 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPRSteg: Printing and Photography Robust QR Code Steganography via Attention Flow-Based Model
May 26, 2024



Image steganography can hide information in a host image and obtain a stego image that is perceptually indistinguishable from the original one. This technique has tremendous potential in scenarios like copyright protection, information retrospection, etc. Some previous studies have proposed to enhance the robustness of the methods against image disturbances to increase their applicability. However, they generally cannot achieve a satisfying balance between the steganography quality and robustness. In this paper, we focus on the issue of QR Code steganography that is robust to real-world printing and photography. Different from common image steganography, QR Code steganography aims to embed a non-natural image into a natural image and the restored QR Code is required to be recognizable, which increases the difficulty of data concealing and revealing. Inspired by the recent developments in transformer-based vision models, we discover that the tokenized representation of images is naturally suitable for steganography. In this paper, we propose a novel QR Code embedding framework, called Printing and Photography Robust Steganography (PPRSteg), which is competent to hide QR Code in a host image with unperceivable changes and can restore it even if the stego image is printed out and photoed. We outline a transition process to reduce the artifacts in stego images brought by QR Codes. We also propose a steganography model based on normalizing flow, which combines the attention mechanism to enhance its performance. To our best knowledge, this is the first work that integrates the advantages of transformer models into normalizing flow. We conduct comprehensive and detailed experiments to demonstrate the effectiveness of our method and the result shows that PPRSteg has great potential in robust, secure and high-quality QR Code steganography.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024



This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Improved Implicit Neural Representation with Fourier Bases Reparameterized Training
Feb 05, 2024



Implicit Neural Representation (INR) as a mighty representation paradigm has achieved success in various computer vision tasks recently. Due to the low-frequency bias issue of vanilla multi-layer perceptron (MLP), existing methods have investigated advanced techniques, such as positional encoding and periodic activation function, to improve the accuracy of INR. In this paper, we connect the network training bias with the reparameterization technique and theoretically prove that weight reparameterization could provide us a chance to alleviate the spectral bias of MLP. Based on our theoretical analysis, we propose a Fourier reparameterization method which learns coefficient matrix of fixed Fourier bases to compose the weights of MLP. We evaluate the proposed Fourier reparameterization method on different INR tasks with various MLP architectures, including vanilla MLP, MLP with positional encoding and MLP with advanced activation function, etc. The superiority approximation results on different MLP architectures clearly validate the advantage of our proposed method. Armed with our Fourier reparameterization method, better INR with more textures and less artifacts can be learned from the training data.
Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary
Jan 18, 2024



Single Image Super-Resolution is a classic computer vision problem that involves estimating high-resolution (HR) images from low-resolution (LR) ones. Although deep neural networks (DNNs), especially Transformers for super-resolution, have seen significant advancements in recent years, challenges still remain, particularly in limited receptive field caused by window-based self-attention. To address these issues, we introduce a group of auxiliary Adaptive Token Dictionary to SR Transformer and establish an ATD-SR method. The introduced token dictionary could learn prior information from training data and adapt the learned prior to specific testing image through an adaptive refinement step. The refinement strategy could not only provide global information to all input tokens but also group image tokens into categories. Based on category partitions, we further propose a category-based self-attention mechanism designed to leverage distant but similar tokens for enhancing input features. The experimental results show that our method achieves the best performance on various single image super-resolution benchmarks.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024



Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
Learning Motion Refinement for Unsupervised Face Animation
Oct 21, 2023Unsupervised face animation aims to generate a human face video based on the appearance of a source image, mimicking the motion from a driving video. Existing methods typically adopted a prior-based motion model (e.g., the local affine motion model or the local thin-plate-spline motion model). While it is able to capture the coarse facial motion, artifacts can often be observed around the tiny motion in local areas (e.g., lips and eyes), due to the limited ability of these methods to model the finer facial motions. In this work, we design a new unsupervised face animation approach to learn simultaneously the coarse and finer motions. In particular, while exploiting the local affine motion model to learn the global coarse facial motion, we design a novel motion refinement module to compensate for the local affine motion model for modeling finer face motions in local areas. The motion refinement is learned from the dense correlation between the source and driving images. Specifically, we first construct a structure correlation volume based on the keypoint features of the source and driving images. Then, we train a model to generate the tiny facial motions iteratively from low to high resolution. The learned motion refinements are combined with the coarse motion to generate the new image. Extensive experiments on widely used benchmarks demonstrate that our method achieves the best results among state-of-the-art baselines.
Single Image Depth Prediction Made Better: A Multivariate Gaussian Take
Apr 18, 2023Neural-network-based single image depth prediction (SIDP) is a challenging task where the goal is to predict the scene's per-pixel depth at test time. Since the problem, by definition, is ill-posed, the fundamental goal is to come up with an approach that can reliably model the scene depth from a set of training examples. In the pursuit of perfect depth estimation, most existing state-of-the-art learning techniques predict a single scalar depth value per-pixel. Yet, it is well-known that the trained model has accuracy limits and can predict imprecise depth. Therefore, an SIDP approach must be mindful of the expected depth variations in the model's prediction at test time. Accordingly, we introduce an approach that performs continuous modeling of per-pixel depth, where we can predict and reason about the per-pixel depth and its distribution. To this end, we model per-pixel scene depth using a multivariate Gaussian distribution. Moreover, contrary to the existing uncertainty modeling methods -- in the same spirit, where per-pixel depth is assumed to be independent, we introduce per-pixel covariance modeling that encodes its depth dependency w.r.t all the scene points. Unfortunately, per-pixel depth covariance modeling leads to a computationally expensive continuous loss function, which we solve efficiently using the learned low-rank approximation of the overall covariance matrix. Notably, when tested on benchmark datasets such as KITTI, NYU, and SUN-RGB-D, the SIDP model obtained by optimizing our loss function shows state-of-the-art results. Our method's accuracy (named MG) is among the top on the KITTI depth-prediction benchmark leaderboard.
VA-DepthNet: A Variational Approach to Single Image Depth Prediction
Feb 15, 2023



