 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperDFlash: MHC-Aligned Block Speculative Decoding with Gated Residual Reduction
Jun 25, 2026We present HyperDFlash, a block-parallel speculative decoding framework tailored to the novel multi-hyper-connection (MHC) architecture proposed by DeepSeek-V4. Despite the strong initial-token drafting performance of the native Multi-Token Prediction (MTP) module in DeepSeek-V4, its draft accuracy degrades sharply at later positions, as error accumulation from unverified intermediate tokens harms acceptance rates. Although the original DFlash method supports efficient one-pass block drafting, it cannot be seamlessly adapted to the MHC paradigm, since the multi-path residual stream of DeepSeek-V4 induces feature misalignment with conventional drafting designs. To resolve this mismatch, we propose two model-aligned optimizations for MHC residual streams. First, we adopt pre-collapse residual states as the exclusive conditioning signal, preserving multi-path structural information and aligning the drafter with the native prediction pathway of the target model. Second, we replace the heavy generic linear compressor with a lightweight gated residual reducer, whose parameters are inherited from the built-in hyper-connection head. This design yields input-aware path aggregation with three orders of magnitude fewer parameters while maintaining architectural alignment. We further enhance training via a targeted KL distillation loss applied to the LM-head, which regularizes predictions against the full target probability distribution and improves draft quality at early training stages. Experiments across math reasoning, code synthesis, and conversational benchmarks show that HyperDFlash consistently outperforms both the native MTP baseline and vanilla DFlash adaptation. It achieves substantial gains in average accepted draft length and decoding speedup, validating the effectiveness of MHC alignment, gated reduction, and targeted distillation for high-performance speculative decoding.
EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices
Mar 28, 2025



Transformer-based large language models (LLMs) encounter challenges in processing long sequences on edge devices due to the quadratic complexity of attention mechanisms and growing memory demands from Key-Value (KV) cache. Existing KV cache optimizations struggle with irreversible token eviction in long-output tasks, while alternative sequence modeling architectures prove costly to adopt within established Transformer infrastructure. We present EdgeInfinite, a memory-efficient solution for infinite contexts that integrates compressed memory into Transformer-based LLMs through a trainable memory-gating module. This approach maintains full compatibility with standard Transformer architectures, requiring fine-tuning only a small part of parameters, and enables selective activation of the memory-gating module for long and short context task routing. The experimental result shows that EdgeInfinite achieves comparable performance to baseline Transformer-based LLM on long context benchmarks while optimizing memory consumption and time to first token.
One Filter to Deploy Them All: Robust Safety for Quadrupedal Navigation in Unknown Environments
Dec 13, 2024As learning-based methods for legged robots rapidly grow in popularity, it is important that we can provide safety assurances efficiently across different controllers and environments. Existing works either rely on a priori knowledge of the environment and safety constraints to ensure system safety or provide assurances for a specific locomotion policy. To address these limitations, we propose an observation-conditioned reachability-based (OCR) safety-filter framework. Our key idea is to use an OCR value network (OCR-VN) that predicts the optimal control-theoretic safety value function for new failure regions and dynamic uncertainty during deployment time. Specifically, the OCR-VN facilitates rapid safety adaptation through two key components: a LiDAR-based input that allows the dynamic construction of safe regions in light of new obstacles and a disturbance estimation module that accounts for dynamics uncertainty in the wild. The predicted safety value function is used to construct an adaptive safety filter that overrides the nominal quadruped controller when necessary to maintain safety. Through simulation studies and hardware experiments on a Unitree Go1 quadruped, we demonstrate that the proposed framework can automatically safeguard a wide range of hierarchical quadruped controllers, adapts to novel environments, and is robust to unmodeled dynamics without a priori access to the controllers or environments - hence, "One Filter to Deploy Them All". The experiment videos can be found on the project website.
FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization
Feb 28, 2024



Large language models (LLMs) have demonstrated state-of-the-art performance across various tasks. However, the latency of inference and the large GPU memory consumption of LLMs restrict their deployment performance. Recently, there have been some efficient attempts to quantize LLMs, yet inference with large batch size or long sequence still has the issue of being compute-bound. Fine-grained quantization methods have showcased their proficiency in achieving low-bit quantization for LLMs, while requiring FP16 data type for linear layer computations, which is time-consuming when dealing with large batch size or long sequence. In this paper, we introduce a method called FlattenQuant, which significantly reduces the maximum value of the tensor by flattening the large channels in the tensor, to achieve low bit per-tensor quantization with minimal accuracy loss. Our experiments show that FlattenQuant can directly use 4 bits to achieve 48.29% of the linear layer calculation in LLMs, with the remaining layers using 8 bits. The 4-bit matrix multiplication introduced in the FlattenQuant method can effectively address the compute-bound caused by large matrix calculation. Our work achieves up to 2$\times$ speedup and 2.3$\times$ memory reduction for LLMs with negligible loss in accuracy.
