 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Apr 22, 2026Robotic autonomy in open-world environments is fundamentally limited by insufficient data diversity and poor cross-embodiment generalization. Existing robotic datasets are often limited in scale and task coverage, while relatively large differences across robot embodiments impede effective behavior knowledge transfer. To address these challenges, we propose JoyAI-RA, a vision-language-action (VLA) embodied foundation model tailored for generalizable robotic manipulation. JoyAI-RA presents a multi-source multi-level pretraining framework that integrates web data, large-scale egocentric human manipulation videos, simulation-generated trajectories, and real-robot data. Through training on heterogeneous multi-source data with explicit action-space unification, JoyAI-RA effectively bridges embodiment gaps, particularly between human manipulation and robotic control, thereby enhancing cross-embodiment behavior learning. JoyAI-RA outperforms state-of-the-art methods in both simulation and real-world benchmarks, especially on diverse tasks with generalization demands.
Validating Computational Markers of Depressive Behavior: Cross-Linguistic Speech-Based Depression Detection with Neurophysiological Validation
Apr 02, 2026Speech-based depression detection has shown promise as an objective diagnostic tool, yet the cross-linguistic robustness of acoustic markers and their neurobiological underpinnings remain underexplored. This study extends Cross-Data Multilevel Attention (CDMA) framework, initially validated on Italian, to investigate these dimensions using a Chinese Mandarin dataset with Electroencephalography (EEG) recordings. We systematically fuse read speech with spontaneous speech across different emotional valences (positive, neutral, negative) to investigate whether emotional arousal is a more critical factor than valence polarity in enhancing detection performance in speech. Additionally, we establish the first neurophysiological validation for a speech-based depression model by correlating its predictions with neural oscillatory patterns during emotional face processing. Our results demonstrate strong cross-linguistic generalizability of the CDMA framework, achieving state-of-the-art performance (F1-score up to 89.6%) on the Chinese dataset, which is comparable to the previous Italian validation. Critically, emotionally valenced speech (both positive and negative) significantly outperformed neutral speech. This comparable performance between positive and negative tasks supports the emotional arousal hypothesis. Most importantly, EEG analysis revealed significant correlations between the model's speech-derived depression estimates and neural oscillatory patterns (theta and alpha bands), demonstrating alignment with established neural markers of emotional dysregulation in depression. This alignment, combined with the model's cross-linguistic robustness, not only supports that the CDMA framework's approach is a universally applicable and neurobiologically validated strategy but also establishes a novel paradigm for the neurophysiological validation of computational mental health models.
Cutting the Unnecessary Long Tail: Cost-Effective Big Data Clustering in the Cloud
Sep 22, 2019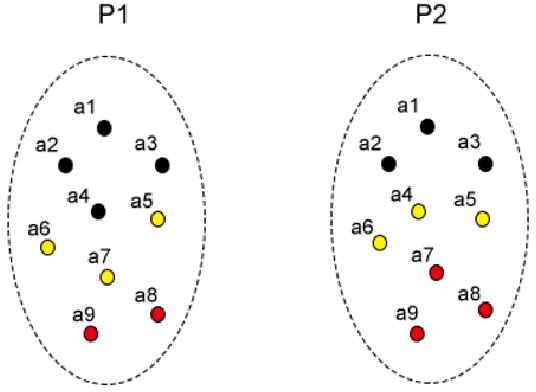
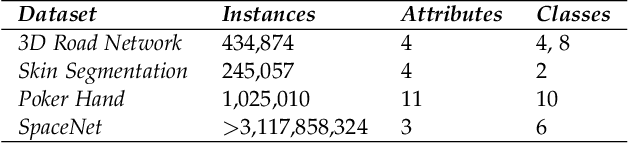
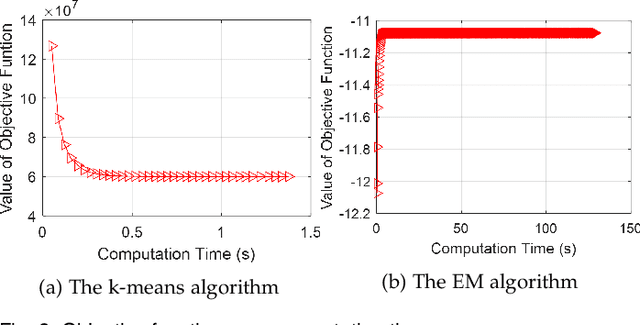

Clustering big data often requires tremendous computational resources where cloud computing is undoubtedly one of the promising solutions. However, the computation cost in the cloud can be unexpectedly high if it cannot be managed properly. The long tail phenomenon has been observed widely in the big data clustering area, which indicates that the majority of time is often consumed in the middle to late stages in the clustering process. In this research, we try to cut the unnecessary long tail in the clustering process to achieve a sufficiently satisfactory accuracy at the lowest possible computation cost. A novel approach is proposed to achieve cost-effective big data clustering in the cloud. By training the regression model with the sampling data, we can make widely used k-means and EM (Expectation-Maximization) algorithms stop automatically at an early point when the desired accuracy is obtained. Experiments are conducted on four popular data sets and the results demonstrate that both k-means and EM algorithms can achieve high cost-effectiveness in the cloud with our proposed approach. For example, in the case studies with the much more efficient k-means algorithm, we find that achieving a 99% accuracy needs only 47.71%-71.14% of the computation cost required for achieving a 100% accuracy while the less efficient EM algorithm needs 16.69%-32.04% of the computation cost. To put that into perspective, in the United States land use classification example, our approach can save up to $94,687.49 for the government in each use.