We introduce VA-DepthNet, a simple, effective, and accurate deep neural network approach for the single-image depth prediction (SIDP) problem. The proposed approach advocates using classical first-order variational constraints for this problem. While state-of-the-art deep neural network methods for SIDP learn the scene depth from images in a supervised setting, they often overlook the invaluable invariances and priors in the rigid scene space, such as the regularity of the scene. The paper's main contribution is to reveal the benefit of classical and well-founded variational constraints in the neural network design for the SIDP task. It is shown that imposing first-order variational constraints in the scene space together with popular encoder-decoder-based network architecture design provides excellent results for the supervised SIDP task. The imposed first-order variational constraint makes the network aware of the depth gradient in the scene space, i.e., regularity. The paper demonstrates the usefulness of the proposed approach via extensive evaluation and ablation analysis over several benchmark datasets, such as KITTI, NYU Depth V2, and SUN RGB-D. The VA-DepthNet at test time shows considerable improvements in depth prediction accuracy compared to the prior art and is accurate also at high-frequency regions in the scene space. At the time of writing this paper, our method -- labeled as VA-DepthNet, when tested on the KITTI depth-prediction evaluation set benchmarks, shows state-of-the-art results, and is the top-performing published approach.
Measuring Perceptual Color Differences of Smartphone Photography
May 26, 2022