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Dec 11, 2023



Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Exploring Post-Training Quantization of Protein Language Models
Oct 30, 2023



Recent advancements in unsupervised protein language models (ProteinLMs), like ESM-1b and ESM-2, have shown promise in different protein prediction tasks. However, these models face challenges due to their high computational demands, significant memory needs, and latency, restricting their usage on devices with limited resources. To tackle this, we explore post-training quantization (PTQ) for ProteinLMs, focusing on ESMFold, a simplified version of AlphaFold based on ESM-2 ProteinLM. Our study is the first attempt to quantize all weights and activations of ProteinLMs. We observed that the typical uniform quantization method performs poorly on ESMFold, causing a significant drop in TM-Score when using 8-bit quantization. We conducted extensive quantization experiments, uncovering unique challenges associated with ESMFold, particularly highly asymmetric activation ranges before Layer Normalization, making representation difficult using low-bit fixed-point formats. To address these challenges, we propose a new PTQ method for ProteinLMs, utilizing piecewise linear quantization for asymmetric activation values to ensure accurate approximation. We demonstrated the effectiveness of our method in protein structure prediction tasks, demonstrating that ESMFold can be accurately quantized to low-bit widths without compromising accuracy. Additionally, we applied our method to the contact prediction task, showcasing its versatility. In summary, our study introduces an innovative PTQ method for ProteinLMs, addressing specific quantization challenges and potentially leading to the development of more efficient ProteinLMs with significant implications for various protein-related applications.
Hamilton-Jacobi Reachability Analysis for Hybrid Systems with Controlled and Forced Transitions
Sep 19, 2023Hybrid dynamical systems with non-linear dynamics are one of the most general modeling tools for representing robotic systems, especially contact-rich systems. However, providing guarantees regarding the safety or performance of such hybrid systems can still prove to be a challenging problem because it requires simultaneous reasoning about continuous state evolution and discrete mode switching. In this work, we address this problem by extending classical Hamilton-Jacobi (HJ) reachability analysis, a formal verification method for continuous non-linear dynamics in the presence of bounded inputs and disturbances, to hybrid dynamical systems. Our framework can compute reachable sets for hybrid systems consisting of multiple discrete modes, each with its own set of non-linear continuous dynamics, discrete transitions that can be directly commanded or forced by a discrete control input, while still accounting for control bounds and adversarial disturbances in the state evolution. Along with the reachable set, the proposed framework also provides an optimal continuous and discrete controller to ensure system safety. We demonstrate our framework in simulation on an aircraft collision avoidance problem, as well as on a real-world testbed to solve the optimal mode planning problem for a quadruped with multiple gaits.
