 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing
Mar 06, 2019
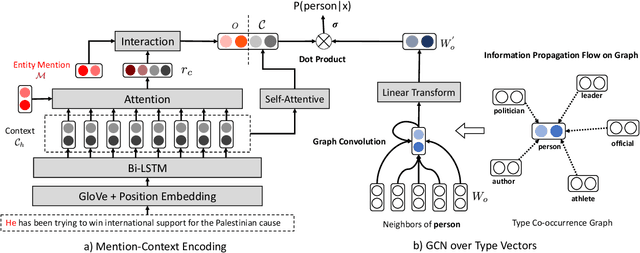
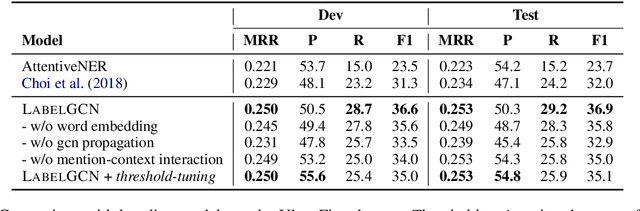
Existing entity typing systems usually exploit the type hierarchy provided by knowledge base (KB) schema to model label correlations and thus improve the overall performance. Such techniques, however, are not directly applicable to more open and practical scenarios where the type set is not restricted by KB schema and includes a vast number of free-form types. To model the underly-ing label correlations without access to manually annotated label structures, we introduce a novel label-relational inductive bias, represented by a graph propagation layer that effectively encodes both global label co-occurrence statistics and word-level similarities.On a large dataset with over 10,000 free-form types, the graph-enhanced model equipped with an attention-based matching module is able to achieve a much higher recall score while maintaining a high-level precision. Specifically, it achieves a 15.3% relative F1 improvement and also less inconsistency in the outputs. We further show that a simple modification of our proposed graph layer can also improve the performance on a conventional and widely-tested dataset that only includes KB-schema types.
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Feb 04, 2019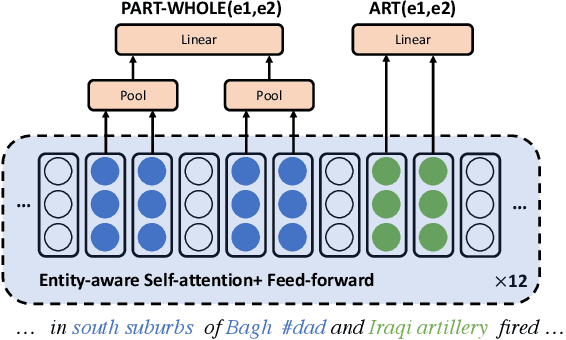
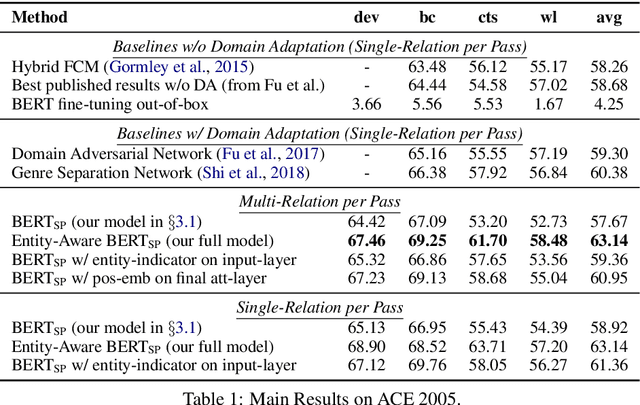

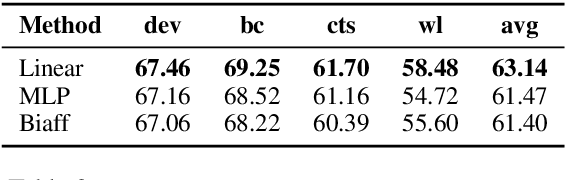
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
Revisiting Pre-training: An Efficient Training Method for Image Classification
Nov 23, 2018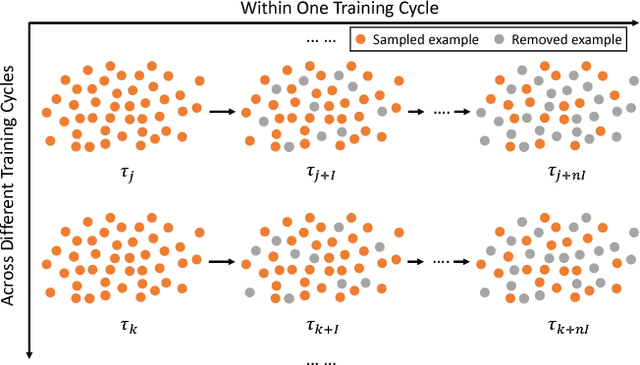

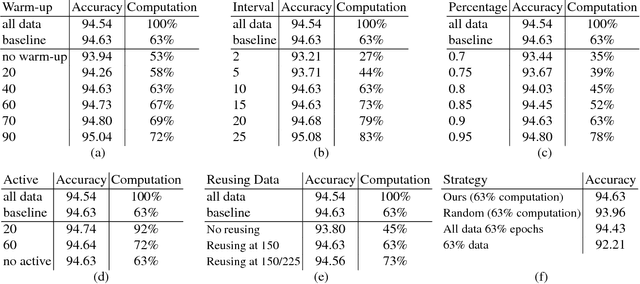

