 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Local-peak scale-invariant feature transform for fast and random image stitching
May 14, 2024



Image stitching aims to construct a wide field of view with high spatial resolution, which cannot be achieved in a single exposure. Typically, conventional image stitching techniques, other than deep learning, require complex computation and thus computational pricy, especially for stitching large raw images. In this study, inspired by the multiscale feature of fluid turbulence, we developed a fast feature point detection algorithm named local-peak scale-invariant feature transform (LP-SIFT), based on the multiscale local peaks and scale-invariant feature transform method. By combining LP-SIFT and RANSAC in image stitching, the stitching speed can be improved by orders, compared with the original SIFT method. Nine large images (over 2600*1600 pixels), arranged randomly without prior knowledge, can be stitched within 158.94 s. The algorithm is highly practical for applications requiring a wide field of view in diverse application scenes, e.g., terrain mapping, biological analysis, and even criminal investigation.
PTA-Det: Point Transformer Associating Point cloud and Image for 3D Object Detection
Jan 18, 2023



In autonomous driving, 3D object detection based on multi-modal data has become an indispensable approach when facing complex environments around the vehicle. During multi-modal detection, LiDAR and camera are simultaneously applied for capturing and modeling. However, due to the intrinsic discrepancies between the LiDAR point and camera image, the fusion of the data for object detection encounters a series of problems. Most multi-modal detection methods perform even worse than LiDAR-only methods. In this investigation, we propose a method named PTA-Det to improve the performance of multi-modal detection. Accompanied by PTA-Det, a Pseudo Point Cloud Generation Network is proposed, which can convert image information including texture and semantic features by pseudo points. Thereafter, through a transformer-based Point Fusion Transition (PFT) module, the features of LiDAR points and pseudo points from image can be deeply fused under a unified point-based representation. The combination of these modules can conquer the major obstacle in feature fusion across modalities and realizes a complementary and discriminative representation for proposal generation. Extensive experiments on the KITTI dataset show the PTA-Det achieves a competitive result and support its effectiveness.
Super-resolution reconstruction of cytoskeleton image based on A-net deep learning network
Dec 17, 2021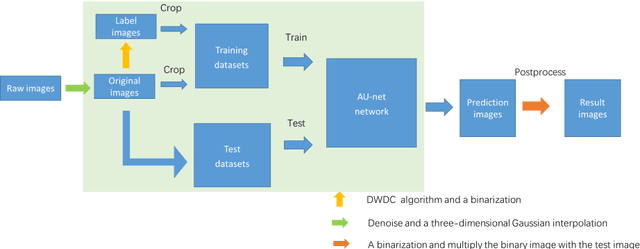
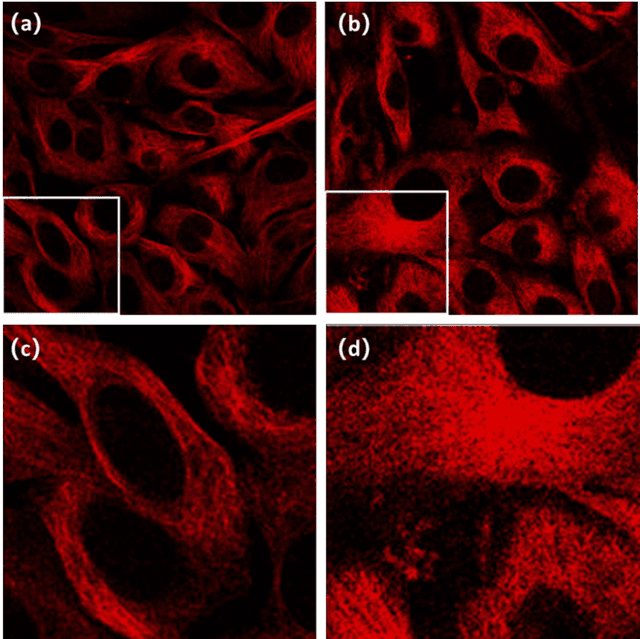
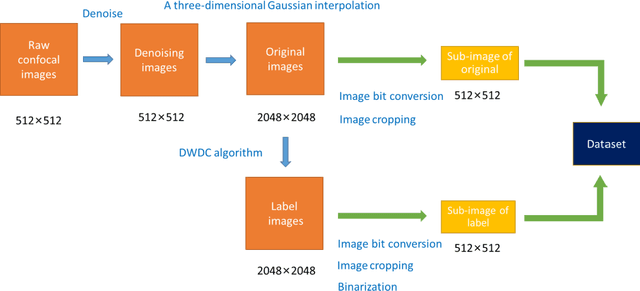
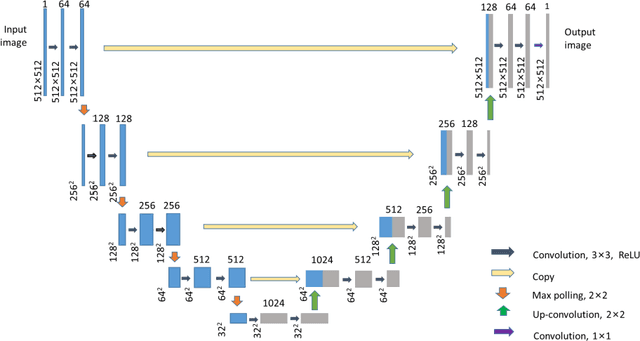
To date, live-cell imaging at the nanometer scale remains challenging. Even though super-resolution microscopy methods have enabled visualization of subcellular structures below the optical resolution limit, the spatial resolution is still far from enough for the structural reconstruction of biomolecules in vivo (i.e. ~24 nm thickness of microtubule fiber). In this study, we proposed an A-net network and showed that the resolution of cytoskeleton images captured by a confocal microscope can be significantly improved by combining the A-net deep learning network with the DWDC algorithm based on degradation model. Utilizing the DWDC algorithm to construct new datasets and taking advantage of A-net neural network's features (i.e., considerably fewer layers), we successfully removed the noise and flocculent structures, which originally interfere with the cellular structure in the raw image, and improved the spatial resolution by 10 times using relatively small dataset. We, therefore, conclude that the proposed algorithm that combines A-net neural network with the DWDC method is a suitable and universal approach for exacting structural details of biomolecules, cells and organs from low-resolution images.