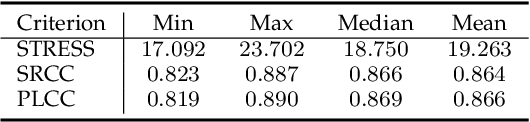

Measuring perceptual color differences (CDs) is of great importance in modern smartphone photography. Despite the long history, most CD measures have been constrained by psychophysical data of homogeneous color patches or a limited number of simplistic natural images. It is thus questionable whether existing CD measures generalize in the age of smartphone photography characterized by greater content complexities and learning-based image signal processors. In this paper, we put together so far the largest image dataset for perceptual CD assessment, in which the natural images are 1) captured by six flagship smartphones, 2) altered by Photoshop, 3) post-processed by built-in filters of the smartphones, and 4) reproduced with incorrect color profiles. We then conduct a large-scale psychophysical experiment to gather perceptual CDs of 30,000 image pairs in a carefully controlled laboratory environment. Based on the newly established dataset, we make one of the first attempts to construct an end-to-end learnable CD formula based on a lightweight neural network, as a generalization of several previous metrics. Extensive experiments demonstrate that the optimized formula outperforms 28 existing CD measures by a large margin, offers reasonable local CD maps without the use of dense supervision, generalizes well to color patch data, and empirically behaves as a proper metric in the mathematical sense.
Revisiting Random Channel Pruning for Neural Network Compression
May 11, 2022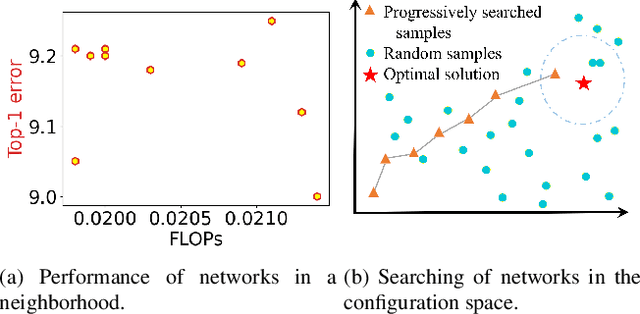
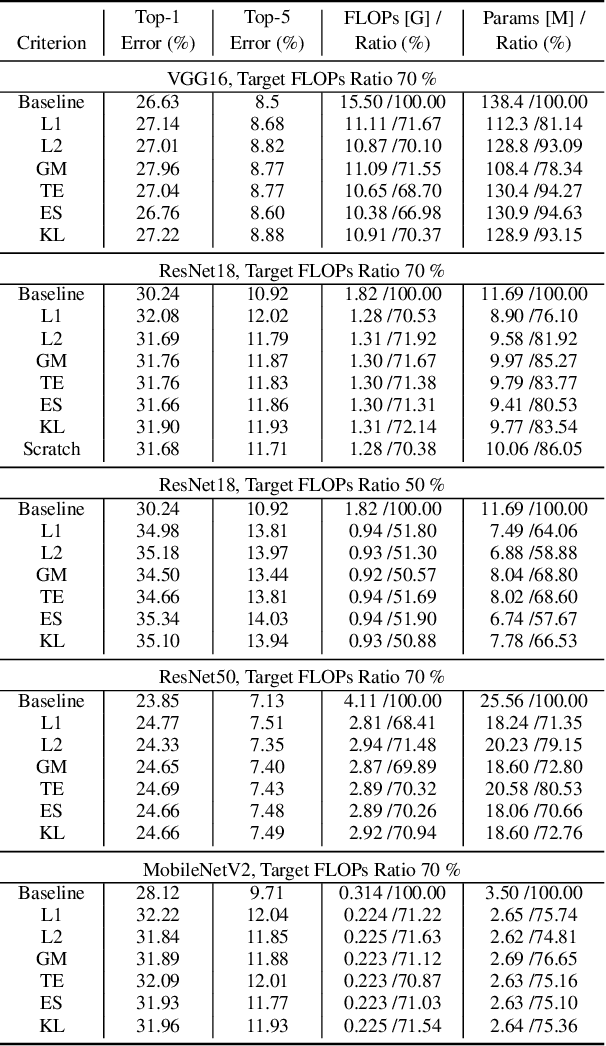
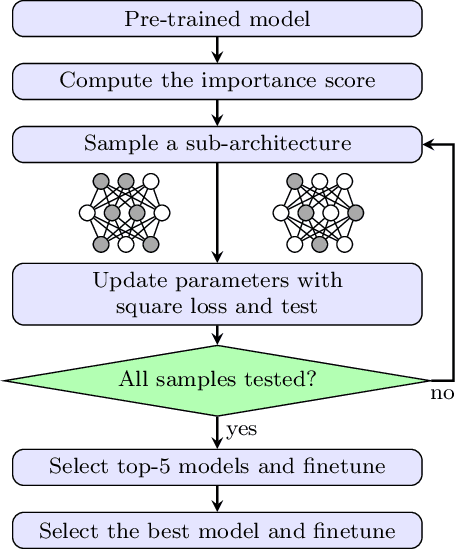
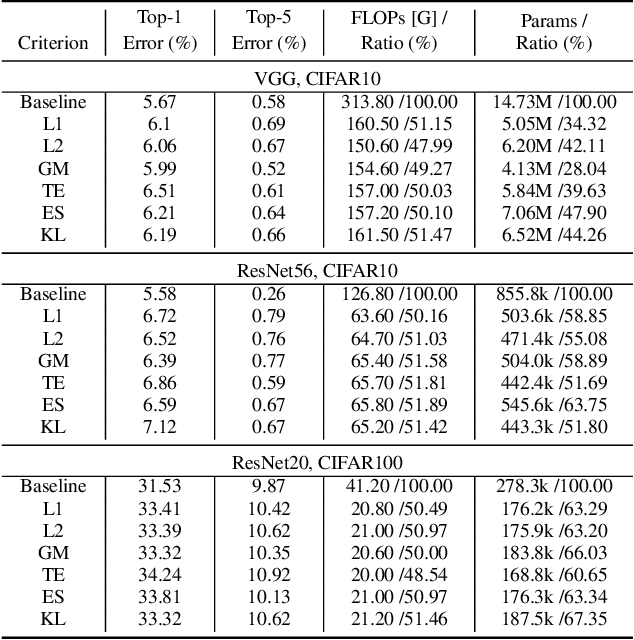
Channel (or 3D filter) pruning serves as an effective way to accelerate the inference of neural networks. There has been a flurry of algorithms that try to solve this practical problem, each being claimed effective in some ways. Yet, a benchmark to compare those algorithms directly is lacking, mainly due to the complexity of the algorithms and some custom settings such as the particular network configuration or training procedure. A fair benchmark is important for the further development of channel pruning. Meanwhile, recent investigations reveal that the channel configurations discovered by pruning algorithms are at least as important as the pre-trained weights. This gives channel pruning a new role, namely searching the optimal channel configuration. In this paper, we try to determine the channel configuration of the pruned models by random search. The proposed approach provides a new way to compare different methods, namely how well they behave compared with random pruning. We show that this simple strategy works quite well compared with other channel pruning methods. We also show that under this setting, there are surprisingly no clear winners among different channel importance evaluation methods, which then may tilt the research efforts into advanced channel configuration searching methods.