The training method of repetitively feeding all samples into a pre-defined network for image classification has been widely adopted by current state-of-the-art. In this work, we provide a new method, which can be leveraged to train classification networks in a more efficient way. Starting with a warm-up step, we propose to continually repeat a Drop-and-Pick (DaP) learning strategy. In particular, we drop those easy samples to encourage the network to focus on studying hard ones. Meanwhile, by picking up all samples periodically during training, we aim to recall the memory of the networks to prevent catastrophic forgetting of previously learned knowledge. Our DaP learning method can recover 99.88%, 99.60%, 99.83% top-1 accuracy on ImageNet for ResNet-50, DenseNet-121, and MobileNet-V1 but only requires 75% computation in training compared to those using the classic training schedule. Furthermore, our pre-trained models are equipped with strong knowledge transferability when used for downstream tasks, especially for hard cases. Extensive experiments on object detection, instance segmentation and pose estimation can well demonstrate the effectiveness of our DaP training method.
Improving Reinforcement Learning Based Image Captioning with Natural Language Prior
Sep 13, 2018

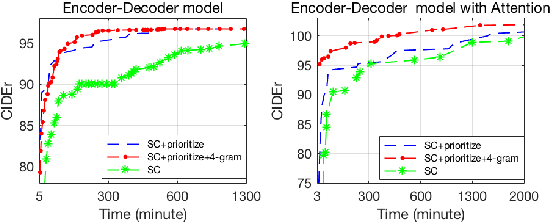
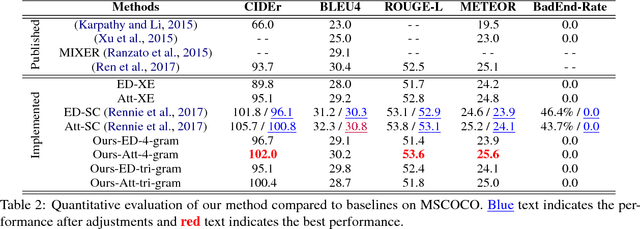
Recently, Reinforcement Learning (RL) approaches have demonstrated advanced performance in image captioning by directly optimizing the metric used for testing. However, this shaped reward introduces learning biases, which reduces the readability of generated text. In addition, the large sample space makes training unstable and slow. To alleviate these issues, we propose a simple coherent solution that constrains the action space using an n-gram language prior. Quantitative and qualitative evaluations on benchmarks show that RL with the simple add-on module performs favorably against its counterpart in terms of both readability and speed of convergence. Human evaluation results show that our model is more human readable and graceful. The implementation will become publicly available upon the acceptance of the paper.