Self-Reconfigurable Soft-Rigid Mobile Agent with Variable Stiffness and Adaptive Morphology
Oct 16, 2022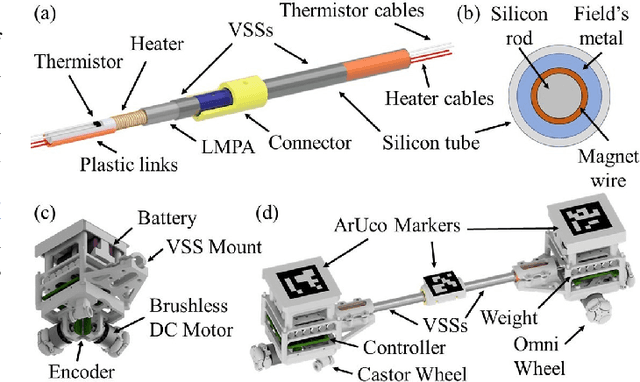
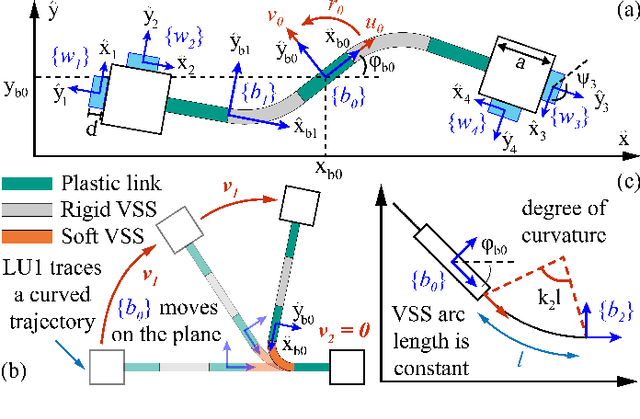
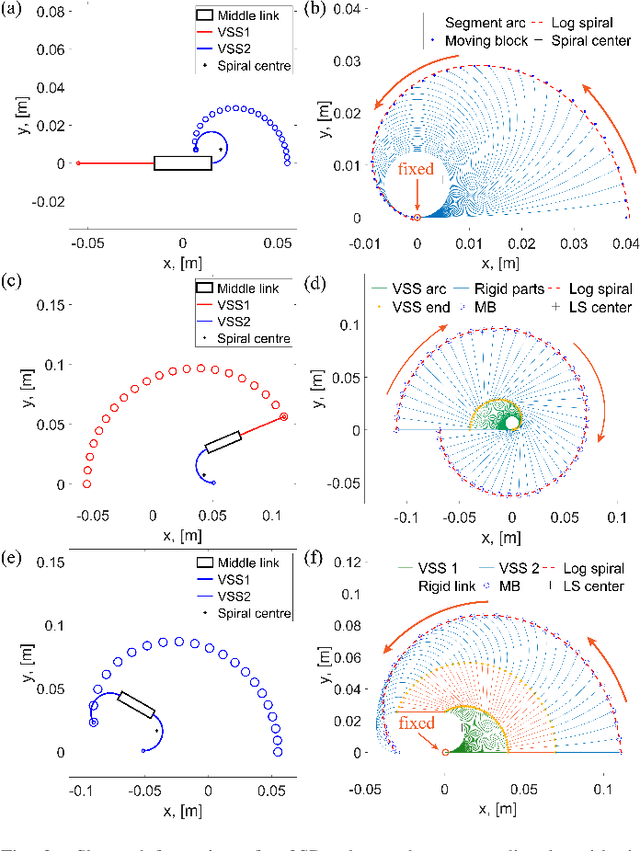
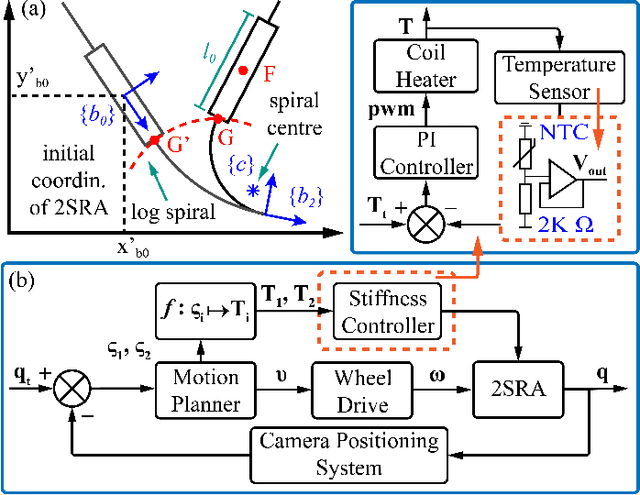
In this paper, we propose a novel design of a hybrid mobile robot with controllable stiffness and deformable shape. Compared to conventional mobile agents, our system can switch between rigid and compliant phases by solidifying or melting Field's metal in its structure and, thus, alter its shape through the motion of its active components. In the soft state, the robot's main body can bend into circular arcs, which enables it to conform to surrounding curved objects. This variable geometry of the robot creates new motion modes which cannot be described by standard (i.e., fixed geometry) models. To this end, we develop a unified mathematical model that captures the differential kinematics of both rigid and soft states. An optimised control strategy is further proposed to select the most appropriate phase states and motion modes needed to reach a target pose-shape configuration. The performance of our new method is validated with numerical simulations and experiments conducted on a prototype system. The simulation source code is available at https://github.com/Louashka/2sr-agent-simulation.git}{GitHub repository.
