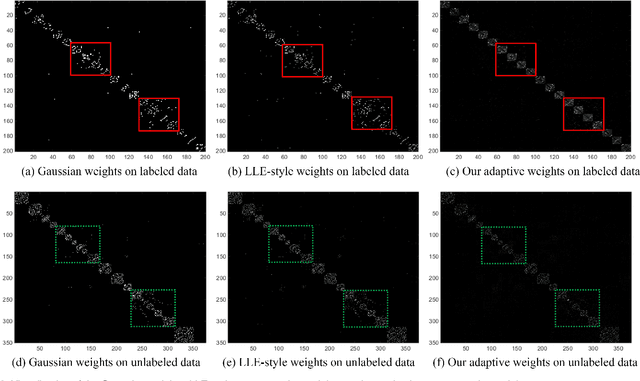
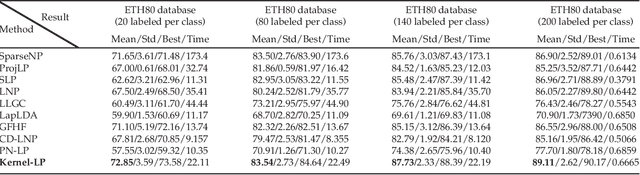
Kernel methods have been successfully applied to the areas of pattern recognition and data mining. In this paper, we mainly discuss the issue of propagating labels in kernel space. A Kernel-Induced Label Propagation (Kernel-LP) framework by mapping is proposed for high-dimensional data classification using the most informative patterns of data in kernel space. The essence of Kernel-LP is to perform joint label propagation and adaptive weight learning in a transformed kernel space. That is, our Kernel-LP changes the task of label propagation from the commonly-used Euclidean space in most existing work to kernel space. The motivation of our Kernel-LP to propagate labels and learn the adaptive weights jointly by the assumption of an inner product space of inputs, i.e., the original linearly inseparable inputs may be mapped to be separable in kernel space. Kernel-LP is based on existing positive and negative LP model, i.e., the effects of negative label information are integrated to improve the label prediction power. Also, Kernel-LP performs adaptive weight construction over the same kernel space, so it can avoid the tricky process of choosing the optimal neighborhood size suffered in traditional criteria. Two novel and efficient out-of-sample approaches for our Kernel-LP to involve new test data are also presented, i.e., (1) direct kernel mapping and (2) kernel mapping-induced label reconstruction, both of which purely depend on the kernel matrix between training set and testing set. Owing to the kernel trick, our algorithms will be applicable to handle the high-dimensional real data. Extensive results on real datasets demonstrate the effectiveness of our approach.
Jointly Learning Structured Analysis Discriminative Dictionary and Analysis Multiclass Classifier
May 27, 2019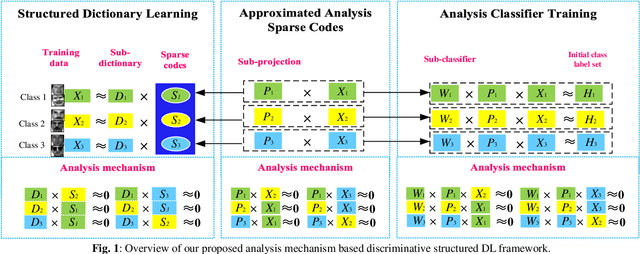
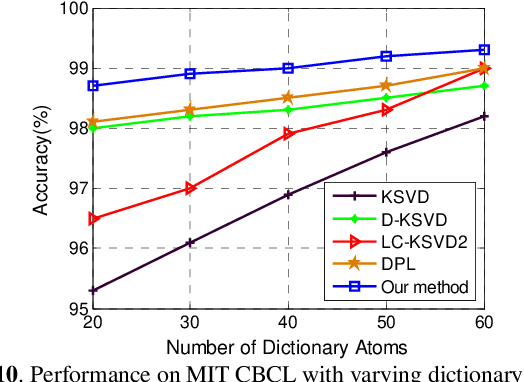
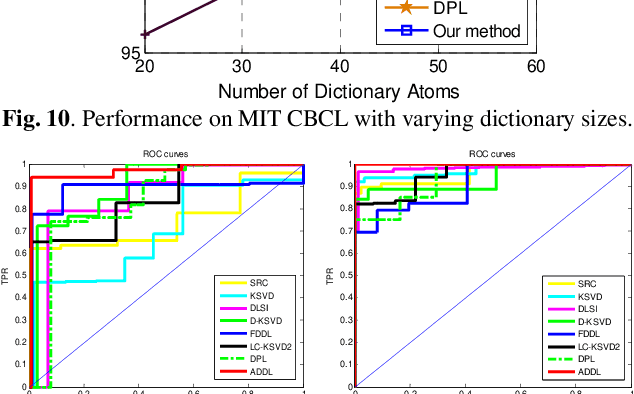

In this paper, we propose an analysis mechanism based structured Analysis Discriminative Dictionary Learning (ADDL) framework. ADDL seamlessly integrates the analysis discriminative dictionary learning, analysis representation and analysis classifier training into a unified model. The applied analysis mechanism can make sure that the learnt dictionaries, representations and linear classifiers over different classes are independent and discriminating as much as possible. The dictionary is obtained by minimizing a reconstruction error and an analytical incoherence promoting term that encourages the sub-dictionaries associated with different classes to be independent. To obtain the representation coefficients, ADDL imposes a sparse l2,1-norm constraint on the coding coefficients instead of using l0 or l1-norm, since the l0 or l1-norm constraint applied in most existing DL criteria makes the training phase time consuming. The codes-extraction projection that bridges data with the sparse codes by extracting special features from the given samples is calculated via minimizing a sparse codes approximation term. Then we compute a linear classifier based on the approximated sparse codes by an analysis mechanism to simultaneously consider the classification and representation powers. Thus, the classification approach of our model is very efficient, because it can avoid the extra time-consuming sparse reconstruction process with trained dictionary for each new test data as most existing DL algorithms. Simulations on real image databases demonstrate that our ADDL model can obtain superior performance over other state-of-the-arts.