Deriving Machine Attention from Human Rationales
Aug 28, 2018
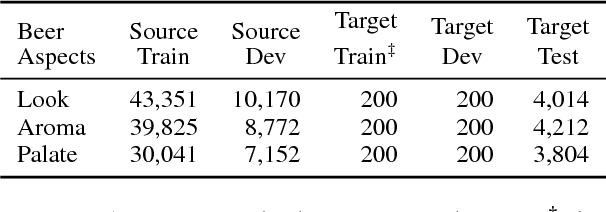
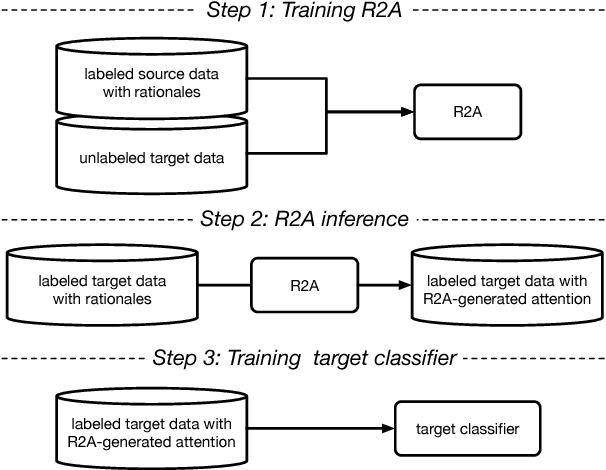
Attention-based models are successful when trained on large amounts of data. In this paper, we demonstrate that even in the low-resource scenario, attention can be learned effectively. To this end, we start with discrete human-annotated rationales and map them into continuous attention. Our central hypothesis is that this mapping is general across domains, and thus can be transferred from resource-rich domains to low-resource ones. Our model jointly learns a domain-invariant representation and induces the desired mapping between rationales and attention. Our empirical results validate this hypothesis and show that our approach delivers significant gains over state-of-the-art baselines, yielding over 15% average error reduction on benchmark datasets.
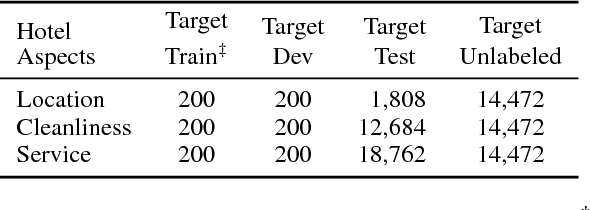
One-Shot Relational Learning for Knowledge Graphs
Aug 27, 2018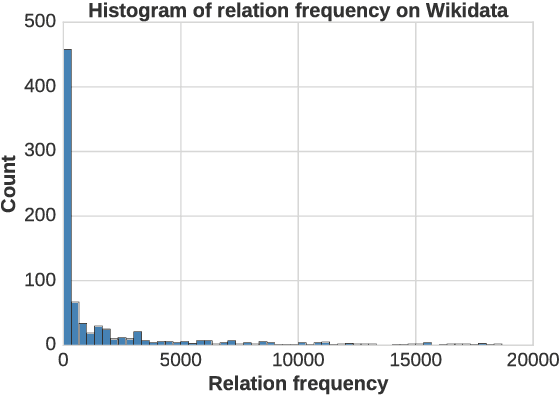
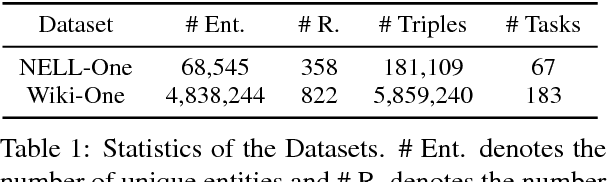
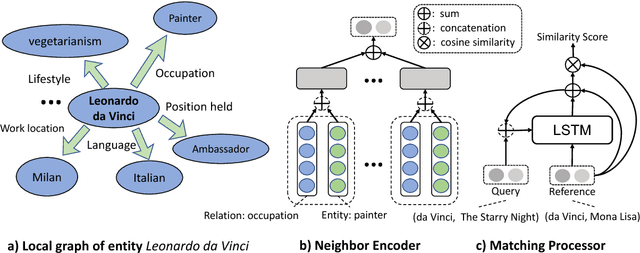
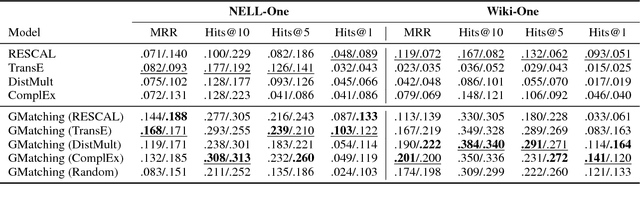
Knowledge graphs (KGs) are the key components of various natural language processing applications. To further expand KGs' coverage, previous studies on knowledge graph completion usually require a large number of training instances for each relation. However, we observe that long-tail relations are actually more common in KGs and those newly added relations often do not have many known triples for training. In this work, we aim at predicting new facts under a challenging setting where only one training instance is available. We propose a one-shot relational learning framework, which utilizes the knowledge extracted by embedding models and learns a matching metric by considering both the learned embeddings and one-hop graph structures. Empirically, our model yields considerable performance improvements over existing embedding models, and also eliminates the need of re-training the embedding models when dealing with newly added relations.