AdaCoach: A Virtual Coach for Training Customer Service Agents
Apr 27, 2022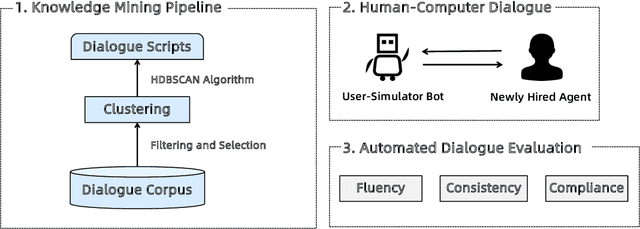
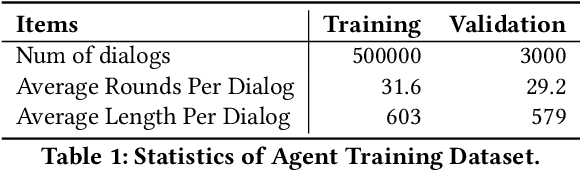
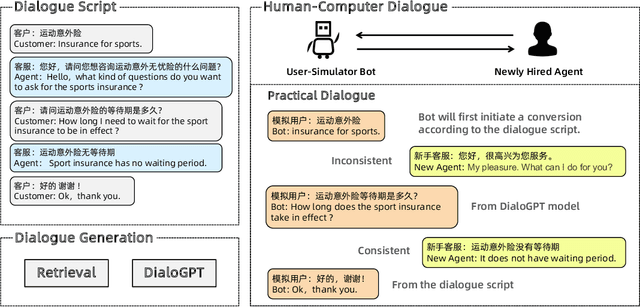

With the development of online business, customer service agents gradually play a crucial role as an interface between the companies and their customers. Most companies spend a lot of time and effort on hiring and training customer service agents. To this end, we propose AdaCoach: A Virtual Coach for Training Customer Service Agents, to promote the ability of newly hired service agents before they get to work. AdaCoach is designed to simulate real customers who seek help and actively initiate the dialogue with the customer service agents. Besides, AdaCoach uses an automated dialogue evaluation model to score the performance of the customer agent in the training process, which can provide necessary assistance when the newly hired customer service agent encounters problems. We apply recent NLP technologies to ensure efficient run-time performance in the deployed system. To the best of our knowledge, this is the first system that trains the customer service agent through human-computer interaction. Until now, the system has already supported more than 500,000 simulation training and cultivated over 1000 qualified customer service agents.
Towards Generalized Models for Task-oriented Dialogue Modeling on Spoken Conversations
Mar 08, 2022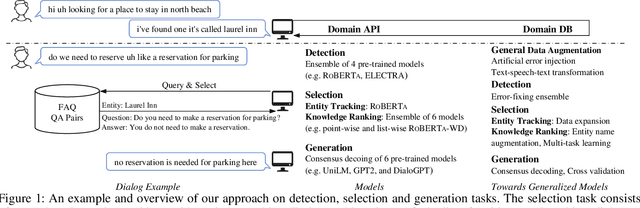


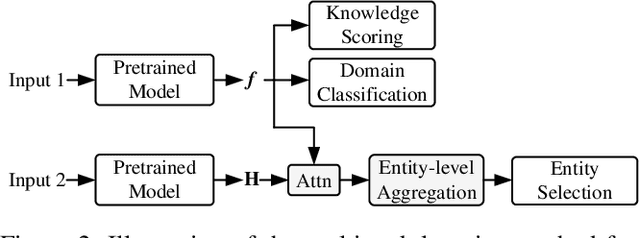
Building robust and general dialogue models for spoken conversations is challenging due to the gap in distributions of spoken and written data. This paper presents our approach to build generalized models for the Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations Challenge of DSTC-10. In order to mitigate the discrepancies between spoken and written text, we mainly employ extensive data augmentation strategies on written data, including artificial error injection and round-trip text-speech transformation. To train robust models for spoken conversations, we improve pre-trained language models, and apply ensemble algorithms for each sub-task. Typically, for the detection task, we fine-tune \roberta and ELECTRA, and run an error-fixing ensemble algorithm. For the selection task, we adopt a two-stage framework that consists of entity tracking and knowledge ranking, and propose a multi-task learning method to learn multi-level semantic information by domain classification and entity selection. For the generation task, we adopt a cross-validation data process to improve pre-trained generative language models, followed by a consensus decoding algorithm, which can add arbitrary features like relative \rouge metric, and tune associated feature weights toward \bleu directly. Our approach ranks third on the objective evaluation and second on the final official human evaluation.