Matrix Factorization on GPUs with Memory Optimization and Approximate Computing
Aug 11, 2018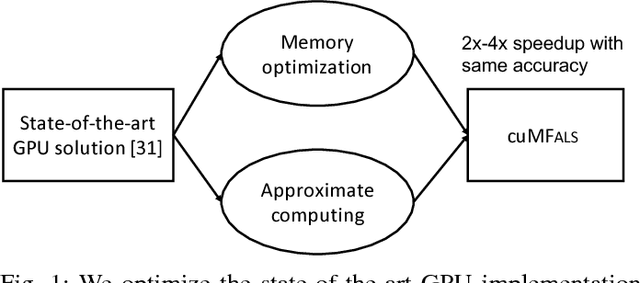
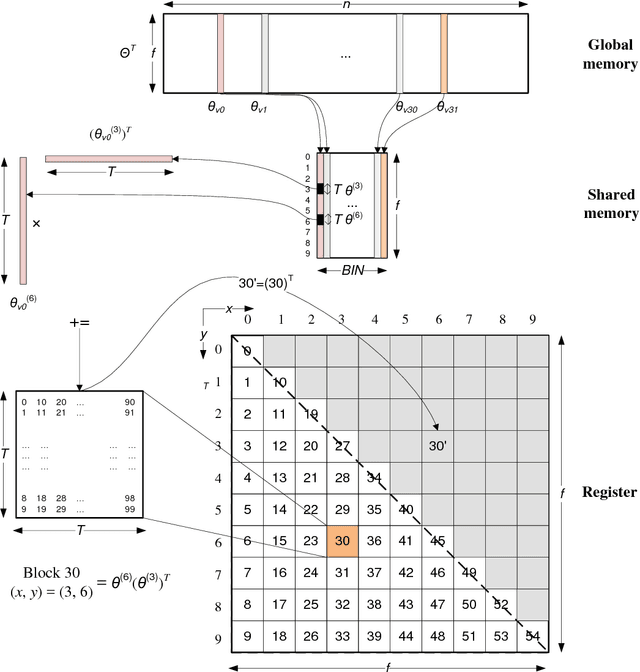
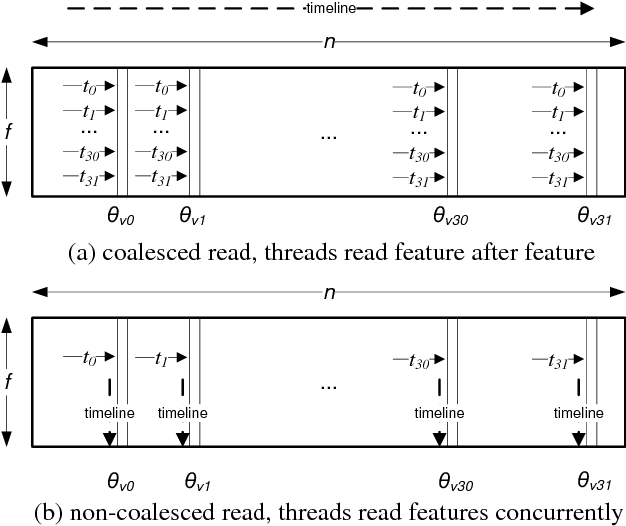
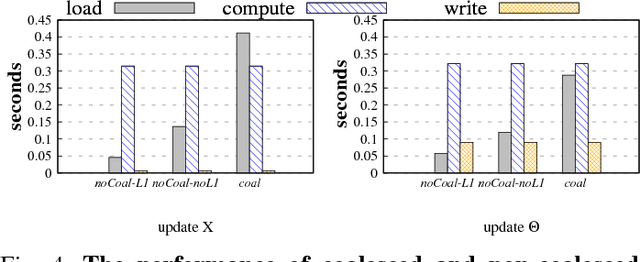
Matrix factorization (MF) discovers latent features from observations, which has shown great promises in the fields of collaborative filtering, data compression, feature extraction, word embedding, etc. While many problem-specific optimization techniques have been proposed, alternating least square (ALS) remains popular due to its general applicability e.g. easy to handle positive-unlabeled inputs, fast convergence and parallelization capability. Current MF implementations are either optimized for a single machine or with a need of a large computer cluster but still are insufficient. This is because a single machine provides limited compute power for large-scale data while multiple machines suffer from the network communication bottleneck. To address the aforementioned challenge, accelerating ALS on graphics processing units (GPUs) is a promising direction. We propose the novel approach in enhancing the MF efficiency via both memory optimization and approximate computing. The former exploits GPU memory hierarchy to increase data reuse, while the later reduces unnecessary computing without hurting the convergence of learning algorithms. Extensive experiments on large-scale datasets show that our solution not only outperforms the competing CPU solutions by a large margin but also has a 2x-4x performance gain compared to the state-of-the-art GPU solutions. Our implementations are open-sourced and publicly available.
Scheduled Policy Optimization for Natural Language Communication with Intelligent Agents
Jul 07, 2018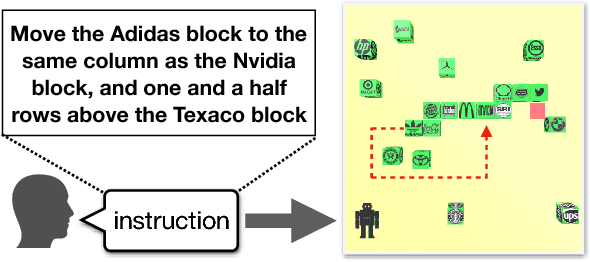
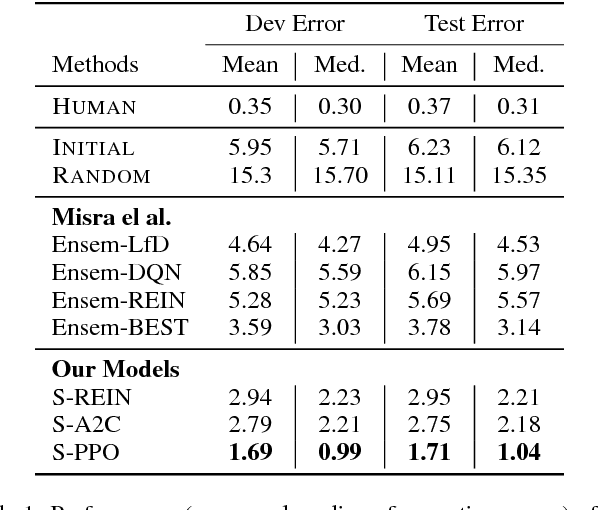
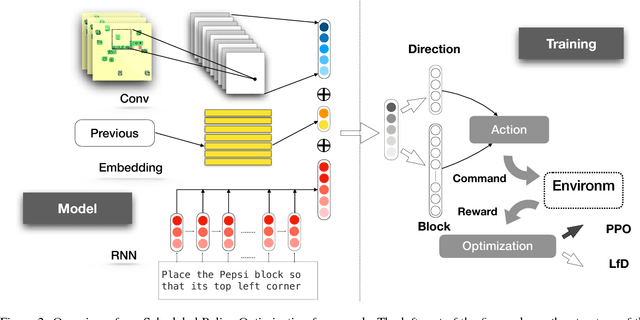
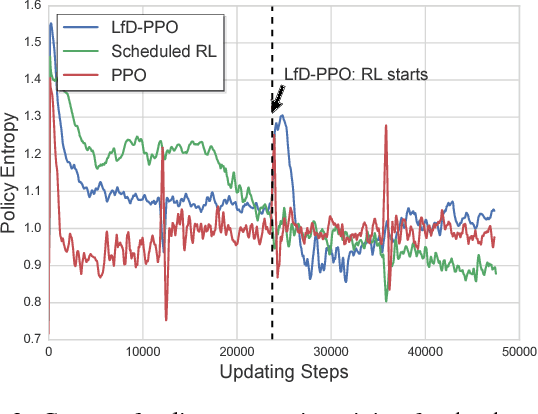
We investigate the task of learning to follow natural language instructions by jointly reasoning with visual observations and language inputs. In contrast to existing methods which start with learning from demonstrations (LfD) and then use reinforcement learning (RL) to fine-tune the model parameters, we propose a novel policy optimization algorithm which dynamically schedules demonstration learning and RL. The proposed training paradigm provides efficient exploration and better generalization beyond existing methods. Comparing to existing ensemble models, the best single model based on our proposed method tremendously decreases the execution error by over 50% on a block-world environment. To further illustrate the exploration strategy of our RL algorithm, We also include systematic studies on the evolution of policy entropy during training.
A Co-Matching Model for Multi-choice Reading Comprehension
Jun 11, 2018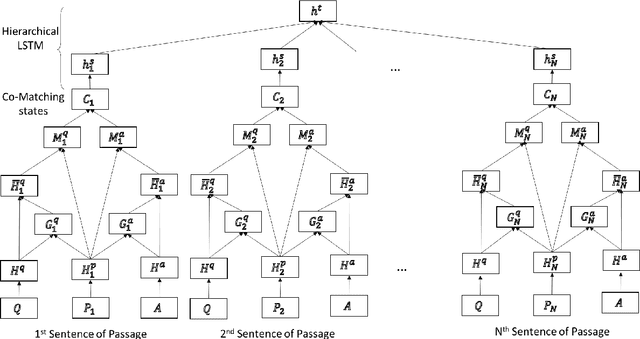
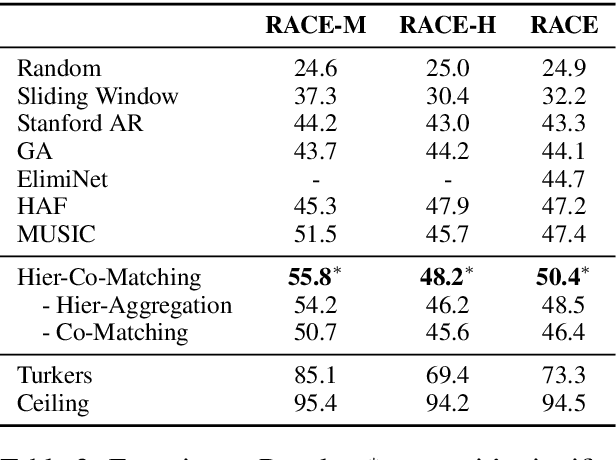
Multi-choice reading comprehension is a challenging task, which involves the matching between a passage and a question-answer pair. This paper proposes a new co-matching approach to this problem, which jointly models whether a passage can match both a question and a candidate answer. Experimental results on the RACE dataset demonstrate that our approach achieves state-of-the-art performance.
Zeroth-Order Stochastic Variance Reduction for Nonconvex Optimization
Jun 07, 2018
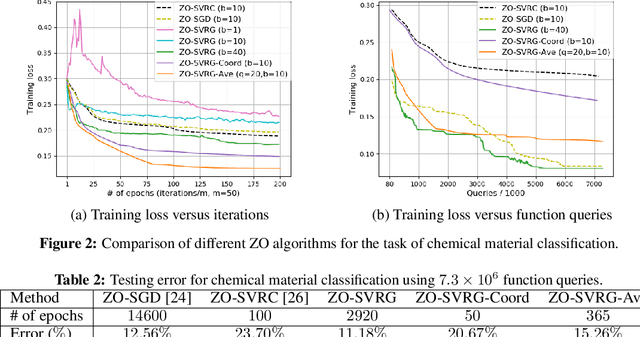
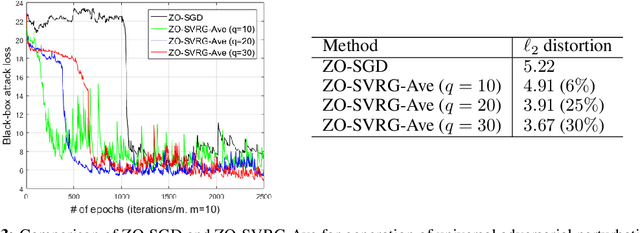
As application demands for zeroth-order (gradient-free) optimization accelerate, the need for variance reduced and faster converging approaches is also intensifying. This paper addresses these challenges by presenting: a) a comprehensive theoretical analysis of variance reduced zeroth-order (ZO) optimization, b) a novel variance reduced ZO algorithm, called ZO-SVRG, and c) an experimental evaluation of our approach in the context of two compelling applications, black-box chemical material classification and generation of adversarial examples from black-box deep neural network models. Our theoretical analysis uncovers an essential difficulty in the analysis of ZO-SVRG: the unbiased assumption on gradient estimates no longer holds. We prove that compared to its first-order counterpart, ZO-SVRG with a two-point random gradient estimator could suffer an additional error of order $O(1/b)$, where $b$ is the mini-batch size. To mitigate this error, we propose two accelerated versions of ZO-SVRG utilizing variance reduced gradient estimators, which achieve the best rate known for ZO stochastic optimization (in terms of iterations). Our extensive experimental results show that our approaches outperform other state-of-the-art ZO algorithms, and strike a balance between the convergence rate and the function query complexity.